
第1部分 向HTTP/2靠拢
第1章 万维网与HTTP
1.1 万维网的原理
1.1.1 因特网与万维网
因特网是使用IP(Internet Protocol,因特网协议)连接在一起实现消息传递的计算机构成的网络。因特网上有很多服务,包括万维网,万维网只是因特网上的一种服务形式。
1.1.2 打开网页时会发生什么
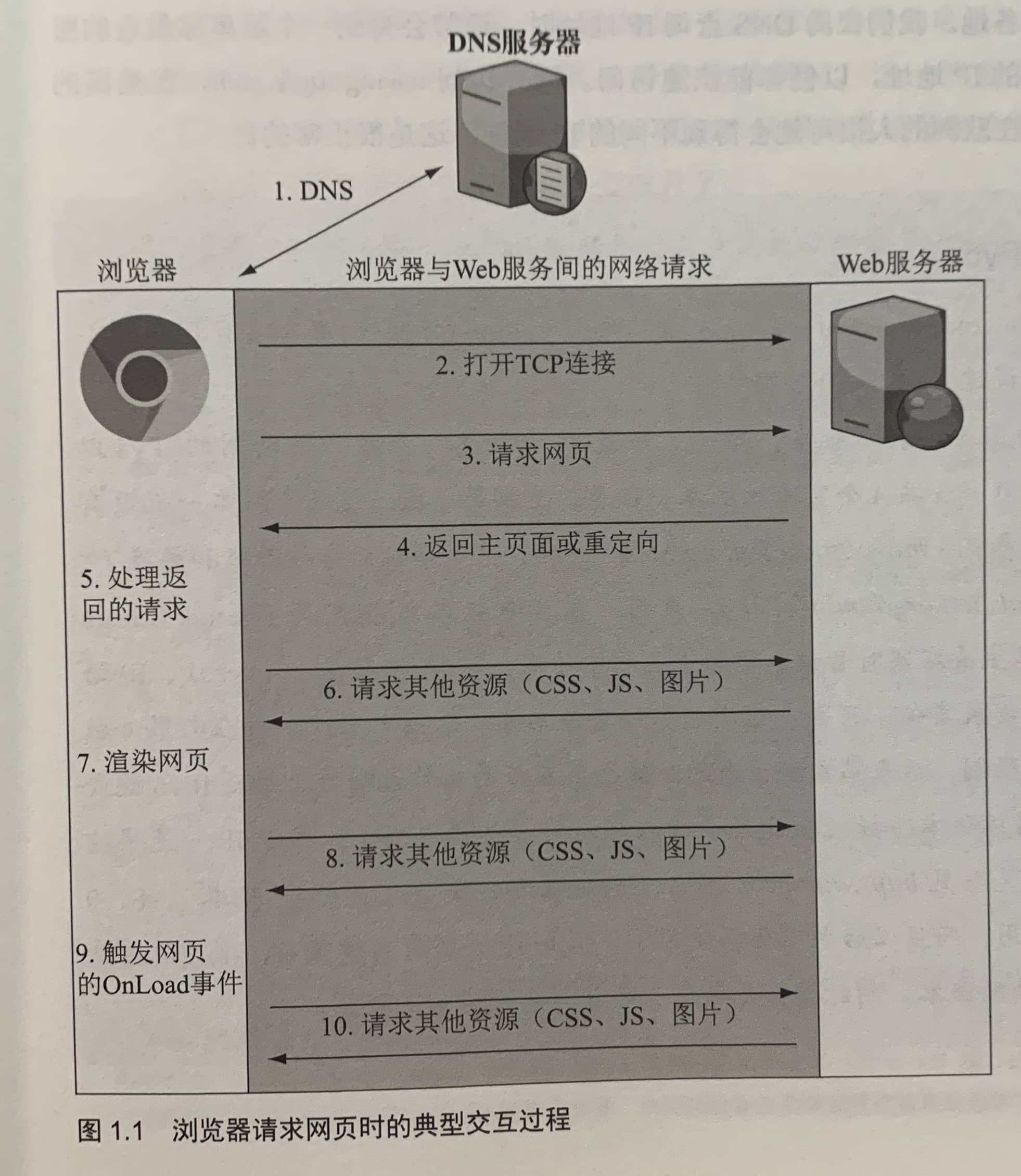
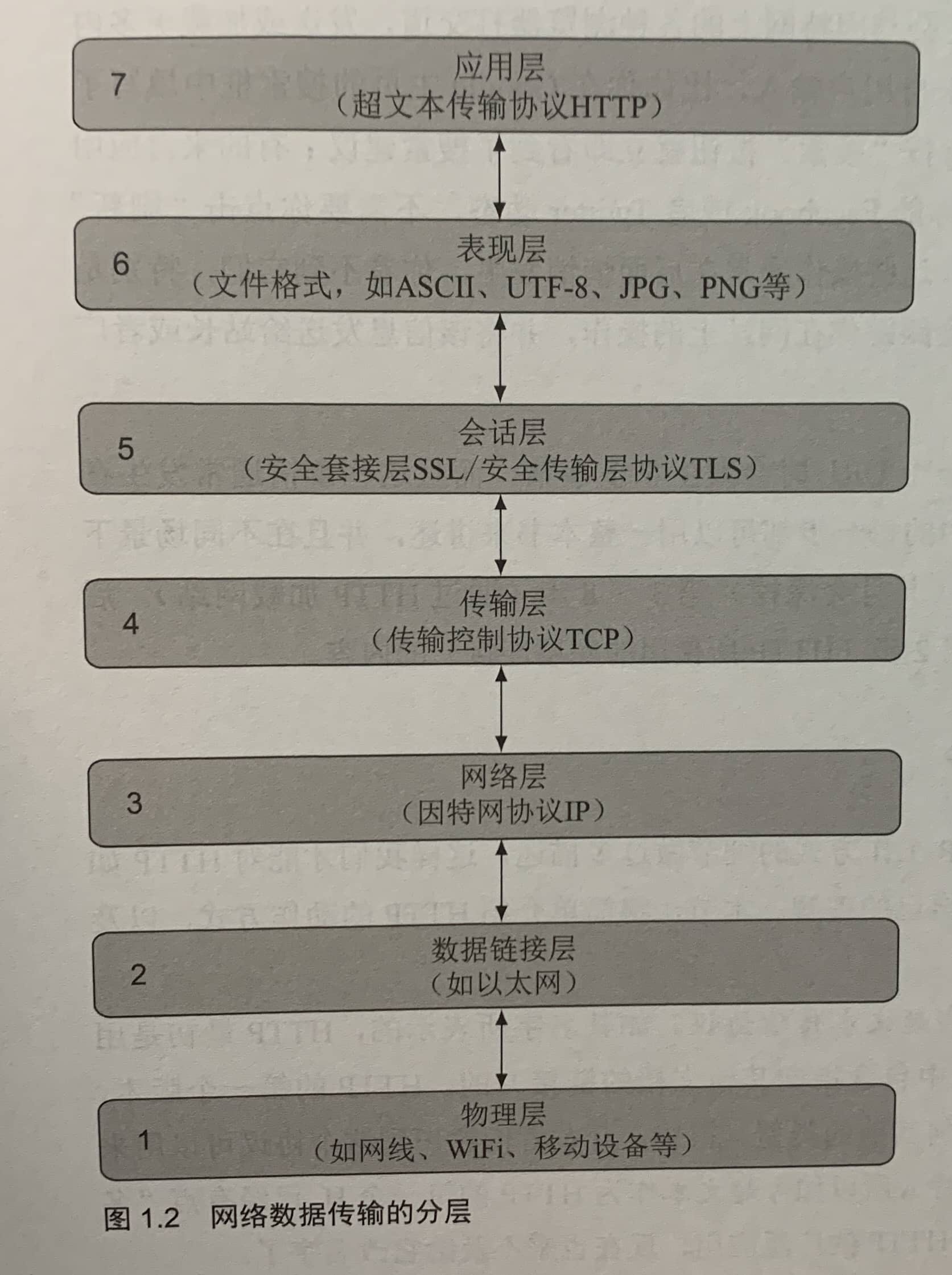
1.2 什么是HTTP
OSI(Open System Interconnection,开放系统互联通信参考模型)七层。
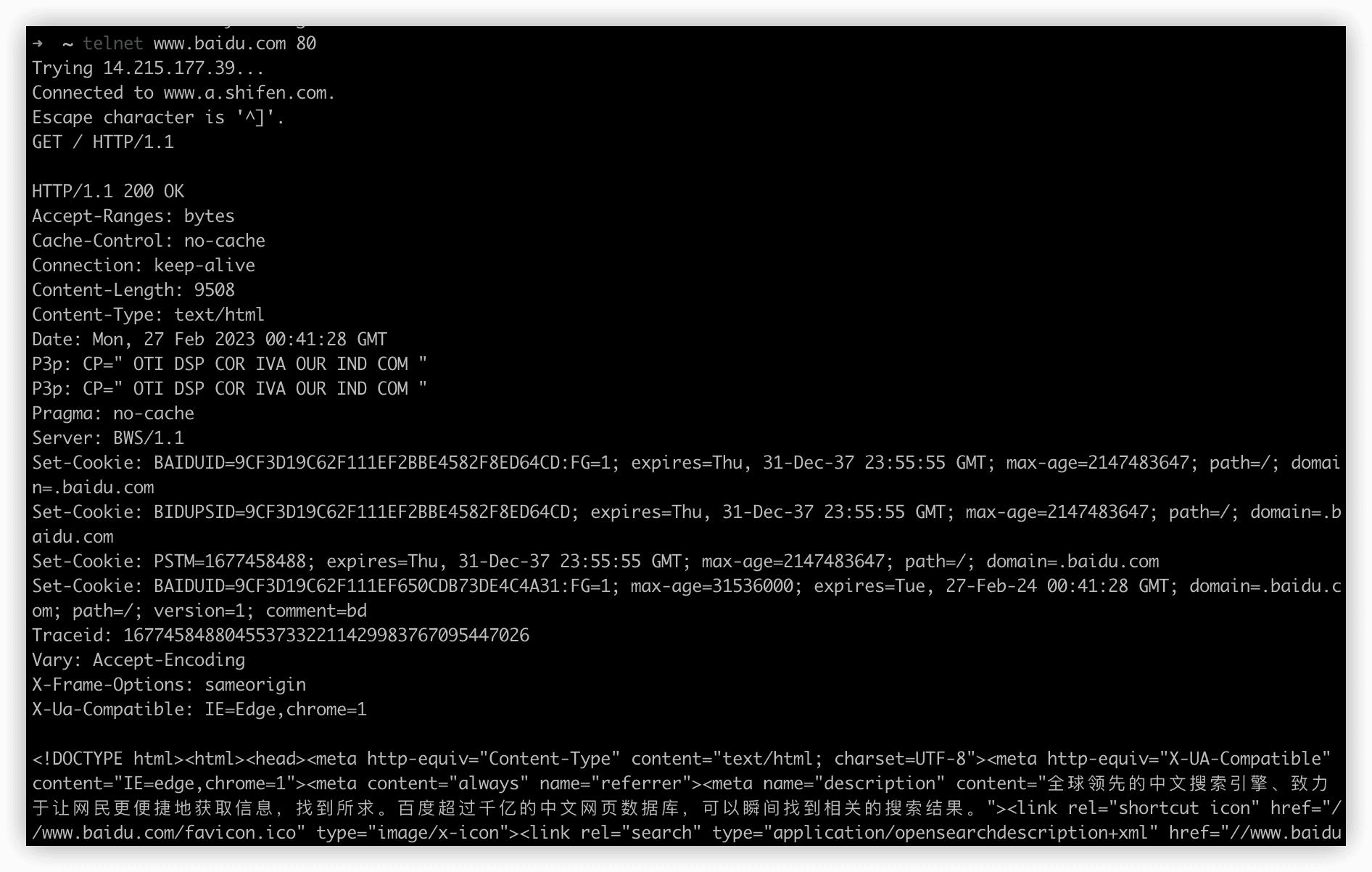
Telnet是一种用于远程访问计算机网络设备的协议。它允许用户通过网络连接到远程主机,以便像在本地计算机上一样使用它们的命令行接口。
Telnet是一种基于文本的协议,它使用简单的命令和响应消息。用户可以通过telnet连接到支持此协议的计算机或设备,例如路由器、交换机、服务器等,并使用命令行来执行操作。
Telnet最初是作为一种远程连接协议而设计的,但由于其不安全的性质(未经加密传输密码),它已被SSH(Secure Shell)等更安全的协议所取代。不过,Telnet仍然有一些应用场景,例如在内部网络中连接旧设备或在测试环境中进行手动测试。
HTTP1.1以及之前的是基于文本的请求-响应格式,在HTTP/2下是基于二进制格式。
1.3 HTTP的语法和历史
1.3.1 HTTP/0.9
HTTP的第一个规范是1991年发布的0.9版本。该规范指定,通过TCP/IP(或类似的面向连接的服务)与服务器和端口(可选,默认80)建立连接。客户端应发送一行ASCII文本,包括GET、文档地址(无空格)、回车符和换行符(回车是可选的)。服务器使用HTML格式的消息进行响应,该消息被定义为“ASCII字符的字节流”。
GET /section/page.html
1.3.2 HTTP/1.0
HTTP/1.0新增了一些关键特性:
- 更多的请求方法,除了GET方法,还新增了HEAD和POST方法。
- 为所有的消息添加HTTP版本号字段。此字段是可选的,为了向后兼容。
- HTTP首部。它可以与请求和响应一起发送。
- 一个三位整数的响应状态码。
HTTP/1.0的方法
HEAD方法允许客户端获取资源的所有云信息(例如HTTP头)而无须下载资源本身。
POST方法允许客户端发送数据到Web服务器。POST方法不仅可以发送完整的文件,还可以发送表单数据。
URL受到长度和内容方面的限制,因此POST方法通常是一种更好的数据发送方式。
GET请求是幂等的,而POST请求不是。这意味着对于同一个URL的多个GET请求,应始终返回相同的结果。而对于同一URL请求的多个POST请求,则可能不会返回相同的结果。
HTTP请求首部
GET /page.html HTTP/1.0
Header1: Value1
Header2: Value2
// or 没有首部
GET /page.html HTTP/1.0
首部名称(而不是内容)不区分大小写。可以发送具有相同名称的多个首部,在语义上这与发送以逗号分隔的版本完全相同。
HTTP响应状态码
一个经典的来自HTTP/1.0服务器的响应如下:
HTTP/1.0 200 OK
Date: Sun, 25 Jun 2017 13:30:24 GMT
Content-Type: text/html
Server: Apache
<!doctype html>
<html>
<head>
...etc.
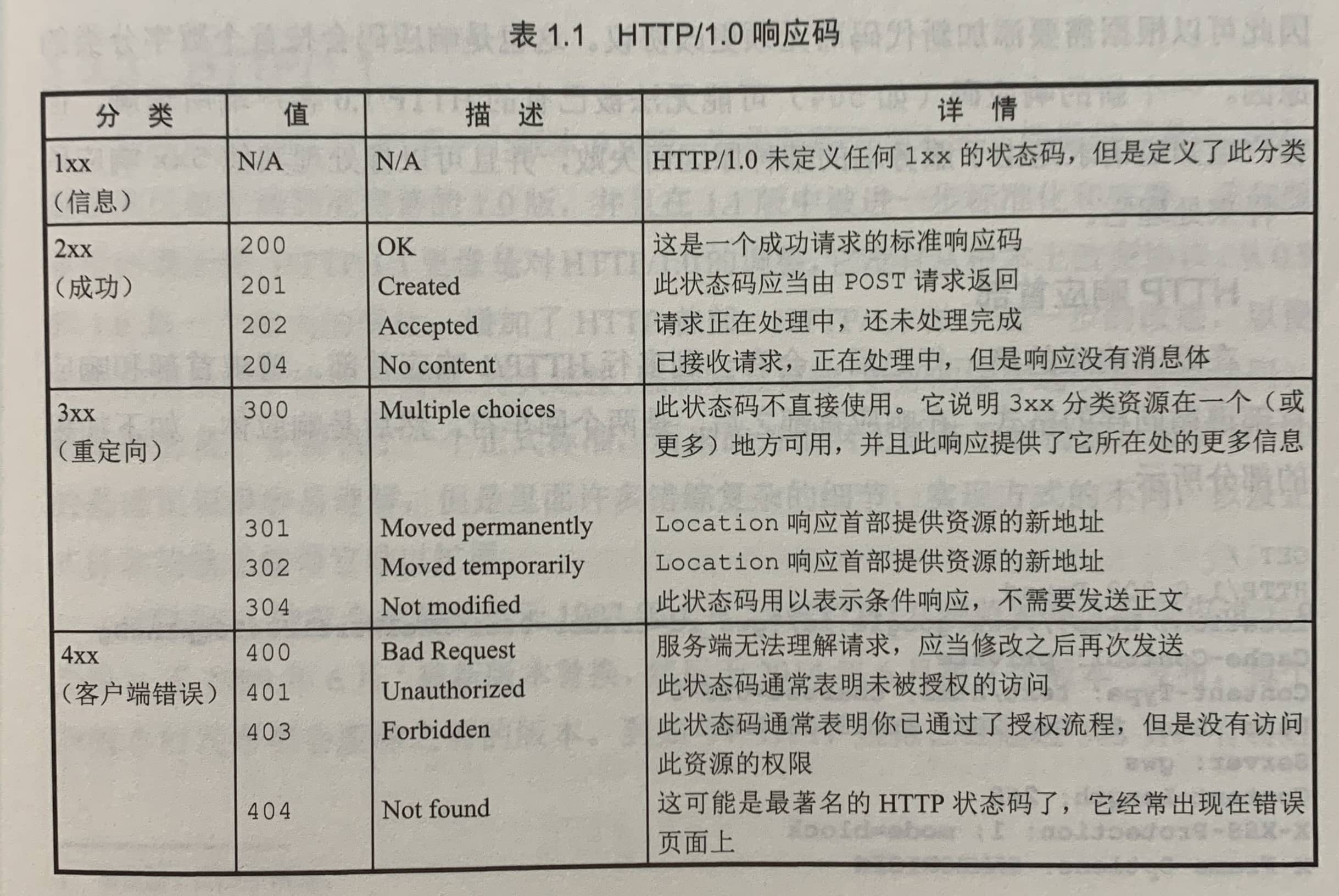

该规范指出,响应码是可扩展的,因此可以根据需要添加新代码而无须更改协议。
HTTP响应首部
请求首部和响应首部遵循同样的格式。在响应首部之后,是两个回车符,然后是响应体。
1.3.3 HTTP/1.1
HTTP/1.1更像是对HTTP/1.0的调整,它没有从根本上改变协议。HTTP/1.1做了进一步的改进,以便充分利用HTTP协议(例如,持久连接、强制响应首部、更好的缓存选项和分块编码)。更重要的是,它提供了一个正式标准,后来的万维网正是基于它构筑的。
HTTP/1.1的首个规范与1997年1月发布,与1999年6月被新版本替换,然后于2014年6月第3个版本发布。每个新版本的发布都会废除之前的版本。
强制添加Host首部
这个首部在HTTP/1.0是可选的,但是在HTTP/1.1中是必选项。
GET / HTTP/1.1
Host: www.google.com
根据HTTP/1.1的规范,请求应该被服务器拒绝(使用一个400状态码),但是多数Web服务器很宽容,对于此类请求它们会使用一个默认的Host。
将Host作为必选项是HTTP/1.1的重要改进,这使得服务器能够充分利用虚拟主机托管技术。HTTP/2.0使用*:authority*伪首部字段代替Host首部。
持久连接
起初的HTTP会在每个请求完之后立马断开连接,关闭连接被证明是一种浪费性能的行为。
通过Connection首部设置为Keep-Alive,客户端可以要求服务器保持连接打开,以支持发送更多的请求:
GET /page.html HTTP/1.0
Connection: Keep-Alive
如果服务器支持持久连接,它会在响应中包含一个Connection: Keep-Alive首部。
服务器告诉客户端,在发送完响应之后,马上就可以在同一个连接上发送一个新的请求,服务器不用每次都关闭再重新打开连接。当使用持久连接时,想要知道响应何时完成可能会更困难。所以使用了Content-Length首部来定义消息响应体的长度,以便当整个消息体传输完成后,客户端可以发送一个新请求。
客户端或服务器可以在任何时候关闭HTTP连接。关闭可能会意外发生或有意为之。因此,即使使用持久连接,客户端和服务器也应该监视连接并处理意外关闭的连接。
HTTP/1.1不仅将持久连接添加到文档标准中,还将其作为默认行为。即使响应中没有Connection: Keep-Alive首部,也可以假定任何HTTP/1.1连接都使用持久连接。如果服务器想要关闭连接,则它必须在响应中显示包含Connection: close的HTTP首部。
在此基础上,HTTP/1.1增加了管道的概念,因此应该可以通过同一个持久连接发送多个请求并按顺序获取相应。例如,如果Web浏览器正在处理HTML文档,并且发现需要CSS文件和JavaScript文件,它应该能够将这些文件的请求一起发送,并按顺序获取响应,而不需要等待第一个请求响应完成后才发出第二个请求。
由于某些原因,管道化并没有流行起来,并且客户端(浏览器)和服务器对管道化的支持都很差。大多数HTTP/1.1的实现仍然是遵循请求响应再请求再响应的模式。
其他新功能
HTTP/1.1引入了很多其他的新功能,包含:
- HTTP/1.1新增了PUT、OPTIONS和比较少见的CONNECT、TRACE及DELETE。
- 更好的缓存方法。这些方法允许服务器指示客户端将资源缓存在浏览器的缓存中,以便在以后需要时重复使用。在HTTP/1.1引入的Cache-Control HTTP首部比HTTP/1.0中的Expires首部的选项更多。
- HTTP cookies,允许HTTP维护状态。
- 引入字符集,在HTTP响应中新增语言选项。
- 支持代理。
- 支持权限验证。
- 新的状态码。
- 尾随首部。
HTTP协议不断添加新的首部以进一步扩展功能,其中许多是出于性能或安全原因。曾经有一个惯例,是在这些首部中包含一个*x-*来表明它们没有被正式标准化(X-Content-Type、X-Frame-Options),但这个约定已经不推荐使用了。
1.4 HTTPS简介
HTTP最初是一个纯文本协议,它以未加密的方式通过互联网发送,因此在被路由到目的的过程中,任何一方都可以读取到消息。
HTTPS是HTTP的安全版本,它使用TLS(Transport Layer Security,传输层安全)协议对传输进行加密,TLS的前身是我们熟知的SSL(Secure Sockets Layer,安全套接字层)。
HTTPS对HTTP消息添加了三个重要概念:
- 加密——传输过程中第三方无法读取消息。
- 完整性校验——消息在传输过程中未被更改,因为整个加密消息已经过数字签名,并且该签名在解密之前已通过加密验证。
- 身份验证——服务器不是伪装的。
SSL是由Netscape发明。SSLv1从未在Netscape之外发布,第一个生产版本是1995年发布的SSLv2。1996年发布的SSLv3解决了一些安全漏洞。
由于SSL由Netscape拥有,因此它不是正式的互联网标准,尽管它随后有IETF作为历史文档发布。SSL被标准化为TLS(传输层加密)。TLSv1.0与SSLv3类似,但是它们不兼容。
在2014年,在SSLv3中发现了重大漏洞,此后SSLv3被停止使用,并且浏览器也停止对它的支持。从这时人们才开始大量向TLS迁移。
由于这段历史所造成的影响,人们对这些缩写的用法并不统一。许多人仍将加密称为SSL,因为它在那么长的一段时间里都是标准。其他人使用SSL/TLS或TLS。
HTTPS是基于HTTP构建的,几乎可以与HTTP协议无缝衔接。它默认在443端口上服务。
建立HTTPS会话后,将交换标准HTTP消息。客户端和服务器在发送消息之前加密消息,在接收之前解密消息。对于普通的Web开发者或服务器管理员来说,在配置完成后,HTTPS和HTTP没有区别。除非要查看通过网络发送的原始消息,否则来讲一切都是透明的。
1.5 查看、发送和接收HTTP消息的工具
浏览器开发者工具
HTTPS由浏览器处理,因此开发者工具只显示加密之前的HTTP请求和解密之后的响应。
Postman、Advanced REST
curl、wget和httpie
第2章 通向HTTP/2之路
HTTP/1.1是互联网大部分应用的基础,是已经良好运行20多年的技术。在此期间,网络呈爆炸式增长,从简单的静态网站转变为交互式的网页。
2.1 HTTP/1.1和当前的万维网
2.1.1 HTTP/1.1根本的性能问题
HTTP/1.1的问题在于浪费了大部分的时间在等待消息在网络上发送。
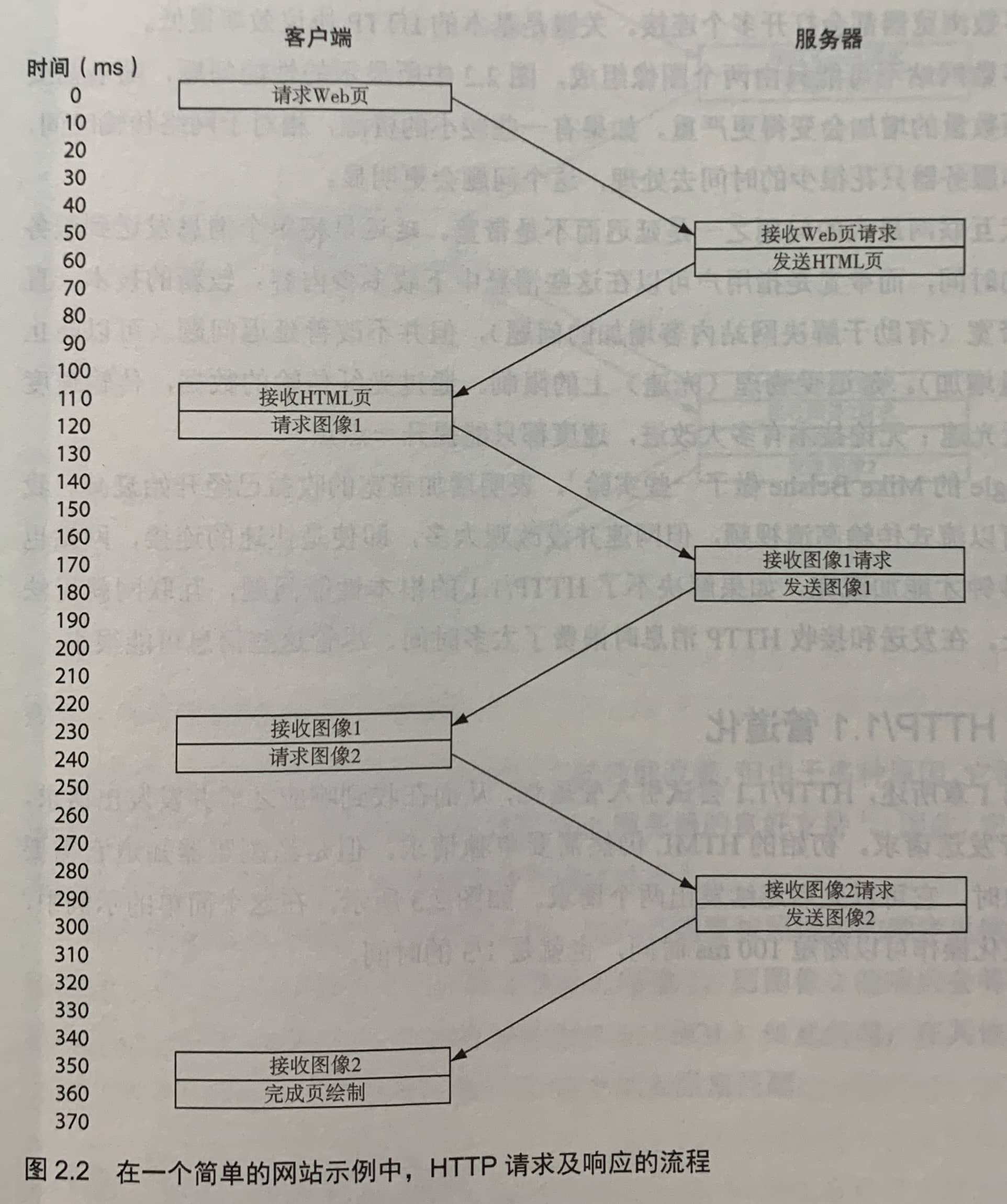
2.1.2 HTTP/1.1管道化
HTTP/1.1尝试引入管道化,从而在收到响应之前并发发出请求,实现并行发送请求。初始的HTML仍然需要单独请求。
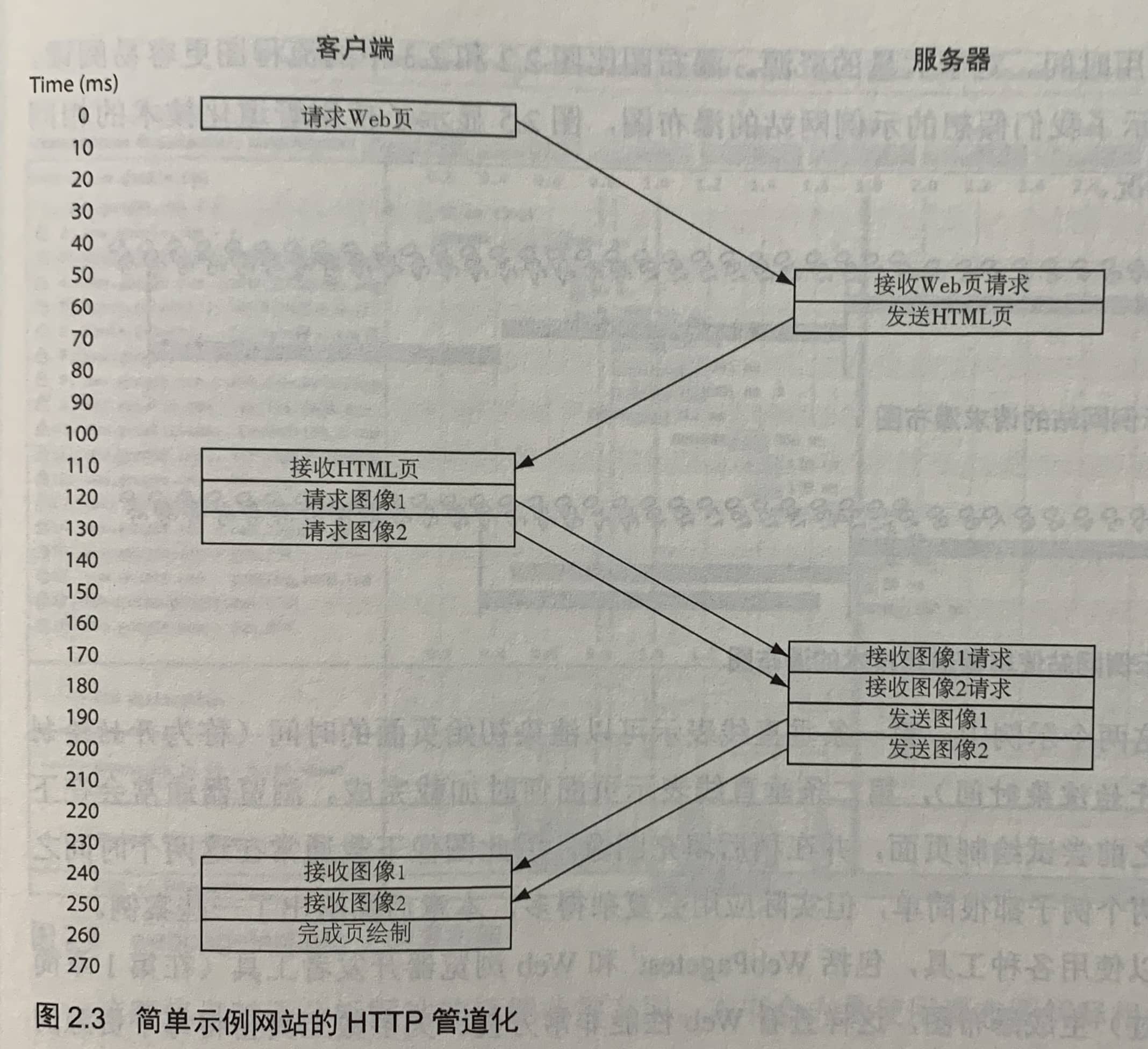
使用管道化可以缩短一些时间。由于多种原因,它很难实现,易于出错,并且没有获得Web浏览器和Web服务器的良好支持。因此,它很少被使用。没有一个主流的Web浏览器支持管道化技术。
即使管道化技术得到良好的支持,但它仍然需要按照请求的顺序返回响应。此问题被称为队头(HOL)阻塞问题。
2.1.3 网络性能瀑布流图
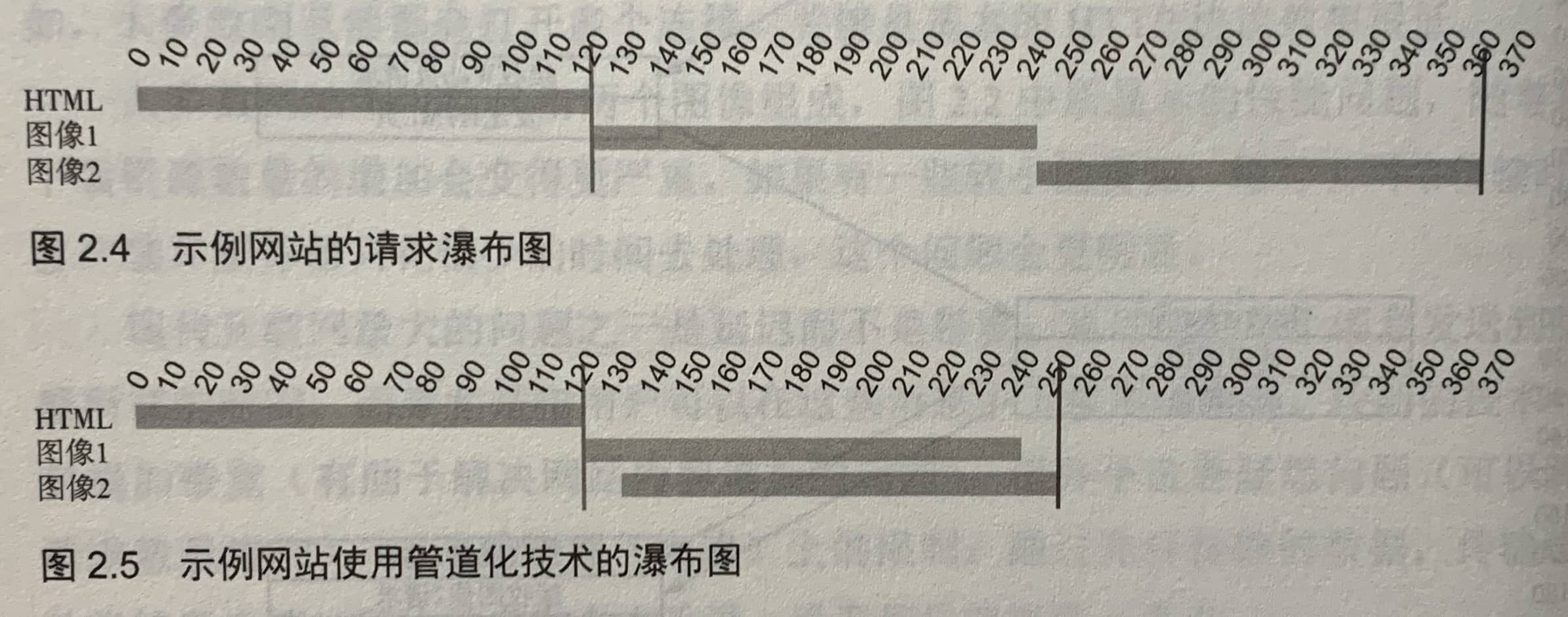
可以使用各种工具如WebPagetest和Web浏览器开发者开发者工具生成瀑布图,这样查看Web性能非常方便。
上图是一张正常的瀑布流图,它将每个请求分成几个部分,包括:
- DNS查询
- 网络连接时间
- HTTPS(或SSL)协商时间
- 请求的资源分类(并将资源负载分为两部分,用于请求的颜色较浅,用于响应的颜色较深)
- 加载页面各个阶段的各种垂直线
- 其他图标,显示CPU使用率、网络带宽,以及浏览器工作在哪个主线程中。
2.2 解决HTTP/1.1性能问题的方案
2.2.1 使用多个HTTP连接
打开多个连接是解决HTTP/1.1阻塞问题的最简单方法,与管道化技术不同,该技术不会导致HOL阻塞。大多数浏览器可以为每个域名打开6个连接。
为了进一步突破6个连接的限制,许多网站从子域提供静态资源,如图像、CSS和JavaScript,Web浏览器从而可以为每个新域名打开另外6个连接。这种技术称为域名分片。通常,这些域名托管在同一台服务器上。共享相同的资源但使用不同的域名会让浏览器误以为服务器是相互独立的。
使用多个HTTP连接的缺点是客户端和服务器都有额外的开销:打开TCP连接需要时间,维护连接需要更多的内存和CPU资源。它的主要问题是没有充分利用TCP协议,TCP的拥塞窗口会在三次握手之后的一段时间内,随时间推移拥塞窗口逐渐增大,这将导致建立连接的开销和慢启动的问题。它还会导致带宽问题,如果所有带宽都用掉了,就会导致TCP超时重传,在这些独立的连接之间,没有优先级的概念,这就无法更高效的利用带宽。
所以,开启多个HTTP连接并不是解决HTTP/1问题的满意方案,尽管在没有更好的解决方案时,它确实可以提升性能。
2.2.2 发送更少的请求
发送更少的请求包括:减少不必要的请求(比如在浏览器中缓存静态资源),以更少的HTTP请求获取同样的资源。
对于图片来说,这种打包技术叫做精灵图。

如果是CSS和JavaScript文件,很多网站会将多个文件合并为一个文件,这样需要的请求数就少了,但是总的代码量并不少。在合并文件的时候,通常还会去掉代码中不必要的空格、注释和其他不必要的元素。这些方法都会提升效率,但是会增加配置的难度。
其他的技术还包括内联资源到其他文件。比如,Critical CSS经常直接被内联在HTML的<style>标签中。图片可以包含在CSS中,通过行内SVG或者转换为Base64编码,也能减少HTTP请求数。
这个方案的主要问题是它引入的复杂度。另外一个问题是合并会导致文件的浪费,比如一些网页可能只用到一张精灵图中的一两个图标,但却要下载整张精灵图。最后一个问题是缓存,如果把精灵图缓存很长一段时间,当需要添加一个图标的时候,必须让浏览器再次下载整个精灵图。可以使用很多技术来解决这个问题,比如添加版本号或者使用查询参数。
归根到底,优化HTTP/1性能的方法是一些解决HTTP/1基础缺陷的小技巧。
2.3 HTTP/1.1的其他问题
HTTP/1.1是一个简单的文本协议,尽管HTTP消息体可以包含二进制数据(比如图片,以及客户端和服务器能理解的任何格式),但请求和首部需要是文本的形式。文本格式对人类来说很友好,但是对于机器并不友好。HTTP文本消息处理起来很复杂,且容易出错,会导致安全问题。
HTTP使用文本格式带来的另外一个问题是,HTTP消息较大,这是因为不能高效编码数据(比如使用数字来表达Date首部,而不是使用人类可读的完整文本),而且首部内容也有重复。例如,就算只有主页需要cookie,每个发向服务器的HTTP请求中都会包含cookie。通常,静态资源都不会需要cookie。域名分片能用来创建所谓的无cookie域名,出于性能和安全考虑,浏览器不会向这些域名发送cookie。
2.4 实际案例
2.4.1 示例网站1:amazon.com


上图是一个使用http1.1的访问www.amazon.com的瀑布流图,出自webpagetest。
- 首个请求是主页的请求,此时需要花费时间做DNS解析、TCP连接、SSL/TLS协商。
- CSS文件托管在另外一个域
https://images-na.ssl-images-amazon.com下,此时域名和主域名不同。由于域名是独立的,所以在下载CSS文件时,需要从头开始(NDS查询、TCP连接、SSL)。在请求1中,当浏览器还在处理HTML页面时,CSS请求就开始了。浏览器不需要等整个HTML页面下载处理完才开始下载其他资源,它只要发现域名引用就开始新的资源请求。 - 第三个请求是同一个域名上的CSS资源,由于HTTP/1.1在一个连接上同一时间只允许一个请求,因此浏览器创建了另外一个连接。这次省去了DNS查询时间,但是在请求CSS之前,还需要进行耗时的TCP/IP连接创建和HTTPS协商。
- 之后浏览器通过这两个已经创建的连接请求了另外3个CSS文件。图中没有说明为什么浏览器没有直接请求这些文件,这样会需要更多连接,花费更多资源。
- 在第2~6个请求,加载CSS文件之后,浏览器开始加载图片。
- 当有两个图片在请求中时,浏览器需要创建更多消耗性能的连接,以并行下载资源,如请求9、10、11和15。然后对14、17、18和19使用不同的域名。
- 在一些场景下,浏览器猜测可能需要更多的连接,所以提前创建连接,这就是为什么9-11和7、8同时发起图片请求。
- Amazon添加了一个性能优化的方法,对
m-media-amazon.com使用DNS prefetch(预解析)。请求17的DNS解析过程发生在0.6s。
加载amazon.com主页花了20个连接,这还没算上广告资源。
Amazon的示例说明,在HTTP/1.1下,就算网站通过变通的方法进行了充分的性能优化,它还是会有一些性能问题。这些优化方法设置起来也很复杂。不是每个网站都想管理多个域名,都需要做精灵图,或者将JavaScript或CSS合并起来。
2.4.2 示例网站2:imgur.com
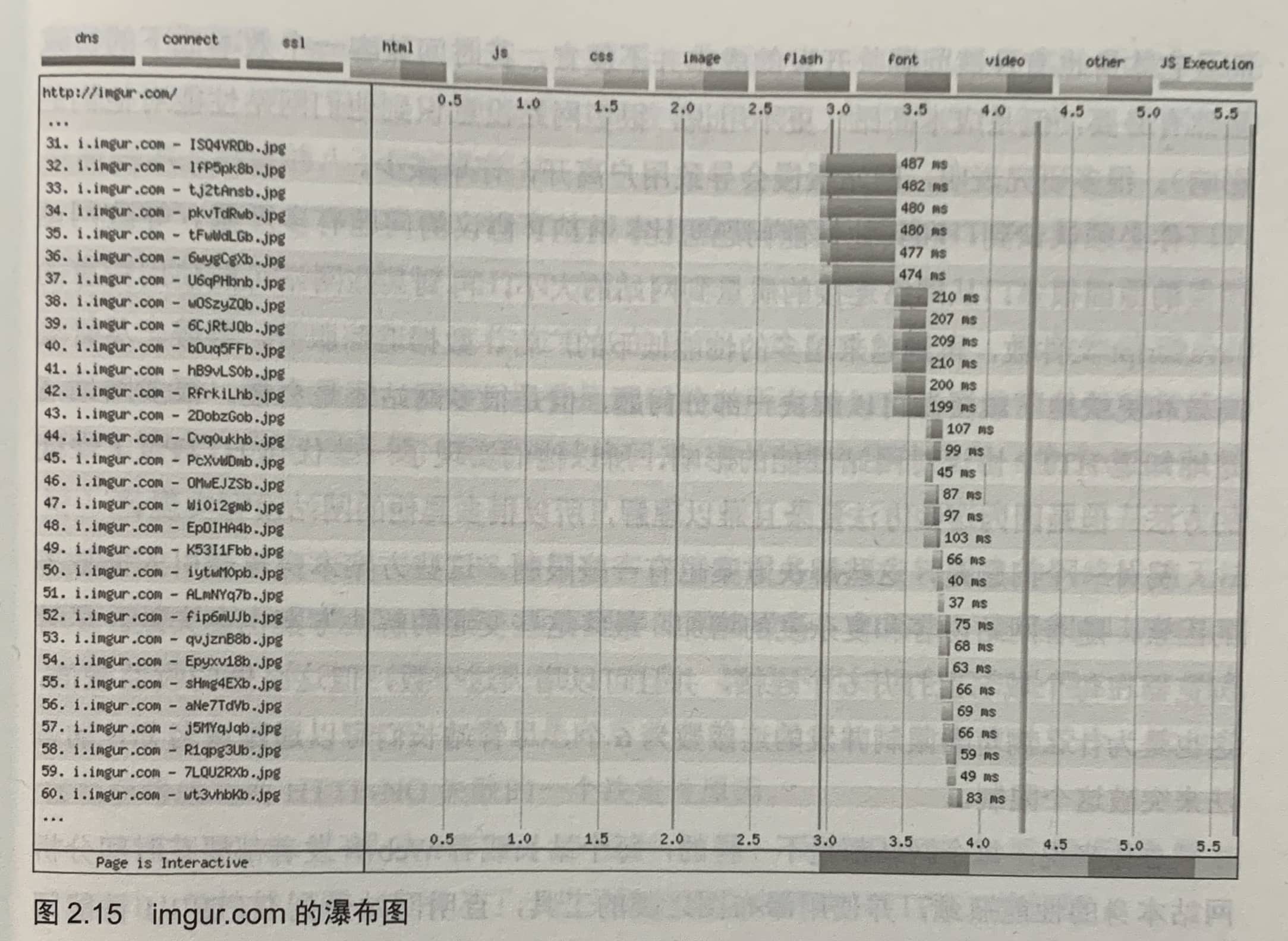
imgur.com是一个图片分享网站,它会在主页加载大量图片,不会将它们合并为精灵图。上图中,可以看到,它使用最大6个连接去加载请求31~36,之后的请求在排队。当每6个请求完成后,开始新的6个请求。
2.5 从HTTP/1.1到HTTP/2
在1999年HTTP/1.1走上历史舞台之后,HTTP并没有真正发生改变。
2.5.1 SPDY
2009年,Google的Mike Belshe和Robert Peon宣布,他们在开发一个叫做SPDY的新协议,结果很好,页面加载时间改善了65%。
SPDY基于HTTP构建,没有从根本上改变协议。就像HTTPS封装了HTTP,但是不改变它的底层机制。SPDY工作在更低的层面,对开发者、服务器管理员和用户来说,SPDY几乎是透明的。所有的HTTP请求简单地被转换为SPDY请求,发向服务器,然后再转换回来。SPDY的实现只基于加密的HTTP(即HTTPS)。HTTPS使得在客户端和服务器间中转消息的网络设施无法查看消息的结构和格式。所以,所有现存的网络设备,如路由、交换机和其他基础设施不用做任何改变就能处理SPDY消息,甚至不用知道它们在处理SPDY消息还是HTTP/1消息。SPDY本质是向后兼容的,带来的风险和改动较少。
SPDY的主要目标是解决HTTP/1.1的性能问题,它引入了一些关键的概念来解决HTTP/1.1的问题:
- 流多路利用——请求和响应使用单个TCP连接传输数据,它们被分为不同的数据包,以流的方式分组。
- 请求优先级——在同时发送所有请求时,为了避免引入新的性能问题,引入了请求优先级的概念。
- HTTP首部压缩
相比HTTP/1.1文本协议,SPDY是一个二进制协议。这个改动使得我们可以在一个连接上处理较小的消息,然后将它们合并为较大的HTTP消息,这跟TCP将HTTP消息拆分为TCP数据包的模式非常像。SPDY在HTTP层实现了TCP的相关概念,所以它可以同时传输不同的HTTP消息。
Google在2010年9月开始利用主流Chrome浏览器和一些流行的Google网站推广SPDY,SPDY几乎在一夜之间获得了成功,其他产商也开始支持SPDY。随着HTTP/2问世之后,一些浏览器开始取消对SPDY的支持。
2.5.2 HTTP/2
SPDY证明了一件事,HTTP/1.1可以优化。2012年,IETF的HTTP工作组注意到SPDY的成功,并开始征集下一版本HTTP的提案。不久之后,2012年11,基于SPDY发布了HTTP/2初稿。在2014年底,HTTP/2规范作为互联网的标准被提出,于2015年5月被正式通过。
在2018年9月,根据w3tech.com的数据,已有30.1%的网站支持HTTP/2。能取得这个成果,主要是因为CDN厂商以及主流网站的支持。
2.6 HTTP/2对Web性能的影响

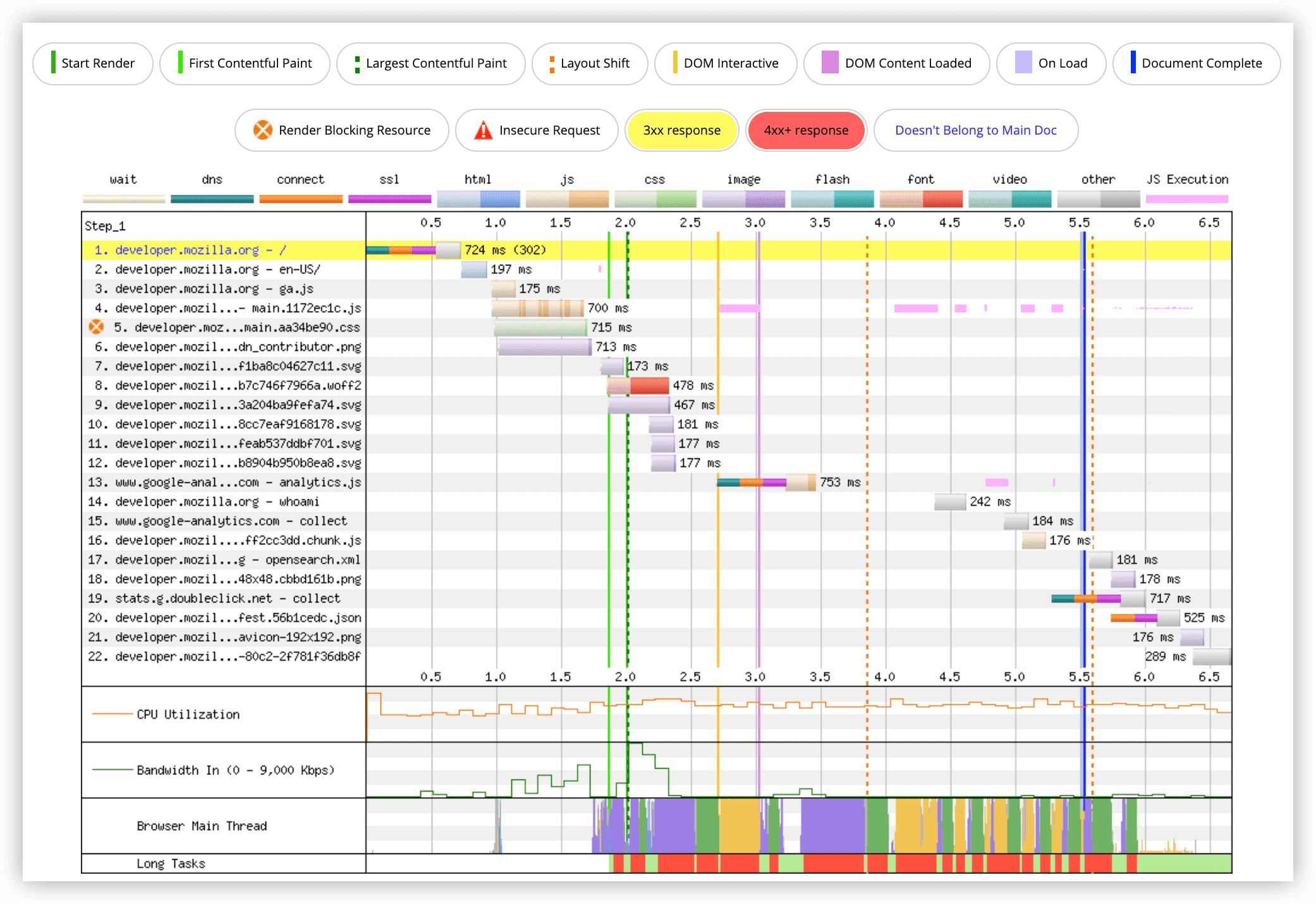
上图展示了加载360张图片下HTTP、HTTPS和HTTP/2性能测试的结果。
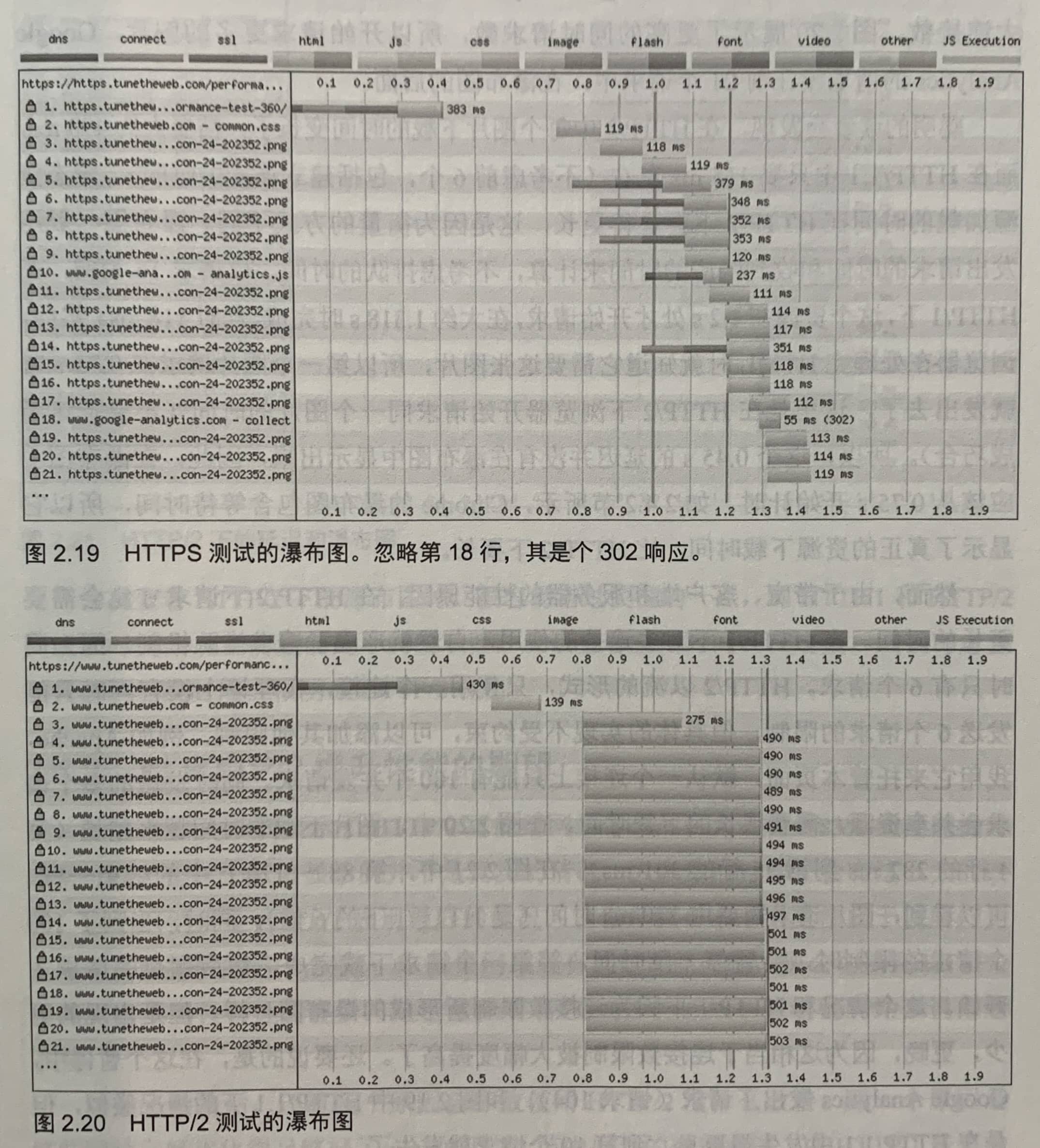
在HTTP/1.1下,要创建多个连接,6个一组地加载图片。在HTTP/2下,图片是同时请求的,所以没有延迟。
HTTP/2以流的形式,只使用一个连接,但也有其它限制,比如Apache默认一个连接上只能有100个并发请求。同时发送的多个请求会共享资源,需要很长的下载时间。
2.6.2 对HTTP/2提升性能的期望
对于一些网站,有两个原因会导致使用HTTP/2没有什么改善。第一个原因是这些网站已经优化得足够好了,由HTTP/1带来的缓慢问题比较少。从理论上讲,只要支持HTTP/2,网站可以轻易获得性能提升,不需要使用域名分片、CSS合并、JavaScript合并、精灵图等技术。
另外一个使用HTTP/2可能不会提升网站性能的原因是其他的性能问题远超HTTP/1带来的影响。HTTP/2只解决网络性能。

此表引用了网络性能圈子常见的一些术语:
- 加载时间指页面发起onload事件的时间——通常指所有的CSS和阻塞式JavaScript加载完成的时间。
- 首字节时间指从网站收到第一个字节的时间。通常,此响应是第一个真正的响应,不是重定向。
- 开始渲染时间指页面开始绘制的时间。
- 视觉完整时间指页面停止变化的时间。
- speed index为由WebPagetest计算的页面每部分加载的平均时间,以ms为单位。
第3章 升级到HTTP/2
3.1 HTTP/2的支持
HTTP/2仅支持有HTTPS的网站,因此不使用HTTPS的网站从中受益。
一些浏览器(如Chrome、Firefox和Opera)备注只有服务器支持ALPN(Application Layer Protocol Negotiation,应用层协议协商),其才支持HTTP2。
ALPN(Application-Layer Protocol Negotiation)和NPN(Next Protocol Negotiation)是两种协议协商机制,用于在客户端和服务器之间协商通信使用的应用层协议。
NPN 是早期的协商机制,由Google开发并被TLS 1.2和更早版本使用。NPN 通过在TLS握手期间的客户端和服务器之间交换协议列表来进行协议协商。
ALPN 是TLS 1.3中引入的新协商机制,与NPN不同,ALPN 是在加密握手完成之后进行协商。客户端和服务器在握手期间交换支持的应用层协议列表,之后,客户端和服务器之间的通信将基于协商的应用层协议。
ALPN和NPN的主要区别在于其执行顺序和支持的协议。NPN是在TLS握手期间执行,而ALPN是在加密握手完成之后执行。此外,ALPN支持更广泛的应用层协议,如HTTP/2,而NPN仅支持较少的协议,如HTTP/1.1。
4个最流行的Web服务器现在都支持HTTP/2,Apache、Nginx、Google和Microsoft IIS。
3.2 网站开启HTTP/2的方法
反向代理主要用以以下两种场景:
- 作为负载均衡器
- 用以卸载一些功能,如HTTPS或HTTP/2
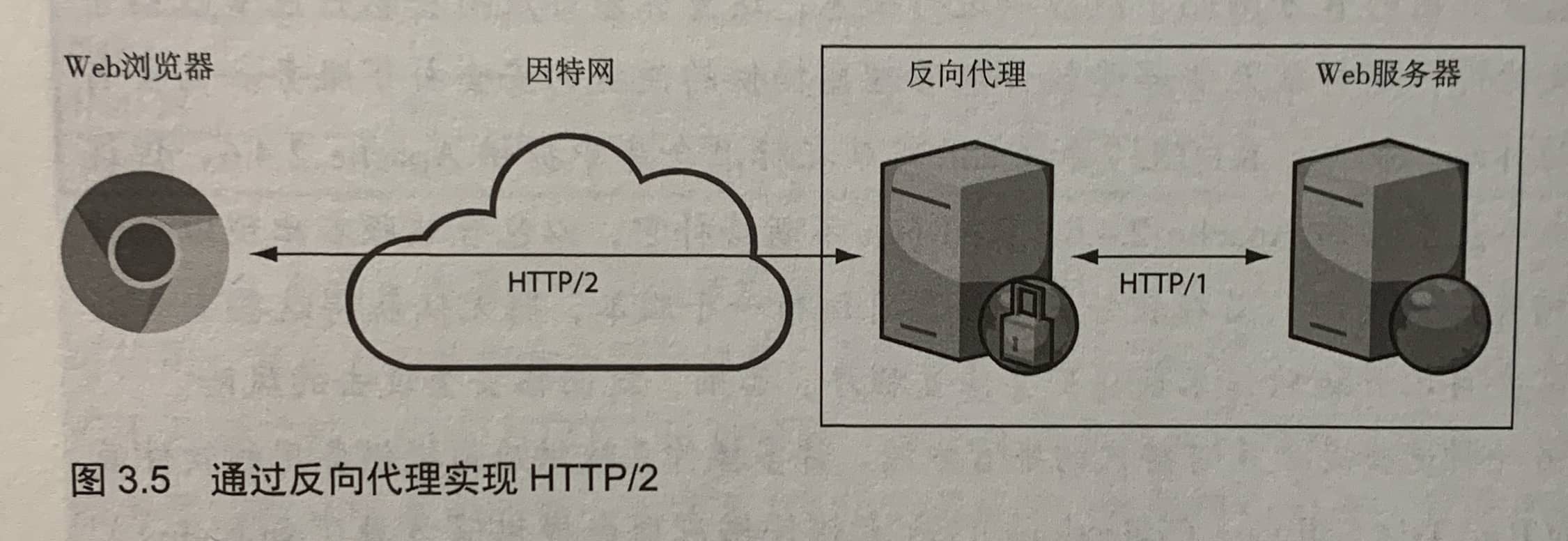
是否需要在整个链路中支持HTTP2
使用反向代理卸载HTTPS,然后反向代理使用HTTP与基础架构的其余部分进行通信。这种用法很常见,因为这可以简化HTTPS配置(仅在入口点设置并管理证书)。
HTTP/2的主要优点是可以提升高延迟、低带宽连接的速度,连接到边缘服务器的用户通常处在这样的网络环境下。从反向代理到其他Web基础架构的流量一般处于低延迟、高带宽、短距离的网络环境中,因此此场景下通常不需要考虑HTTP/1.1的性能问题。
Nginx已经声明,它们不会为代理连接实现HTTP/2,所以也有这方面原因。
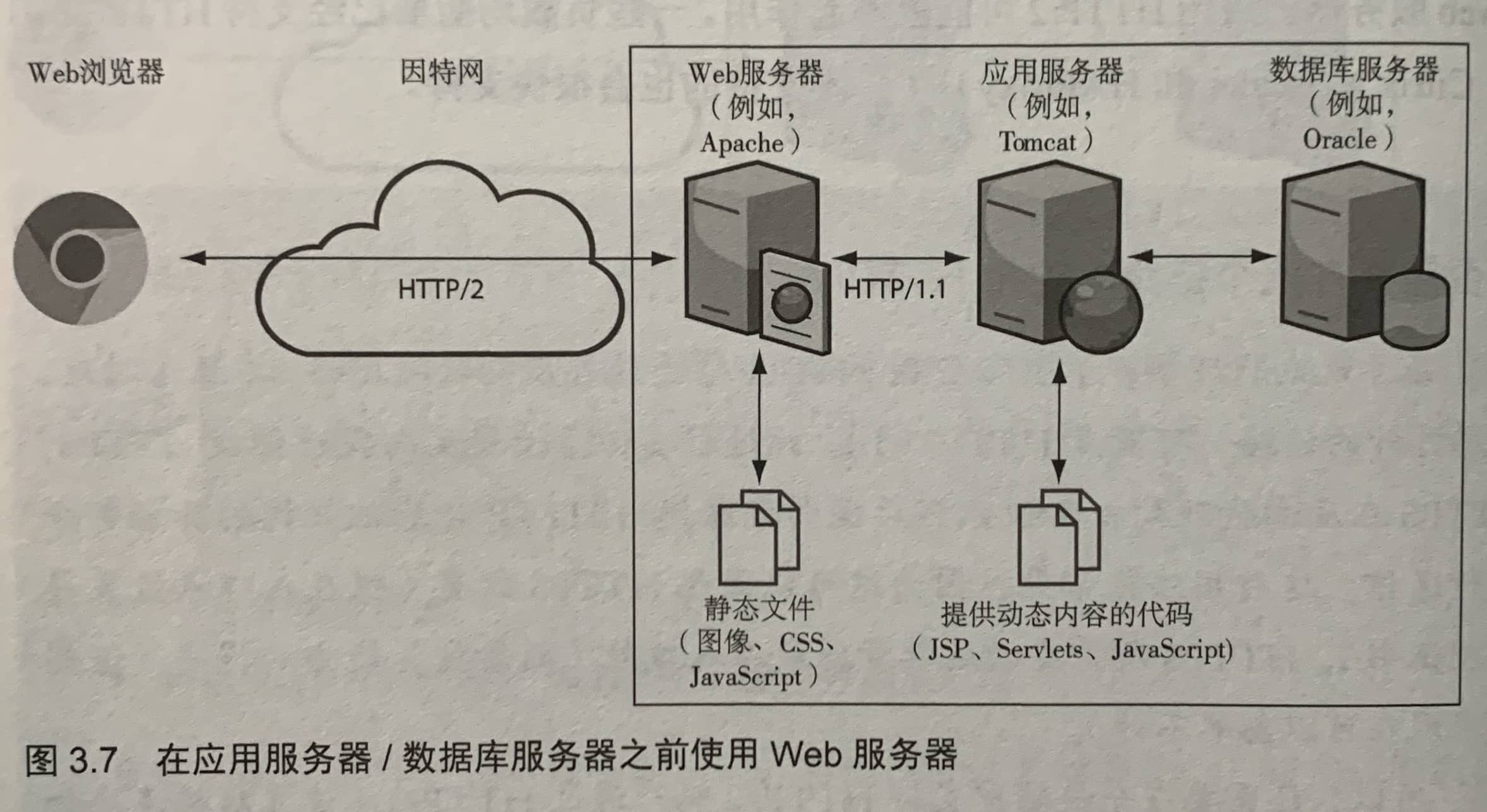
在后端应用服务器(如Tomcat或Node.js)之前使用一个像Apache或Nginx这样的Web服务器来代理一些(或全部)请求,也很常见(推荐做法)。这种技术有几个优点,可以卸载功能,并减少到应用服务器的请求。从Web服务器提供静态资源(图像、CSS和JavaScript库等)可以减少到应用服务器的请求。减轻应用服务器的负载,可以让它专注于自己擅长的工作:提供动态内容,其中可能包括所需的一些运算和数据库查询。
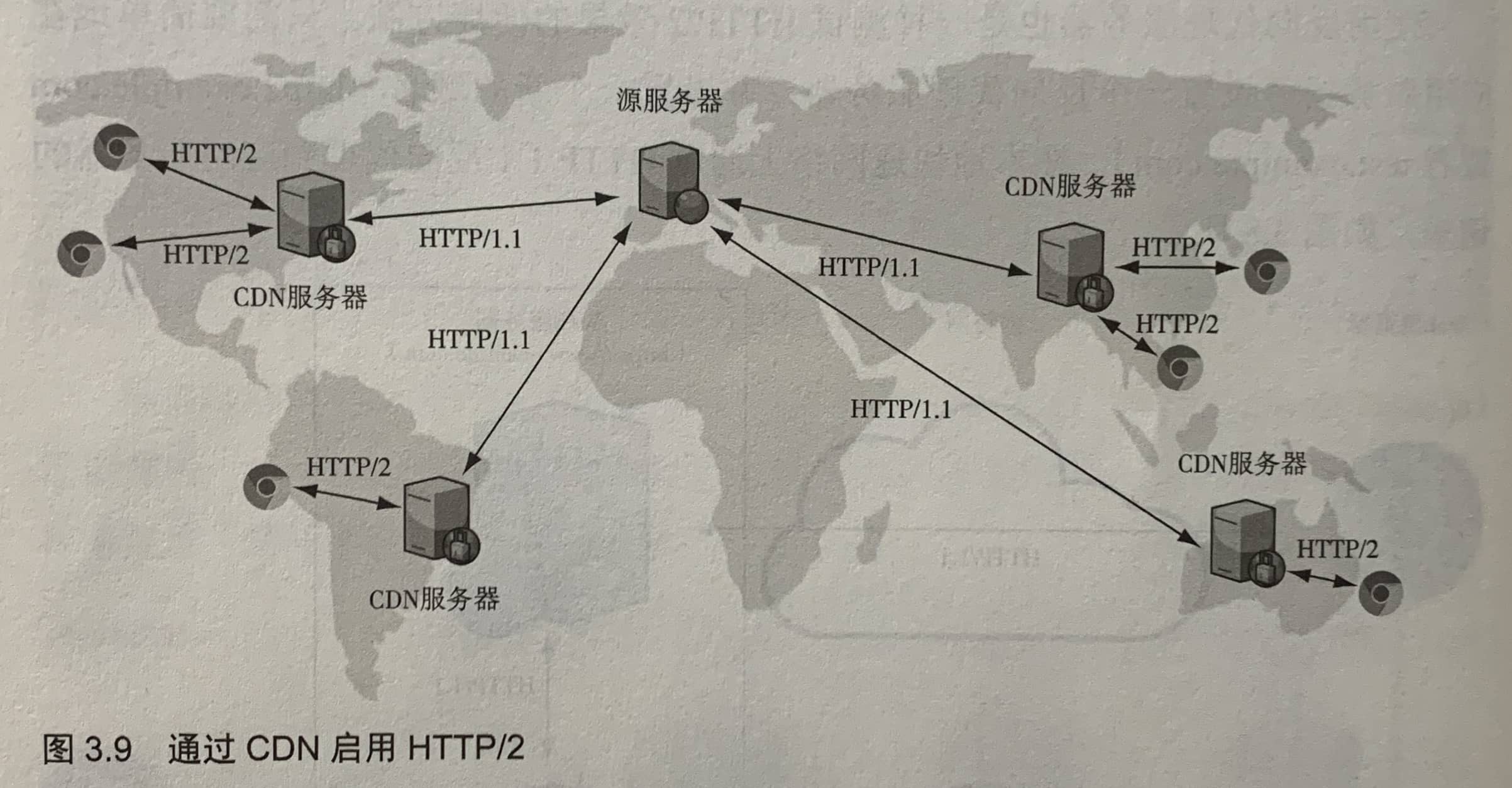
使用CDN的好处:
- 大多数CDN已经支持HTTP/2。
- CDN的连接更快,它能找到离客户更近的服务器与之连接。
- CDN更加安全。
OpenSSL 是一个开源的密码库,它提供了一个广泛的密码学功能,包括加密、解密、数字签名、密钥协商、证书管理等等。
OpenSSL 可以用于多种用途,例如:
- 加密通信:通过使用 OpenSSL 提供的加密算法,可以保证通信的机密性和安全性。常见的应用包括 HTTPS、SSH 等。
- 数字证书管理:OpenSSL 可以用来生成、签署和验证数字证书,包括 SSL 证书、代码签名证书等。
- 安全存储:OpenSSL 提供了一些工具,可以用来加密文件和存储密码等敏感信息。
第2部分 使用HTTP/2
第4章 HTTP/2协议基础
4.1 为什么是HTTP/2而不是HTTP/1.2
HTTP/2与HTTP/1.1有很大的不同,新增了如下概念:
- 二进制协议
- 多路复用
- 流量控制功能
- 数据流优先级
- 首部压缩
- 服务端推送
不支持向前兼容。HTTP/2使用了不同的数据结构和格式,出于这个原因,HTTP/2被视为主版本更新。
新版本的变化主要与HTTP/2在网络中传输的方式有关,在大多数Web开发者所关注的更高层面(HTTP语义),HTTP/2和HTTP/1基本上保持一致。它们拥有相同的请求方法,使用相同的URL、响应码,HTTP首部也大多相同。
HTTP/2和HTTPS有很多相似点,它们都在发送前将标准HTTP消息用特殊的格式封装,在收到响应时再解开。
与HTTP/1(泛指HTTP/1和HTTP/1.1)消息不同,在HTTP/2请求中未声明版本号。例如,HTTP/2中没有GET /index.html HTTP/1.1形式的请求。
4.1.1 使用二进制格式代替文本格式
HTTP/1和HTTP/2的主要区别之一是,HTTP/2是一个二进制的、基于数据报的协议,而HTTP/1是完全基于文本的。基于文本的协议方便人类阅读,但是机器解析起来比较困难。
在过去的20年里,HTTP/1.0引入了二进制的HTTP消息体,支持在响应中发送图片或其他媒体文本。HTTP/1.1引入管道化和分块编码。分块编码允许先发送消息体的一部分,当其余的部分可用时再接着发。这时HTTP消息体被分成多个块,客户端可以在完整收到所有数据之前就开始处理这些分块的内容(服务器也可以收到分块请求)。这个技术常用于数据长度动态生成的场景,预先不知道总数据长度。分块编码和管道化都有队头阻塞(HOL)的问题。
HTTP/2变成了一个完全的二进制协议,HTTP消息被分成清晰定义的数据帧发送。所有的HTTP/2消息都使用分块的编码技术,这是标准行为,不需要显式设置。
HTTP/2中的二进制表示用于发送和接收消息数据,但是消息本身和之前的HTTP/1消息类似。二进制帧通常由下层客户端(Web浏览器或Web服务器)或者类库来处理。像JavaScript这样的上层应用不需要关注消息是如何被发送的,大多数时候可以对HTTP/2连接和HTTP/1连接一视同仁。
4.1.2 多路复用代替同步请求
HTTP/1是一种同步的、独占的请求 - 响应协议。HTTP/1通过打开多个连接来并且使用资源合并以减少请求数来解决这个效率低下的问题,但这两种解决方法都会引入其他的问题和带来性能开销。

HTTP/2允许在单个连接上同时执行多个请求,每个HTTP请求或响应使用不同的流。通过使用二进制分帧层,给每个帧分配一个流标识符,以支持同时发出多个独立请求。当接收到该流的所有帧时,接收方可以将帧组合成完整消息。
帧是同时发送多个消息的关键。每个帧都有标签表明它属于哪个消息(流),这样在一个连接上就可以同时有两个、三个甚至上百个消息。HTTP/2连接在请求发出后不会出现阻塞响应的情况。
可以将响应混合在一起返回或顺序返回,服务器发送响应的顺序完全取决于服务器,但客户端可以指定优先级。每个请求都有一个新的、自增的流ID。返回响应时使用相同的流ID,响应完成后,流将被关闭。
为了防止流ID冲突,客户端发起的请求使用奇数流,服务器发起的请求使用偶数流ID。响应和请求会使用相同的流ID。ID为0的流是客户端和服务器用于管理连接的控制流。

4.1.3 流的优先级和流量控制
在HTTP/2之前,HTTP是单独的请求 - 响应协议,因此没有在协议中进行优先级排序的必要。客户端在HTTP之外就决定了请求的优先级,通常情况下支持6个并发的HTTP/1请求。HTTP/2默认情况下对并发的请求数量的限制达到100个,因此许多请求不需要浏览器来排队,可以立即发送它们。这可能导致带宽浪费在较低优先级的资源(例如图像)上,从而导致HTTP/2页面的加载速度变慢。所以需要控制流的优先级,使用更高的优先级发送最关键的资源。当数据帧在排队时,服务器会给高优先级的请求发送更多的帧。这些过程通常由浏览器和服务器控制,用户和Web开发者几乎无法控制它们。
4.1.4 首部压缩
HTTP首部(包括请求首部和响应首部)用于发送与请求和响应相关的额外信息。在这些首部中,有很多信息是重复的,多个资源使用的首部经常相同。下面的首部,它们会随着每个请求被发送,通常和之前的请求使用相同的值:
- Cookie——Cookie首部有可能会变得非常大,而且通常只有HTML文档需要用到它,但是每个请求都会带上Cookie。
- User-Agent——此首部常用来指示用户在使用的浏览器。在同一个会话中,浏览器从来不会发生变化,但它还是会随着每个请求被发送。
- Host——此首部用来修饰请求URL。发向同一主机的Host首部内容通常相同。
- Accept——此首部定义了客户端期望的响应格式。如果不升级浏览器,那么浏览器所支持的内容格式不会变化,每个请求的内容类型(图片、文档、字体等)对应的Accept首部值不同,但是针对每个类型的不同请求,它们的值是一样的。
- Accept-Encoding——此首部定义了压缩格式(通常是gzip、deflate、br)。
响应首部可能也会重复。在这种情况下,HTTP首部将占下载资源的很大一部分。
HTTP/1允许压缩HTTP正文内容(Accept-Encoding首部),但是不会压缩HTTP首部。HTTP/2引入首部压缩的概念,但是它使用了和正文压缩不同的技术,该技术支持跨请求压缩首部。
4.1.5 服务器推送
服务端推送允许服务器给一个请求返回多个响应。但如果使用不当,它很容易浪费带宽。
4.2 如何创建一个HTTP/2连接
HTTPS使用新的URL scheme(https://),上提供服务。这个改动可以明确区分不同的协议。然而,使用新的scheme和端口号进行协议升级,有一些缺点:
- 直到被普遍支持之前,默认协议都需要保持不变。
- 网站需要改变链接,以使用新的scheme。
- 网络基础设施带来一些兼容性问题。
出于以上原因,HTTP/2决定不启用新的scheme,而是使用其他方法来建立HTTP/2连接。HTTP/2提供了三种建立HTTP/2连接的方法(目前有了第4种):
- 使用HTTPS协商。
- 使用HTTTP Upgrade 首部。
- 和之前的连接保持一致。
理论上,HTTP/2支持基于未加密的HTTP创建连接,也支持基于加密的HTTPS创建连接。实际上,所有的Web浏览器仅支持基于HTTPS建立HTTP/2连接,所以浏览器使用第一个方法来协商HTTP/2。服务器之间的HTTP/2连接可以基于加密或未加密的HTTP。
4.2.1 使用HTTPS协商
HTTPS需要经过一个协议协商阶段来建立连接,在建立连接并交换HTTP消息之前,它们需要协商SSL/TLS协议、加密的密码,以及其他的设置。在HTTPS握手的过程中,可以同时完成HTTP/2协商,这就不需要在建立连接时增加一次跳转。
HTTPS握手
非对称加密用于协商一个对称加密的密钥,以便在创建连接之后使用对称密钥加密消息。
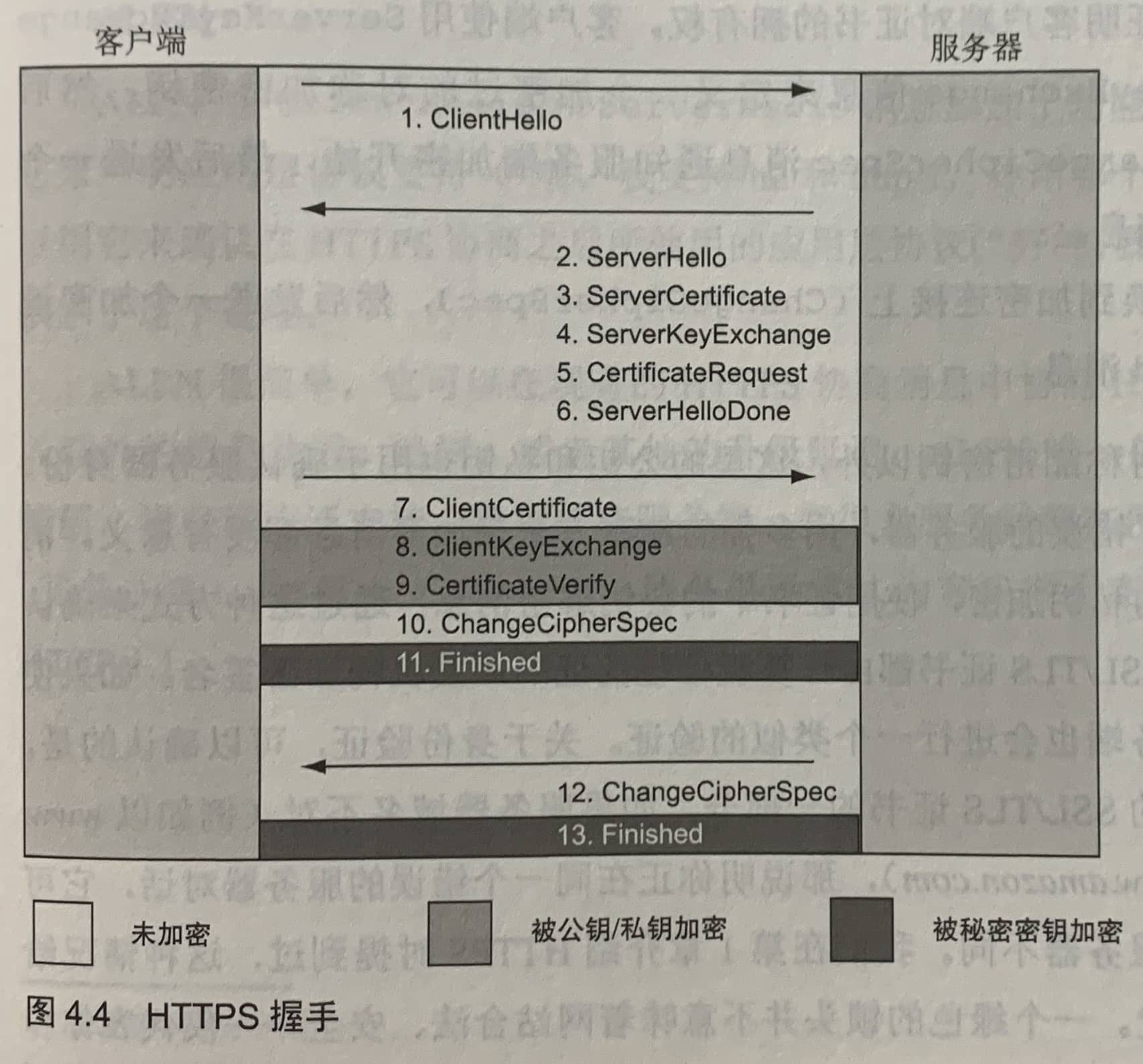
上图是TLSv1.2的握手过程。该握手过程和新的TLSv1.3的握手过程略微不同。
握手过程涉及4类消息:
- 客户端发送一个ClientHello消息,用于详细说明自己的加密能力。不加密此消息,因此加密方法还没有达成一致。
- 服务器返回一个SeverHello消息,用于选择客户端所支持的HTTPS协议(如TLSv1.2)。基于客户端在ClientHello中声明的密码,和服务器本身支持的密码,服务器返回此连接的加密密码(如ECDHE-RSA-AES128-GCM-SHA256)。之后提供服务端HTTPS证书(ServerKeyExchange),以及是否需要客户端发送客户端证书(CertificatRequest,大多数网站不需要)的说明。最后,服务器宣告本步骤结束(ServerHelloDone)。
- 客户端校验服务端证书,如果需要发送客户端证书(ClientCertificate,大多数网站不需要)。然后发送密钥消息(ClientKeyExchange)。这些消息通过服务端证书中的公钥加密,所以只有服务端可以通过密钥解密消息。如果使用客户端证书,则会发送一个CertificateVerify消息,此消息使用私钥签名,以证明客户端对证书的拥有权。客户端使用ServerKeyExchange和ClientKeyExchange信息来定义一个加密过的对称加密密钥,然后发送一个ChangeCipherSpec消息通知服务端加密开始,最后发送一个Finished消息。
- 服务端也切换到加密连接上(changeCipherSpec),然后发送一个加密过的Finished消息。
在HTTPS会话建立完成后,在同一个连接上的HTTP消息就不再需要这个协商过程了。类似地,后续的连接(不管是并发的额外连接,还是后来重新打开的连接)可以跳过其中的某些步骤——如果它复用上次的加密密钥,这个过程就叫做TLS会话恢复。
TLSv1.3可以将协商过程中的消息往返减少到1个(如果复用之前的协商结果,则可以降到0个)。
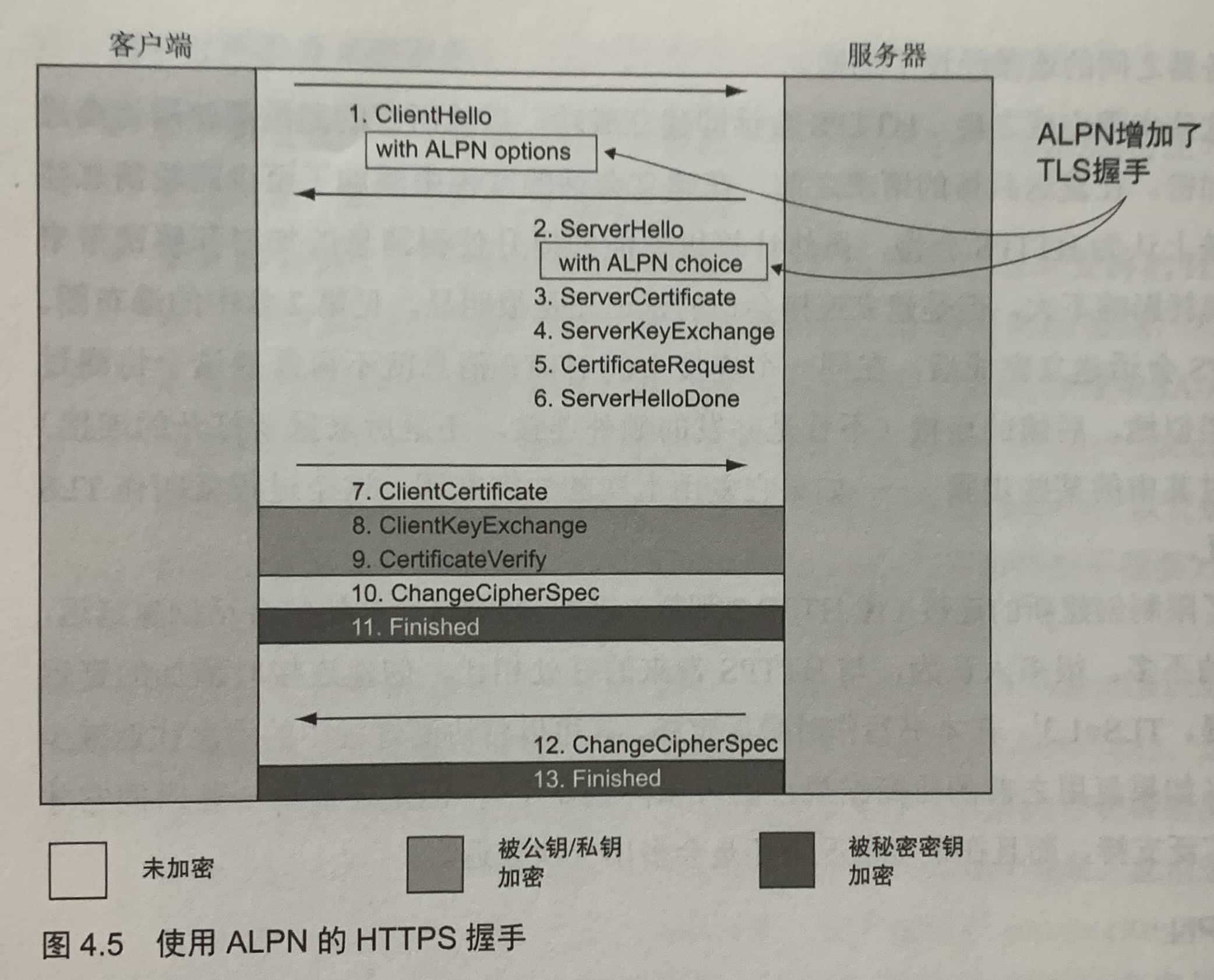
ALPN
ALPN给ClientHello和ServerHello消息添加了功能扩展,客户端可以用它来声明应用层协议支持(“嗨,我支持h2和http/1,你用哪个都行。”),服务端可以用它来确认在HTTPS协商之后所使用的应用层协议(“好的,我们用h2吧”)。
NPN
NPN是ALPN之前的一个实现,两者工作方式类似。尽管被很多浏览器和Web服务器使用,但是它从来没有称为正式的互联网标准。ALPN成为正式标准,它在很大程度上是基于NPN实现的,正如HTTP/2是基于SPDY的。
两者的主要区别是,在使用NPN时,客户端决定最终使用的协议,而ALPN是服务端决定最终使用的协议。
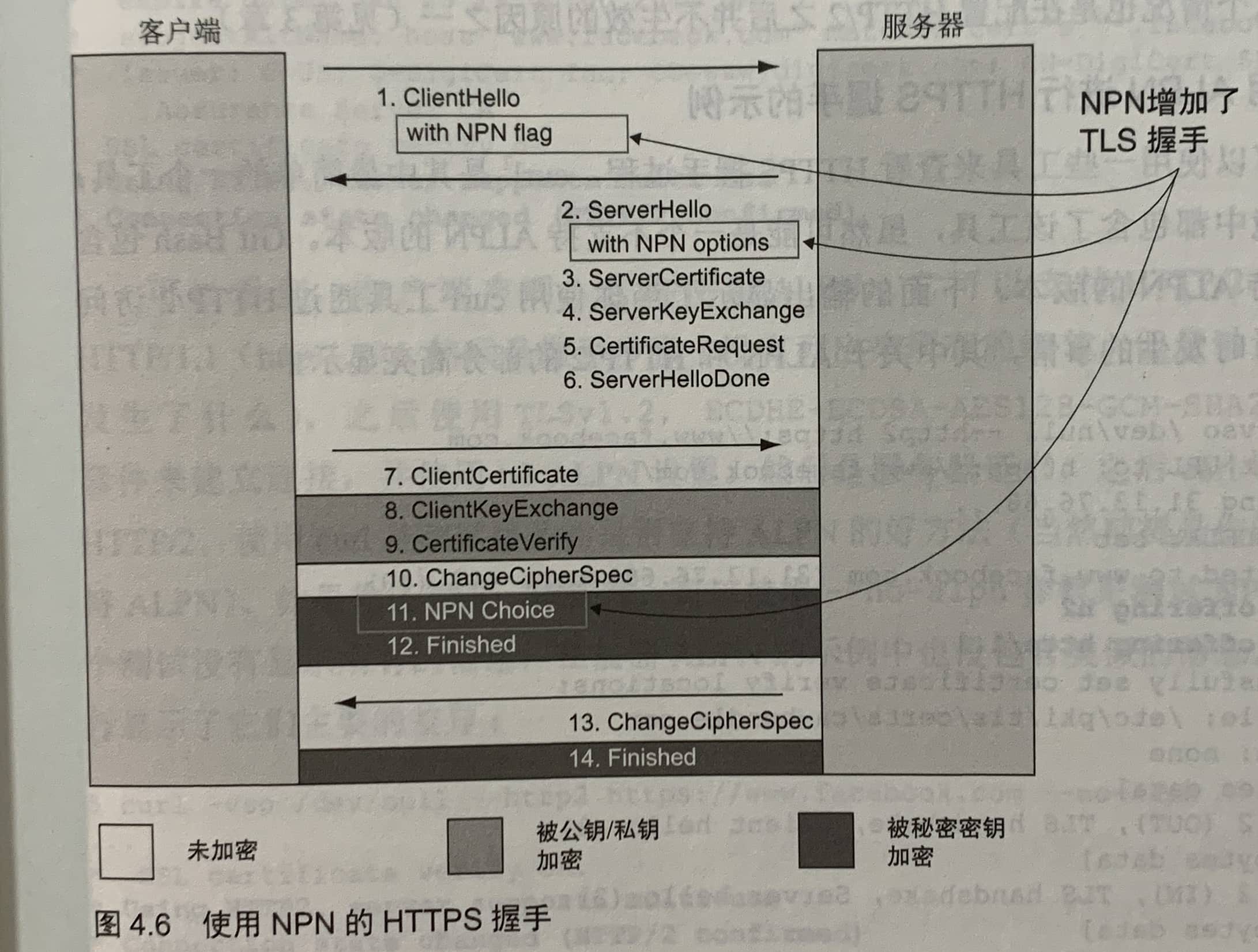
在NPN中,ClientHello消息声明客户端可以使用NPN,ServerHello消息中会包含服务器支持的所有NPN协议。在启用加密后,客户端选择NPN协议(如h2),并使用此协议发送消息。
NPN是一个三步操作,而ALPN是两步操作,这两个操作都复用HTTPS建立连接的步骤,不会添加额外的消息往返。NPN选择的协议是经过加密的,而ALPN是以未加密的形式发送。由于一些网络解决方案想要知道使用的应用协议,因此TLS工作组决定更改ALPN中的相关过程,让服务端来选择应用层协议。
可以使用curl工具来查看HTTPS的握手过程:curl -vso /dev/null --http2 https://www.baidu.com
4.2.2 使用HTTP Upgrade首部
通过发送Upgrade首部,客户端可以请求现有的HTTP/1.1连接升级为HTTP/2。这个首部应该只用于未加密的HTTP连接(h2c)。
4.2.3 使用先验知识
HTTP/2规范描述的第3个客户端使用HTTP/2的方法是,看它是否已经知道服务器支持HTTP/2,如果支持则可以马上开始使用HTTP/2,不需要任何升级请求。
此方法是风险最高的方法,因为它假设服务器可以支持HTTP/2。
4.2.4 HTTP Alternative Services
第4中方法是使用HTTP Alternative Services(替代服务),它没有被包含在原来的标准中。此方法允许服务器使用HTTP/1.1协议(通过Alt-Svc HTTP首部)通知客户端,它所请求的资源在另外一个位置(例如,另一个IP或端口)。可以使用不同的协议访问它们。
该标准相当新,并未得到广泛应用。它仍然需要多一次跳转,这比通过ALPN或先验知识启用HTTP/2要满。
4.2.5 HTTP/2前奏消息
不管使用哪种方法启用HTTP/2连接,在HTTP/2连接上发送的第一个消息必须是HTTP/2连接前奏。此消息是客户端在HTTP/2连接上发送的第一个消息。它是一个24个八位字节的序列。

4.3 HTTP/2帧
4.3.1 查看HTTP/2帧
可以使用Chrome的net-export页面、nghttp和Wireshark来查看HTTP/2帧。
使用Chrome net-export
在地址栏输入chrome://net-export/
生成的日志文件可以使用https://netlog-viewer.appspot.com/查看。
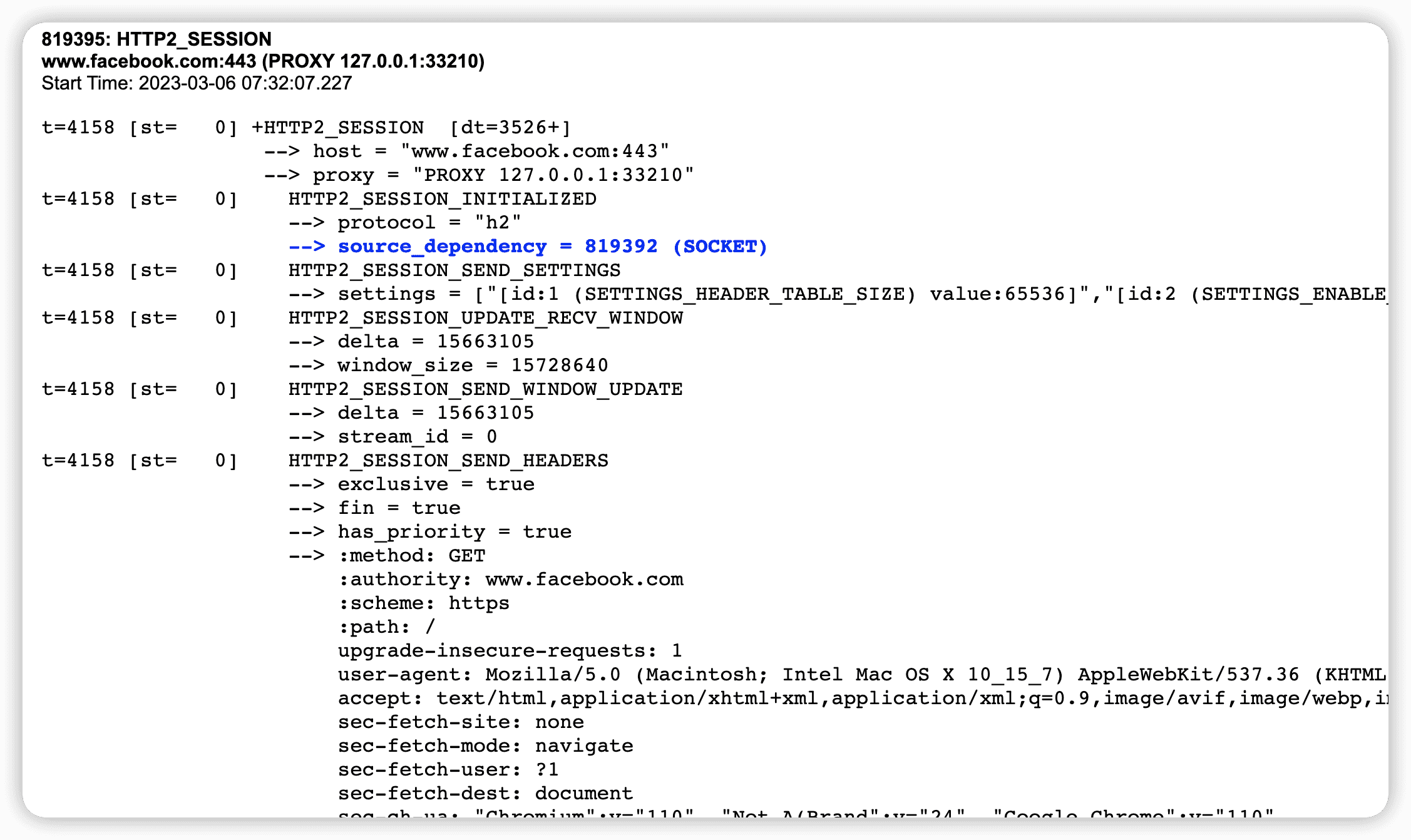
上面这个页面,Chrome添加了许多自己的细节,并且经常将帧分成多行。与使用另外两个工具相比,使用Chrome页面时,读取单个帧可能会有点困难。
使用nghttp
nghttp是一个基于nghttp2 C库开发的命令行工具。nghttp -v https://facebook.com。
使用Wireshark
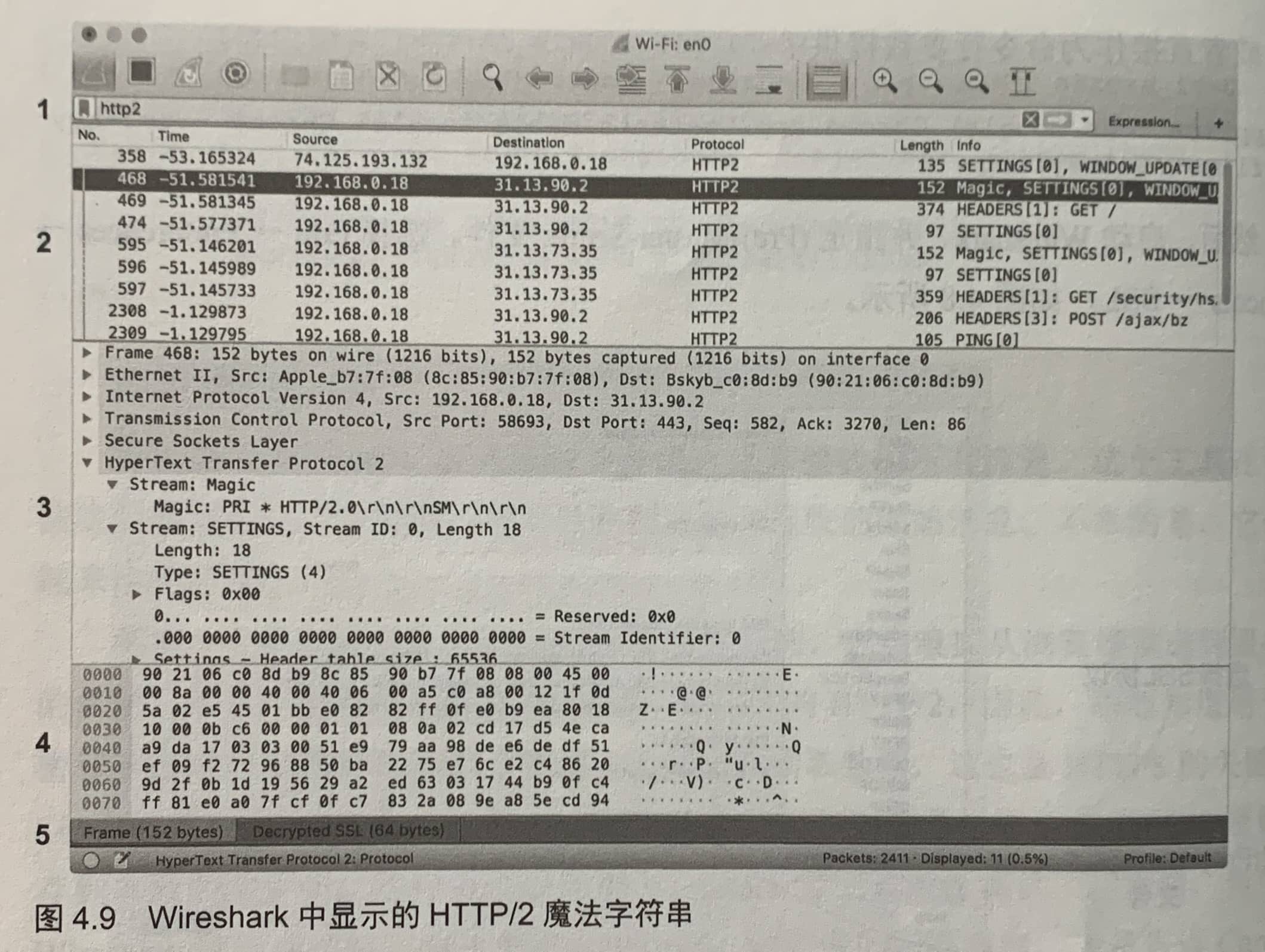
4.3.2 HTTP/2数据格式
每个HTTP/2帧由一个固定的长度的头部和不定长度的负载组成。
| 字段 | 长度 | 描述 |
|---|---|---|
| Length | 24bit | 帧载荷长度,不包括帧头部,最大为$2^{24}-1$个8为字节,这个数由SETTINGS_MAX_FRAME_SZIE限制,默认为$2^{14}$ |
| Type | 8bit | 帧类型标识 DATA:传输数据的帧,携带的负载为应用程序数据。 HEADERS:携带头部块的帧,用于在不同端点之间传输HTTP头部。 PRIORITY:携带优先级信息的帧,用于调整流的优先级。 RST_STREAM:用于向对端指示一个流已经异常终止。 SETTINGS:用于与对端协商各种连接和流相关的配置参数。 PUSH_PROMISE:用于向对端发送服务器推送请求的相关信息。 PING:用于在两个端点之间交换PING帧,以确定连接是否仍然存活。 GOAWAY:用于向对端指示整个连接已经终止,并发送最后一个流的标识符。 WINDOW_UPDATE:用于更新接收窗口或流窗口大小的帧。 CONTINUATION:用于在HEADERS帧或PUSH_PROMISE帧之后携带额外的头部块。 |
| Flags | 8bit | 标识此帧的特性 |
| Reserved | 1bit | 保留位,留待将来使用 |
| Stream Identifier | 31bit | 无符号的31位整数,流标识符,用于标识此帧的相关流 |
HTTP/2帧与可变长的HTTP/1文本消息不同,对于后者,必须通过扫描换行符和空格来解析——这个过程效率低且容易出错。HTTP/2帧格式更严格,定义更清晰。帧的解析更容易,需要传输的数据更少。
4.3.3 HTTP/2消息流示例
ngttp -va https://xxx.com | more,-n参数可以隐藏数据,仅显示帧头部。
[ 0.143] Connected
The negotiated protocol: h2
[ 0.156] send SETTINGS frame <length=12, flags=0x00, stream_id=0>
(niv=2)
[SETTINGS_MAX_CONCURRENT_STREAMS(0x03):100]
[SETTINGS_INITIAL_WINDOW_SIZE(0x04):65535]
[ 0.156] send PRIORITY frame <length=5, flags=0x00, stream_id=3>
(dep_stream_id=0, weight=201, exclusive=0)
[ 0.156] send PRIORITY frame <length=5, flags=0x00, stream_id=5>
(dep_stream_id=0, weight=101, exclusive=0)
[ 0.156] send PRIORITY frame <length=5, flags=0x00, stream_id=7>
(dep_stream_id=0, weight=1, exclusive=0)
[ 0.156] send PRIORITY frame <length=5, flags=0x00, stream_id=9>
(dep_stream_id=7, weight=1, exclusive=0)
[ 0.156] send PRIORITY frame <length=5, flags=0x00, stream_id=11>
(dep_stream_id=3, weight=1, exclusive=0)
[ 0.156] send HEADERS frame <length=35, flags=0x25, stream_id=13>
; END_STREAM | END_HEADERS | PRIORITY
(padlen=0, dep_stream_id=11, weight=16, exclusive=0)
; Open new stream
:method: GET
:path: /
:scheme: https
:authority: juejin.cn
accept: */*
accept-encoding: gzip, deflate
user-agent: nghttp2/1.50.0
[ 0.166] recv SETTINGS frame <length=18, flags=0x00, stream_id=0>
(niv=3)
[SETTINGS_MAX_CONCURRENT_STREAMS(0x03):128]
[SETTINGS_INITIAL_WINDOW_SIZE(0x04):65536]
[SETTINGS_MAX_FRAME_SIZE(0x05):16777215]
[ 0.167] recv WINDOW_UPDATE frame <length=4, flags=0x00, stream_id=0>
(window_size_increment=2147418112)
[ 0.167] recv SETTINGS frame <length=0, flags=0x01, stream_id=0>
; ACK
(niv=0)
[ 0.167] send SETTINGS frame <length=0, flags=0x01, stream_id=0>
; ACK
(niv=0)
[ 0.312] recv (stream_id=13) :status: 200
[ 0.312] recv (stream_id=13) server: Tengine
[ 0.312] recv (stream_id=13) content-type: text/html; charset=utf-8
[ 0.312] recv (stream_id=13) date: Mon, 06 Mar 2023 21:48:55 GMT
[ 0.312] recv (stream_id=13) x-powered-by: Express
[ 0.312] recv (stream_id=13) x-tt-logid: 202303070548550C248DCEE6BA9E6D39E7
[ 0.312] recv (stream_id=13) etag: "ea19-BdCjb1B4v8VeGjRf36CQk10o0EY"
[ 0.312] recv (stream_id=13) accept-ranges: none
[ 0.312] recv (stream_id=13) server-timing: inner; dur=95, pp;dur=10, total;dur=91;desc="Nuxt Server Time"
[ 0.312] recv (stream_id=13) vary: Accept-Encoding
[ 0.312] recv (stream_id=13) content-encoding: gzip
[ 0.312] recv (stream_id=13) x-tt-trace-host: 01e622115b212264ec059bc5cfea04679a25deb8faa7daafe3987b93ece8672f582e17efae85ab142a777f859a9207004d14b68567506a73a2cfed3ff50108d6feed271fbfd27860f59cf9a22c0d4f0e1a
[ 0.312] recv (stream_id=13) x-tt-trace-tag: id=3;cdn-cache=miss
[ 0.312] recv (stream_id=13) x-tt-timestamp: 1678139335.947
[ 0.312] recv (stream_id=13) via: cache44.l2cn1850[136,0], ens-cache17.cn4460[142,0]
[ 0.312] recv (stream_id=13) timing-allow-origin: *
[ 0.312] recv (stream_id=13) eagleid: 0ed7392516781393358267505e
[ 0.312] recv HEADERS frame <length=486, flags=0x04, stream_id=13>
; END_HEADERS
(padlen=0)
; First response header
[ 0.312] recv DATA frame <length=8192, flags=0x00, stream_id=13>
[ 0.312] recv DATA frame <length=4039, flags=0x00, stream_id=13>
[ 0.312] recv DATA frame <length=0, flags=0x01, stream_id=13>
; END_STREAM
[ 0.312] send GOAWAY frame <length=8, flags=0x00, stream_id=0>
(last_stream_id=0, error_code=NO_ERROR(0x00), opaque_data(0)=[])
nghttp不输出HTTPS建立过程和HTTP/2前奏/“魔术”消息。
SETTINGS帧
SETTINGS帧是服务器和客户端必须发送的第一个帧(在HTTP/2前奏/“魔术”消息之后)。该帧不包含数据,或只包含若干键值对。


| 参数名称 | 参数ID | 默认值 | 含义 |
|---|---|---|---|
| SETTINGS_HEADER_TABLE_SIZE | 1 | 4096 | 指定动态表大小的上限,用于存储在头字段中的键值对。 |
| SETTINGS_ENABLE_PUSH | 2 | 1 | 指定服务器是否可以向客户端推送资源。 |
| SETTINGS_MAX_CONCURRENT_STREAMS | 3 | 无限制 | 指定一个端点可以并行处理的最大流数。 |
| SETTINGS_INITIAL_WINDOW_SIZE | 4 | 65535 | 指定流级别初始窗口大小。 |
| SETTINGS_MAX_FRAME_SIZE | 5 | 16384 | 指定每个帧有效载荷的最大大小。 |
| SETTINGS_MAX_HEADER_LIST_SIZE | 6 | 无限制 | 指定每个端点可以接收的最大头块大小。 |
SETTINGS帧仅定义一个可在公共帧首部中设置的标志:ACK(0x1)。如果HTTP/2连接的这一端正在发起设置,则将此标准位设置为0;当确认另一端发送的设置消息时,将其设置为1。如果是确认帧,则不应在负载中包含其他设置。
流ID 0是保留数字,用于控制消息(SETTINGS和WINDOW_UPDATE帧)。
[ 0.156] send SETTINGS frame <length=12, flags=0x00, stream_id=0>
(niv=2)
[SETTINGS_MAX_CONCURRENT_STREAMS(0x03):100]
[SETTINGS_INITIAL_WINDOW_SIZE(0x04):65535]
上面表示收到的SETTINGS帧有12个8位字节数据,niv=2表示有2个设置项,每个设置项16位(标识符)+32位(值)=48位即6字节,共12字节。
设置项可以是任意顺序。
[ 0.166] recv SETTINGS frame <length=18, flags=0x00, stream_id=0>
(niv=3)
[SETTINGS_MAX_CONCURRENT_STREAMS(0x03):128]
[SETTINGS_INITIAL_WINDOW_SIZE(0x04):65536]
[SETTINGS_MAX_FRAME_SIZE(0x05):16777215]
[ 0.167] recv WINDOW_UPDATE frame <length=4, flags=0x00, stream_id=0>
(window_size_increment=2147418112)
[ 0.167] recv SETTINGS frame <length=0, flags=0x01, stream_id=0>
; ACK
(niv=0)
[ 0.167] send SETTINGS frame <length=0, flags=0x01, stream_id=0>
; ACK
(niv=0)
确认SETTINGS帧长度为0,ACK为1。
WINDOW_UPDATE帧
[ 0.167] recv WINDOW_UPDATE frame <length=4, flags=0x00, stream_id=0>
(window_size_increment=2147418112)
该帧用于流量控制,比如限制发送数据的数量,防止接收端处理不完。在HTTP/1,由于只能有一个请求,利用的是TCP流量控制来处理发送速率的问题。在HTTP/2下,在同一个连接上有多个流,所以不能依赖TCP流量控制,必须自己实现针对每个流的减速方法。
WINDOW_UPDATE帧是一个简单的帧,没有任何标志位,只有一个值(和一个保留位)

如果流ID指定为0,则应用于整个HTTP/2连接。发送方必须跟踪每个流和整个连接。HTTP/2流量控制仅应用于DATA帧,所有其他类型的帧就算超出了窗口大小的限制也可以继续发送。
PRIORITY帧
[ 0.156] send PRIORITY frame <length=5, flags=0x00, stream_id=3>
(dep_stream_id=0, weight=201, exclusive=0)
[ 0.156] send PRIORITY frame <length=5, flags=0x00, stream_id=5>
(dep_stream_id=0, weight=101, exclusive=0)
[ 0.156] send PRIORITY frame <length=5, flags=0x00, stream_id=7>
(dep_stream_id=0, weight=1, exclusive=0)
[ 0.156] send PRIORITY frame <length=5, flags=0x00, stream_id=9>
(dep_stream_id=7, weight=1, exclusive=0)
[ 0.156] send PRIORITY frame <length=5, flags=0x00, stream_id=11>
(dep_stream_id=3, weight=1, exclusive=0)
上面这些代码给nghttp创建了几个流,使用不同的优先级。实际上,nghttp并不直接使用流3~11,通过dep_stream_id,它将其他流悬挂在开始时创建的流之下。使用之前创建的流的优先级,可以方便地对请求进行优先级排序,无须为每个后续新创建的流明确指定优先级。并非所有HTTP/2客户端都给流预定义优先级。

HEADERS帧
[ 0.156] send HEADERS frame <length=35, flags=0x25, stream_id=13>
; END_STREAM | END_HEADERS | PRIORITY
(padlen=0, dep_stream_id=11, weight=16, exclusive=0)
; Open new stream
:method: GET
:path: /
:scheme: https
:authority: juejin.cn
accept: */*
accept-encoding: gzip, deflate
user-agent: nghttp2/1.50.0
在HTTP/2中,并没有特定的帧类型,HEADERS帧中也没有GET / HTTP/1.1这种URL的概念,所有的东西都通过首部发送。HTTP/2定义了新的伪首部(以冒号开始),以定义HTTP请求中的不同部分。
:authority伪首部代替了原来HTTP/1.1的Host首部。HTTP/2伪首部定义严格,不像标准的HTTP首部那样可以在其中添加新的自定义首部。如果应用需要,还得用普通的HTTP首部,没有开头的冒号,barry: value。
还要注意的是,HTTP/2强制将HTTP首部名称小写。HTTP/1官方并不关注首部的大小写。HTTP首部的值可以包含不同的大小写字母,但是首部名不可以。HTTP/2对HTTP首部的格式要求也更严格。开头的空格、双冒号或者换行,在HTTP/2中都会带来问题,虽然大多数HTTP/1的实现可以处理这些问题。
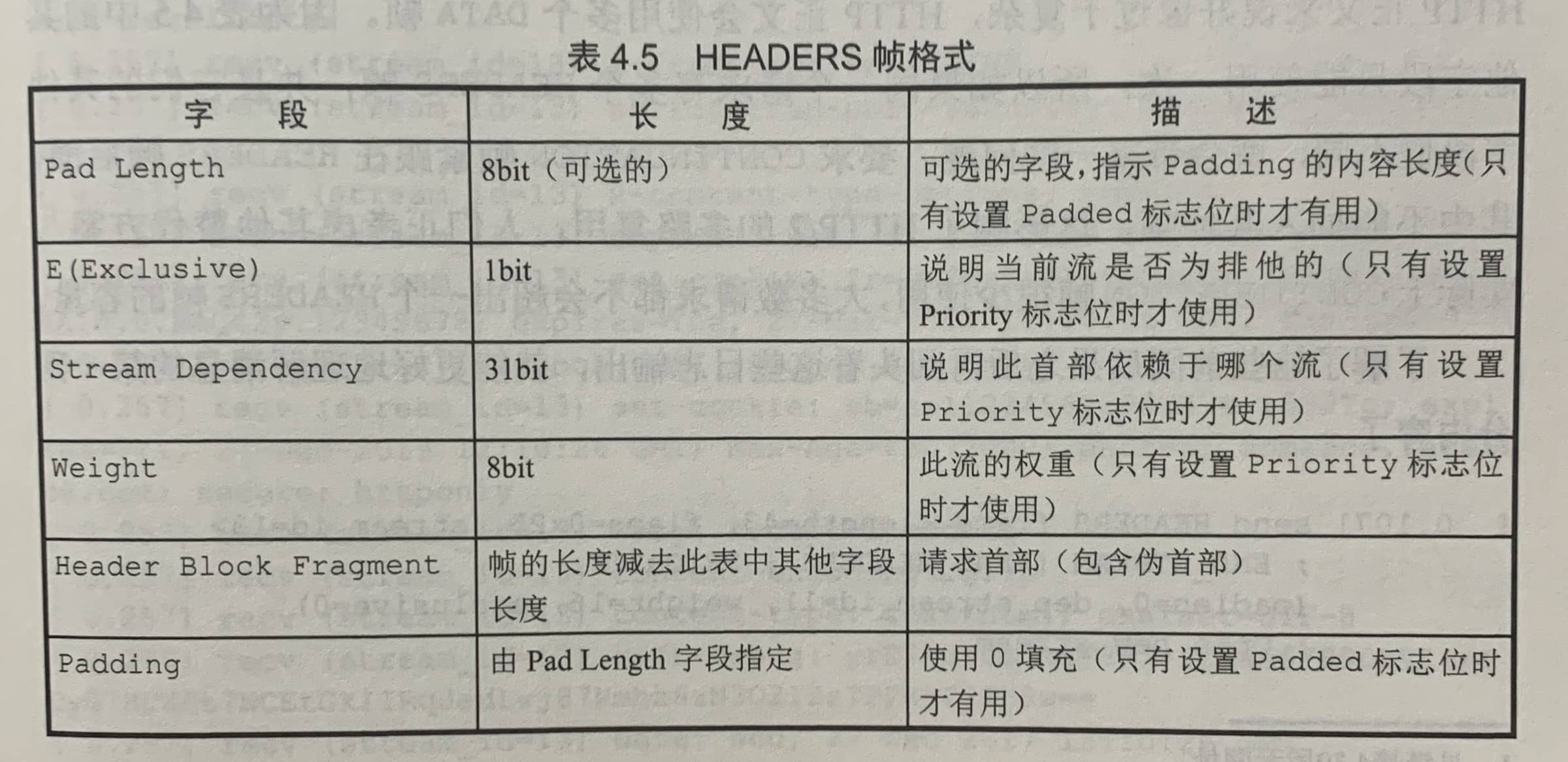
添加Pad Length和Padding字段是出于安全原因,用以隐藏真实的消息长度。Header Block Fragment(首部块片段)字段包含所有的首部(和伪首部)。这个字段不是纯文本,不像nghttp里所显示的那样。像nghttp这样的工具会自动解压HTTP首部。
HEADERS首部定义了4个标志位,可以在普通的帧首部中发送它们:
| 标志名称 | 标志位 | 含义 |
|---|---|---|
| END_STREAM | 0x1 | 指示此帧是流的最后一帧。当此标志位被设置时,表示此帧之后不会再发送与该流相关的帧。 |
| END_HEADERS | 0x4 | 指示此帧是头块的最后一帧。当此标志位被设置时,表示此帧是包含所有头字段的最后一帧。 |
| PADDED | 0x8 | 指示此帧的有效载荷包含填充字段。填充字段是用于填充头块或数据帧以达到指定大小的字节序列。此标志位仅适用于HEADERS和DATA帧。 |
| PRIORITY | 0x20 | 指示此帧包含优先级信息。优先级用于确定与该流关联的资源的相对重要性。此标志位仅适用于HEADERS帧。 |
如果HTTP首部尺寸超出一个帧的容量,则需要使用一个CONTINUATION帧(紧接着是一个HEADERS帧),而不是使用另外一个HEADERS帧。因为表4.5中的其他字段只能使用一次,所以如果同一个请求有多个HEADERS帧,并且它们的其他字段值不同,就会带来一些问题。要求CONTINUATION帧紧跟在HEADERS帧后面,其中不能插入其他帧,这影响了HTTP/2的多路复用,人们正在考虑其他代替方案。实际上CONTINUATION帧很少使用,大多数请求都不会超出一个HEADERS帧的容量。
[ 0.312] recv (stream_id=13) :status: 200
[ 0.312] recv (stream_id=13) server: Tengine
[ 0.312] recv (stream_id=13) content-type: text/html; charset=utf-8
[ 0.312] recv (stream_id=13) date: Mon, 06 Mar 2023 21:48:55 GMT
[ 0.312] recv (stream_id=13) x-powered-by: Express
[ 0.312] recv (stream_id=13) x-tt-logid: 202303070548550C248DCEE6BA9E6D39E7
[ 0.312] recv (stream_id=13) etag: "ea19-BdCjb1B4v8VeGjRf36CQk10o0EY"
[ 0.312] recv (stream_id=13) accept-ranges: none
[ 0.312] recv (stream_id=13) server-timing: inner; dur=95, pp;dur=10, total;dur=91;desc="Nuxt Server Time"
[ 0.312] recv (stream_id=13) vary: Accept-Encoding
[ 0.312] recv (stream_id=13) content-encoding: gzip
[ 0.312] recv (stream_id=13) x-tt-trace-host: 01e622115b212264ec059bc5cfea04679a25deb8faa7daafe3987b93ece8672f582e17efae85ab142a777f859a9207004d14b68567506a73a2cfed3ff50108d6feed271fbfd27860f59cf9a22c0d4f0e1a
[ 0.312] recv (stream_id=13) x-tt-trace-tag: id=3;cdn-cache=miss
[ 0.312] recv (stream_id=13) x-tt-timestamp: 1678139335.947
[ 0.312] recv (stream_id=13) via: cache44.l2cn1850[136,0], ens-cache17.cn4460[142,0]
[ 0.312] recv (stream_id=13) timing-allow-origin: *
[ 0.312] recv (stream_id=13) eagleid: 0ed7392516781393358267505e
[ 0.312] recv HEADERS frame <length=486, flags=0x04, stream_id=13>
; END_HEADERS
(padlen=0)
; First response header
HTTP响应在同一个流上也使用HEADERS帧发送。:status伪首部与HTTP/1.1不同(200 OK)。再次注意,它们在传输中不是这种文本格式。
尾随首部
HTTP/1.1引入了尾随首部的概念,可以在正文之后发送它。这些首部可以支持不能提前计算的信息。例如,在以流的形式传输数据时,内容的校验和或数字签名可以包含在尾随首部中。
实际上,尾随首部的支持很差,很少应用。但是HTTP/2决定继续支持它,所以一个HEADERS帧可能出现流的DATA帧之前或者之后。
DATA帧
在HEADERS帧之后是DATA帧,它用来发送消息体。在HTTP/1中,消息体在返回首部之后发送,前面有两个换行符(标记HTTP首部结束)。在HTTP/2中,数据部分使用不同的消息类型。在首部之后,可以发送一些正文内容,如其他流的部分数据、正文的更多内容等。将HTTP/2响应分到多个帧中,你可以在一个连接上同时进行多个流的传输。
[ 0.201] recv DATA frame <length=10, flags=0x00, stream_id=13>
<!doctype html>
<html data-n-head-ssr lang="zh" data-n-head="%7B%22lang%22:%7B%22ssr%22:%22zh%22%7D%7D">
<head >......
[ 0.207] recv DATA frame <length=4028, flags=0x00, stream_id=13>
[ 0.207] recv DATA frame <length=0, flags=0x01, stream_id=13>
; END_STREAM
DATA帧比较简单,它包含所需要的任何格式的数据:UTF-8编码、gzip压缩格式、HTML代码、JPEG图片的字节,什么都行。在帧首部中包含了长度,所以DATA帧自己的格式不需要包含长度字段。像HEADERS帧一样,DATA帧也支持使用内容填充来保护消息的长度,这是出于安全考虑。
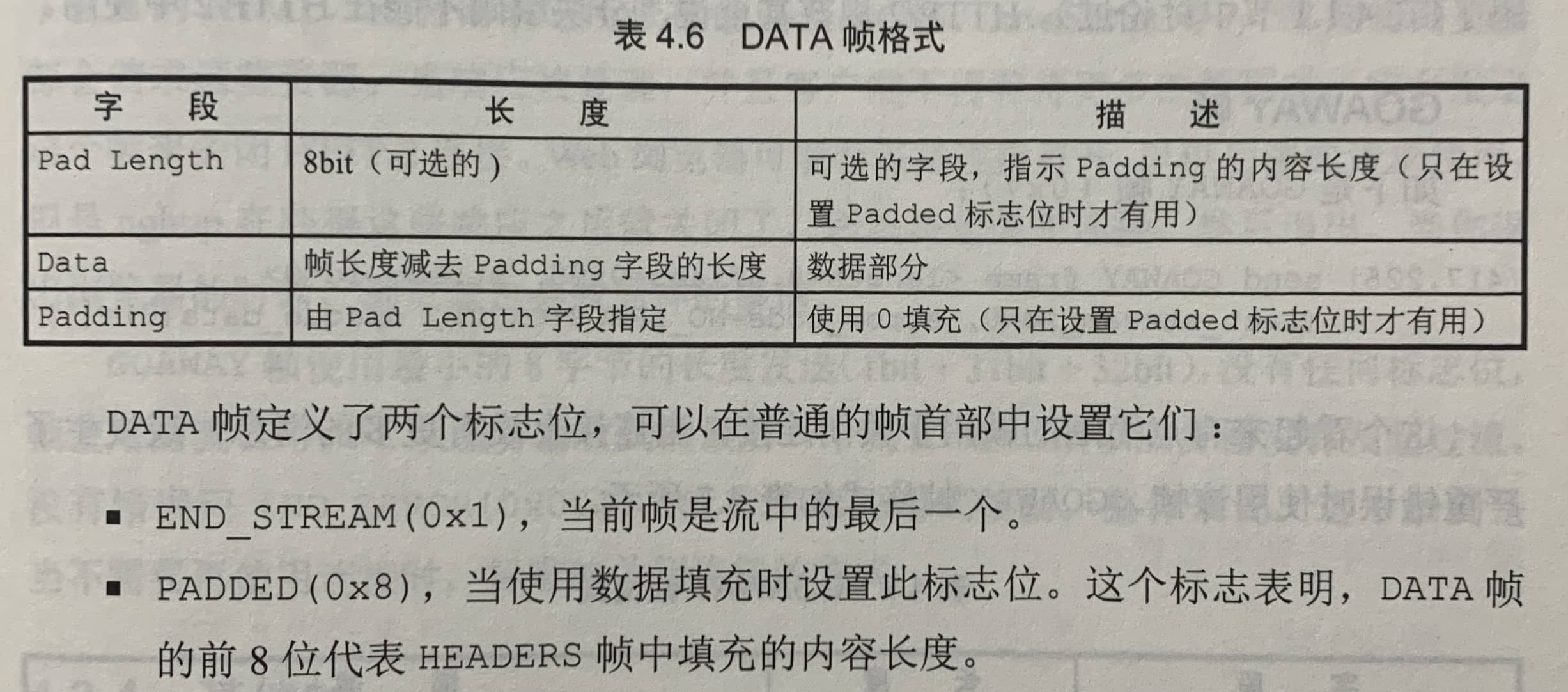
上面的代码通过多个DATA帧发送(nghttp贴心地解压了这些数据)。由于HTTP/2的DATA帧默认支持被分成多个部分,这就没有必要使用分块编码了。
GOAWAY帧
[ 0.312] send GOAWAY frame <length=8, flags=0x00, stream_id=0>
(last_stream_id=0, error_code=NO_ERROR(0x00), opaque_data(0)=[])
当连接上没有更多的消息,或发生了严重错误时使用该帧。
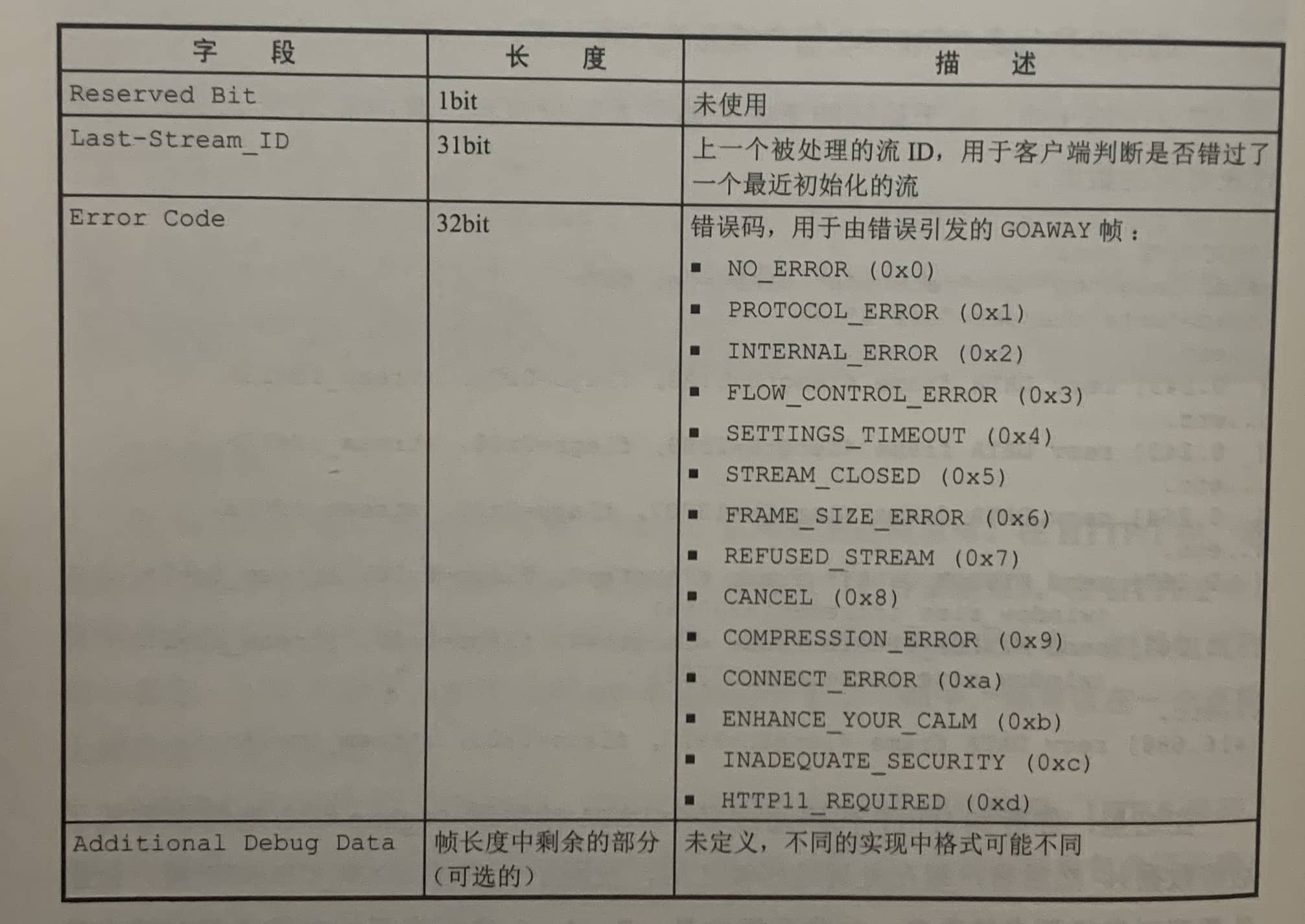
GOAWAY帧没有定义什么标志位。使用流ID为0.
客户端发出GOAWAY帧,不是从服务端接收它。当响应被处理,并且客户端不再等待更多的数据时,它会发送这个帧来关闭HTTP/2连接。Web浏览器可能会保持连接打开,以供后续的请求使用。
4.3.4 其他帧
CONTINUATION帧
CONTINUATION帧用于在HEADERS和PUSH_PROMISE帧中传输头块分片。当HEADERS或PUSH_PROMISE帧太大无法一次发送时,可以将头块分成多个CONTINUATION帧进行发送。每个CONTINUATION帧都必须有相同的流ID,并且必须紧随前面的HEADERS或PUSH_PROMISE帧。
PING帧
PING帧用于在客户端和服务器之间测试连接的可靠性。客户端或服务器可以发送PING帧,并期望收到对方的PING响应帧。PING帧的有效载荷为8字节,用于测试往返时间和检测连接是否仍然存在。
PUSH_PROMISE帧
PUSH_PROMISE帧用于在服务器推送模式下发送关联的响应。当服务器推送资源时,可以使用PUSH_PROMISE帧发送与该资源关联的头块和流ID。客户端可以使用该头块来构建响应,并将该响应与PUSH_PROMISE帧的流ID相关联。
| 字段 | 长度 | 描述 |
|---|---|---|
| Length | 24 bits | 帧载荷的长度,不包括帧头的9个字节 |
| Type | 8 bits | 帧类型,取值为0x5 |
| Flags | 8 bits | 标志位,取值为0x4或0x0 |
| Stream Identifier | 31 bits | 发起请求的流的标识符 |
| Promised Stream Identifier | 31 bits | 将被推送的流的标识符 |
| Header Block Fragment | 0或更多字节 | 分段的头部块数据 |
RST_STREAM帧
RST_STREAM帧用于在发生错误时关闭流。当发生错误时,可以使用RST_STREAM帧来通知对端关闭该流。例如,当客户端接收到无法解码的头块时,可以发送RST_STREAM帧来关闭该流。
| 字段 | 长度 | 描述 |
|---|---|---|
| Length | 24 bits | 帧载荷的长度,固定值为4 |
| Type | 8 bits | 帧类型,取值为0x3 |
| Flags | 8 bits | 标志位,固定值为0x0 |
| Stream Identifier | 31 bits | 标识被复位的流 |
| Error Code | 32 bits | 表示复位原因的错误码 |
ALTSC帧
它允许服务器通知客户端可以通过替代服务访问该资源。这可以让客户端在没有HTTP/2支持的情况下访问资源,或者使用不同的协议或端口等。
ORIGIN帧
它用于在HTTP/2连接中发送请求的源(Origin)信息。当浏览器向服务器发送请求时,可以通过ORIGIN帧将请求源的信息传递给服务器。这样服务器就可以根据请求源的不同返回不同的响应。
CACHE_DIGEST帧
它用于在HTTP/2连接中传递响应的缓存摘要信息。CACHE_DIGEST帧的使用可以帮助缓存服务器在本地缓存响应时更有效地利用缓存资源。CACHE_DIGEST帧的使用需要缓存服务器和代理服务器的支持。
第5章 实现HTTP/2推送
5.1 什么是HTTP/2服务端推送
HTTP/2服务端推送允许服务器发回客户端未请求的额外资源。在HTTP/1中,如果页面需要显示额外的资源,那么浏览器必须下载初始页面,看它引用了哪些额外的资源,然后请求它们。HTTP/2多路复用技术允许在同一连接上并行请求所有资源,因为这样排队会减少。

这些往返催生了一些性能优化手段,如将样式通过<style>标签内联到HTML页面中,或类似的,通过<script>标签将JavaScript内联到HTML中。通过内联这些关键资源,浏览器可以在原始页面下载解析之后马上开始渲染,而不需要等待附加的关键资源。
内联资源也有缺点,对于CSS,通常只包含关键样式(初始绘制时所需要的样式),之后才会下载完整的样式表,以减少内联的代码量,防止页面过大。这个过程还会产生浪费。因为被内联在页面中,所以关键CSS在网站的每个页面中重复出现。如果它在CSS文件中,就可以被其他页面使用并缓存起来。
HTTP/2推送打破了HTTP“一个请求=一个响应”的惯例。它允许服务器使用多个返回来响应一个请求。

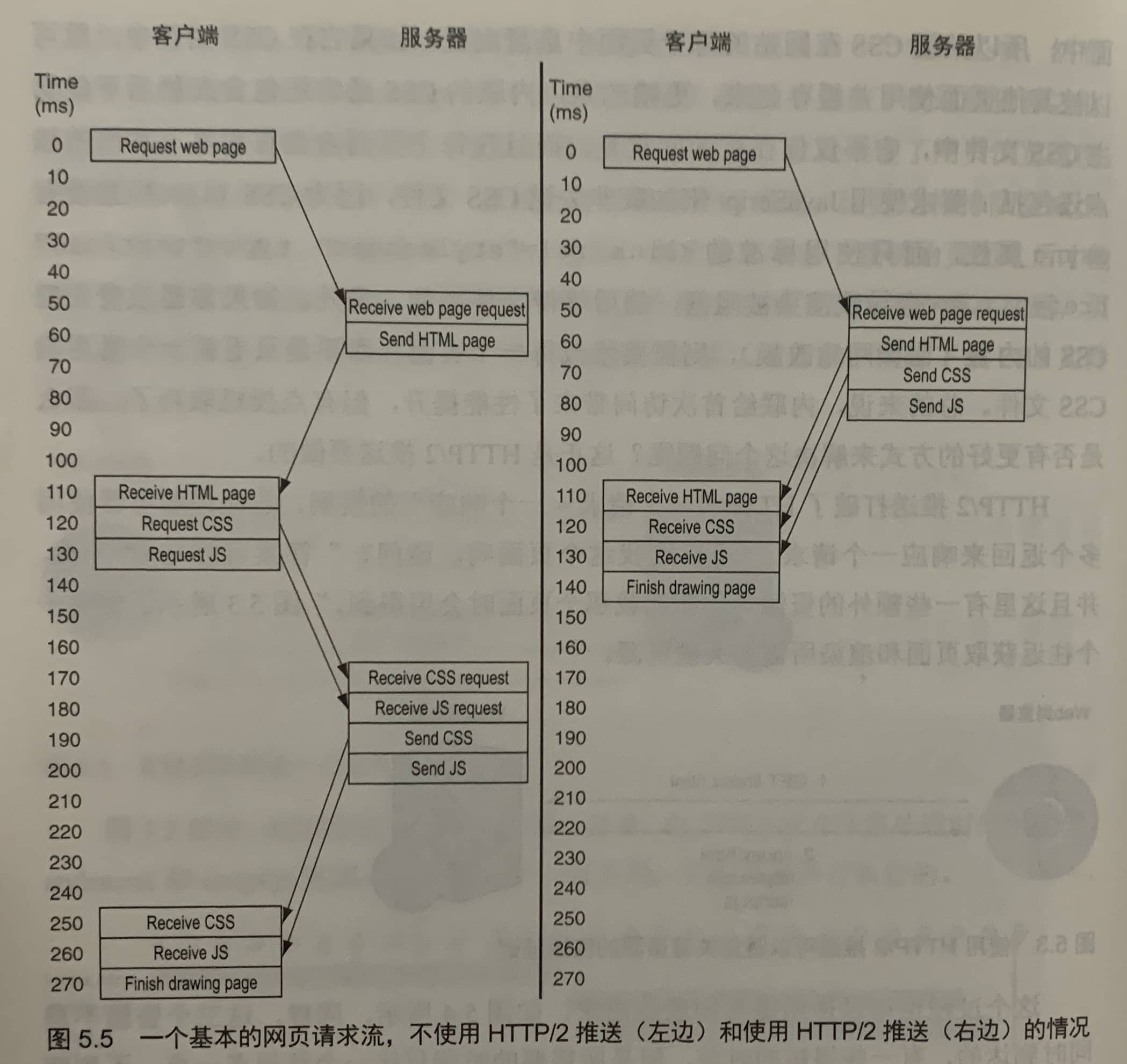
如果使用正确可以减少加载时间,但如果多推送了资源(客户端不需要或在缓存里),则将会延长加载时间,浪费带宽。
与WebSockets或SSE的区别
HTTP/2推送是单向流,完全由服务器来决定客户端是否需要资源。而WebSockets或SSE是双向流。
5.2 如何推送
如何推送取决于Web服务器,因为不是每个服务器都支持HTTP/2推送。
5.2.1 使用HTTP link首部推送
很多Web服务器(如Apache、Nginx和H2O)和一些CDN(如Cloudflare和Fastly)使用HTTP link首部通知Web服务器推送资源。如果Web服务器看到这些HTTP link首部,它将推送在首部中引用的资源。
// Apache语法
<IfModule mod_headers.c>
Header set Link "</css/styles.css>; rel=preload; as=style"
</IfModule>
// Nginx语法
location / {
add_header Link "</css/styles.css>; rel=preload; as=style";
}
5.2.2 查看HTTP/2推送

nghttp -anv https://www.tunetheweb.com/performance/命令会请求页面和所需要的所有静态资源(-a),不在屏幕上显示下载的数据(-n),但会打开更多的输出日志以显示HTTP/2帧(-v)。
[ 0.803] recv PUSH_PROMISE frame <length=73, flags=0x04, stream_id=13>
; END_HEADERS
(padlen=0, promised_stream_id=2)
PUSH_PROMISE帧由服务器发起并发送给客户端,promised_stream_id代表所要推送资源的流ID
[ 0.990] recv DATA frame <length=1291, flags=0x00, stream_id=13>
[ 0.990] recv DATA frame <length=1015, flags=0x01, stream_id=13>
; END_STREAM
[ 0.990] recv (stream_id=4) :status: 200
[ 0.990] recv (stream_id=4) date: Tue, 07 Mar 2023 22:21:43 GMT
[ 0.990] recv (stream_id=4) server: Apache
[ 0.990] recv (stream_id=4) strict-transport-security: max-age=31536000; includeSubDomains
[ 0.991] recv (stream_id=4) x-frame-options: DENY
[ 0.991] recv (stream_id=4) last-modified: Mon, 08 Feb 2021 07:45:17 GMT
[ 0.991] recv (stream_id=4) accept-ranges: bytes
[ 0.991] recv (stream_id=4) cache-control: max-age=10800, public
[ 0.991] recv (stream_id=4) expires: Wed, 08 Mar 2023 01:21:43 GMT
[ 0.991] recv (stream_id=4) vary: Accept-Encoding
[ 0.991] recv (stream_id=4) content-encoding: gzip
[ 0.991] recv (stream_id=4) x-content-type-options: nosniff
[ 0.991] recv (stream_id=4) referrer-policy: no-referrer-when-downgrade
[ 0.991] recv (stream_id=4) content-length: 1313
[ 0.991] recv (stream_id=4) content-type: application/javascript; charset=utf-8
[ 0.991] recv HEADERS frame <length=70, flags=0x04, stream_id=4>
; END_HEADERS
(padlen=0)
; First push response header
[ 0.991] recv DATA frame <length=1291, flags=0x00, stream_id=4>
[ 0.991] recv DATA frame <length=22, flags=0x01, stream_id=4>
; END_STREAM
5.2.3 使用link首部从下游系统推送
如果使用HTTP link首部来指示要推送的资源,则不需要再Web服务器的配置中设置这些首部。

如果这些应用服务器钱的We服务器支持基于link首部的HTTP/2推送,你就可以设置HTTP响应首部,然后应用服务器可以让Web服务器推送资源。
[ 0.804] recv (stream_id=13) link: </assets/css/common.css>;as=style;rel=preload
[ 0.804] recv (stream_id=13) link: </assets/js/common.js>;as=script;rel=preload
[ 0.804] recv (stream_id=13) content-type: text/html; charset=utf-8
5.2.4 更早推送
另外的做法可以使用Web服务器的指令或语法
// Apache
H2PushResoure add /assets/css/common.css
// Nginx
http2_push /assets/css/common.css
通过HTTP link首部直接推送的优势是,服务器不需要在推送前等资源返回一查看link首部。可以在服务器处理原始请求时推送依赖的资源。
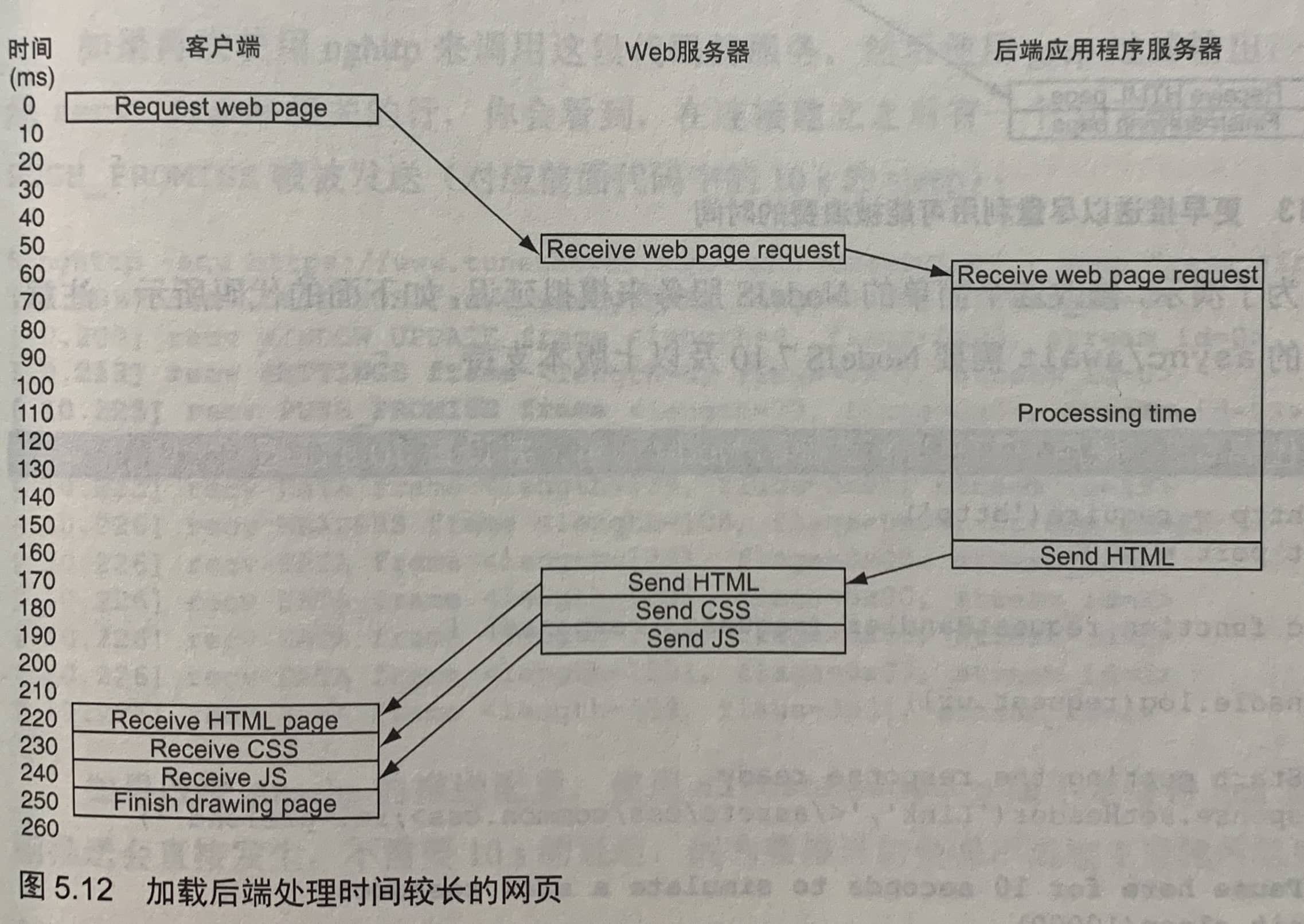
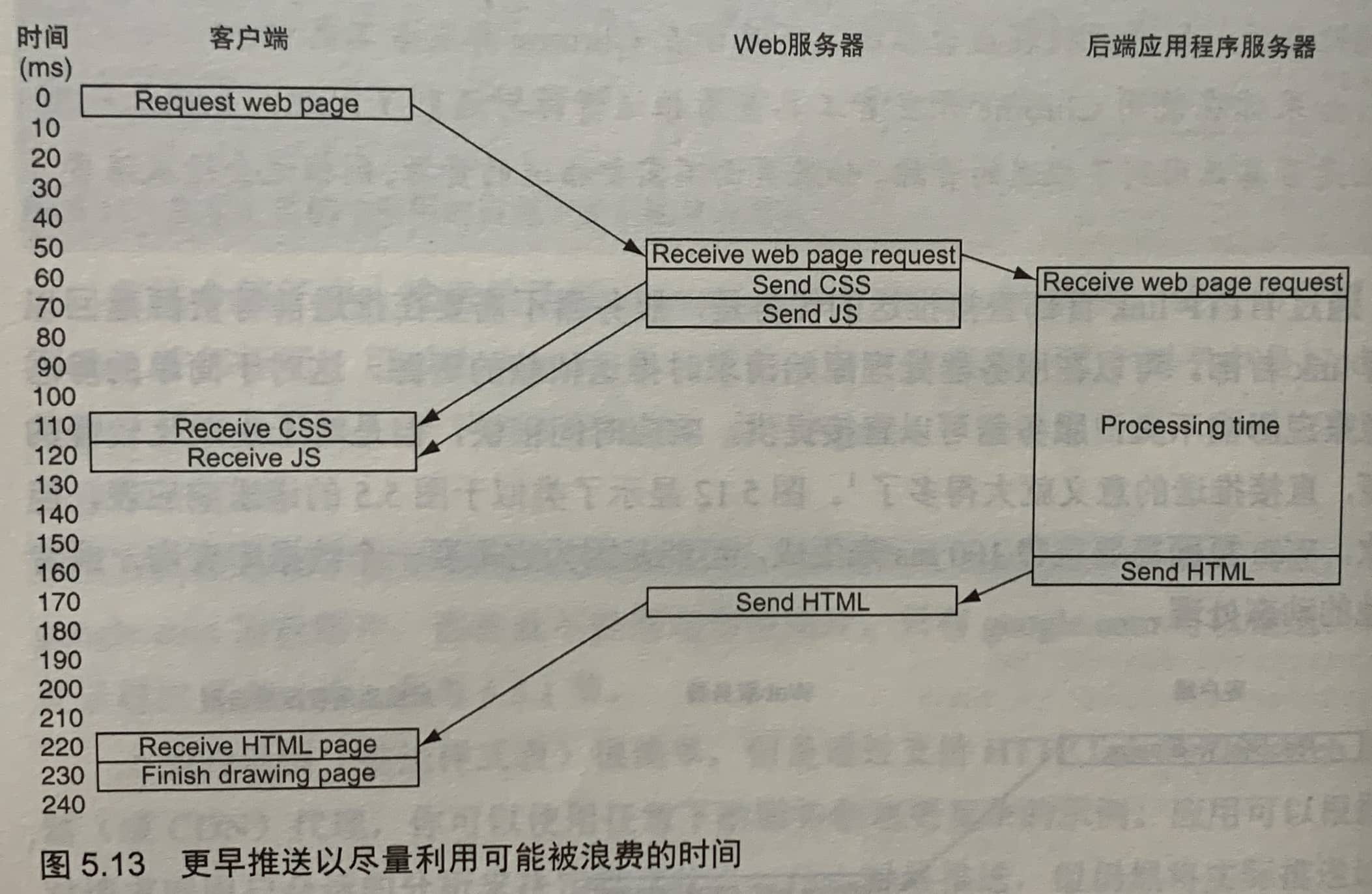
使用Web服务器的更早推送指令的缺点是不能再使用应用来发起这些推送,应用更应该决定是否要推送资源。为了解决这个问题,可以使用103 Early Hints状态码。后端服务器提前发起一个103响应,说页面需要CSS和JavaScript。

5.3 HTTP/2推送在浏览器中如何运作
在浏览器中,资源不是被直接推到网页中,而是被推到缓存中。当页面知道它需要什么资源时,它先查看缓存,如果发现缓存中有,就直接从缓存中加载,而不需要向服务端请求。大多数浏览器都通过一个特殊的HTTP/2推送缓存实现HTTP/2推送,跟大多数Web开发者都熟悉的HTTP缓存不同。
5.3.1 查看推送缓存如何工作
推送的资源存放在单独的内存中(HTTP/2推送缓存),等待浏览器请求,而后它们会被加载到页面中。如果设置了缓存首部,则在后来使用它们时它们照旧会被保存到浏览器的HTTP缓存中。要注意的是,基于Chromium的浏览器不会缓存不受信任的网站(比如自签名的证书,有一个红锁头提示)的资源。就算在浏览器提示时你坚持访问,还是不会使用缓存。要使用HTTP/2推送,必须得有一个绿色的所有,一个真实的证书,或者让你的浏览器信任你自签名的证书。
推送缓存不是浏览器查找资源的第一个地方,如果资源在HTTP缓存中,浏览器就不会使用被推送的资源,就算被推送的资源比缓存的资源更新。对于使用Service worker的网站来说,浏览器会在推送缓存之前检查Service worker缓存。
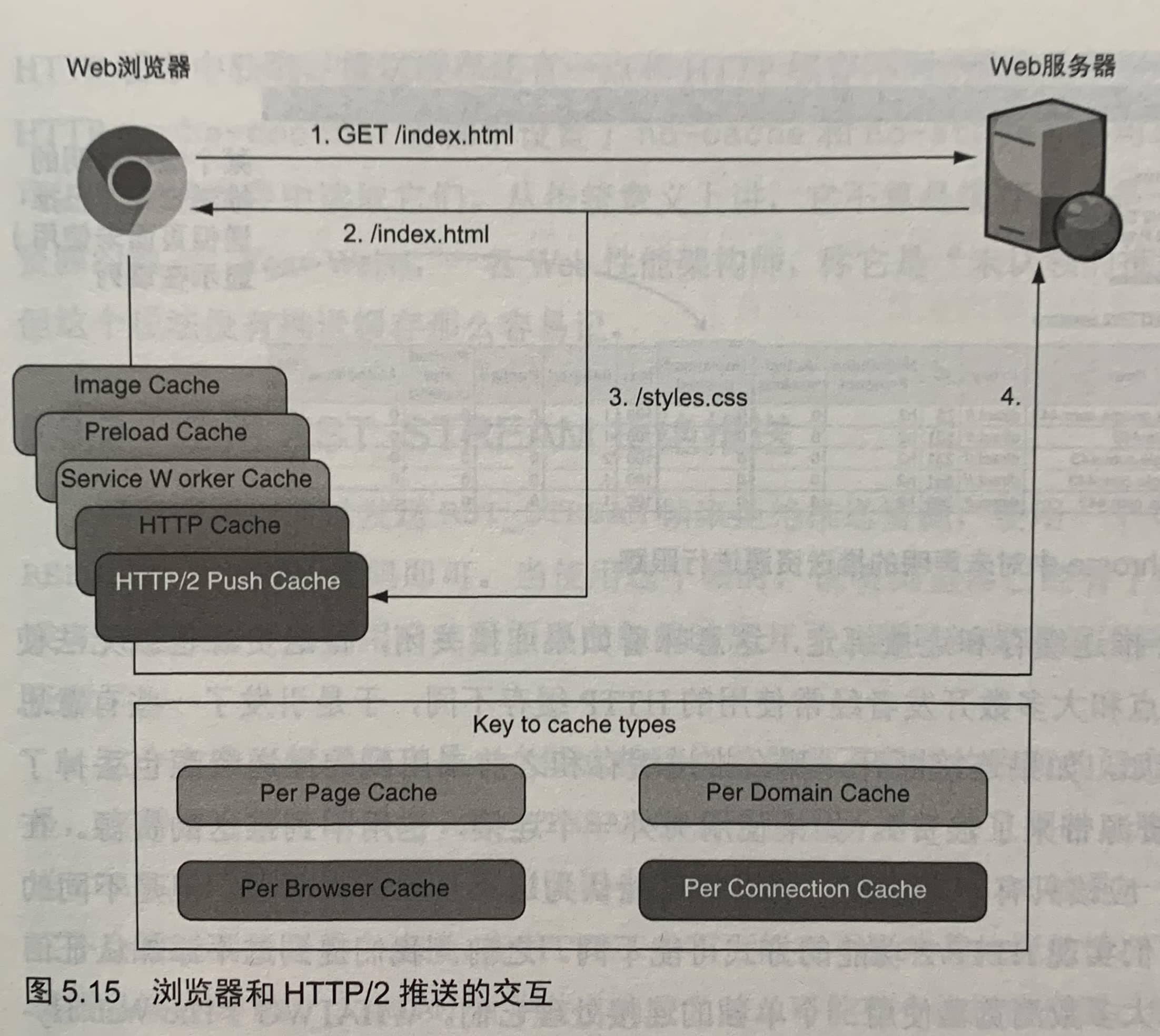
如上图,当页面请求发出去并收到响应时,推送的资源会被放到HTTP/2推送缓存中,然后一次检查各种缓存,最后向Web服务器发出请求。下面是每种缓存的简单解释:
- 图片缓存是一个短期的内存中的缓存。当页面多次引用一个图片时,它可以防止多次下载图片。当用户离开页面时,缓存被销毁。
- preload缓存是另外一种短期的内存中的缓存,它用来缓存预加载的资源。同样,这个缓存是跟页面绑定的。不要给另外一个页面预加载资源,因为它用不到。
- Service Workers是相当新的后台程序,它独立于网页运行,可以作为网页和网站的中间人。它可以让网站表现得更像原生应用,比如你可以在没有网络的时候运行。它们有自己的缓存和域名绑定。
- HTTP缓存是大多数开发者知道的主要缓存,它是一种基于磁盘的持久缓存,多个浏览器可以共享,每个域名使用有限的空间。
- HTTP/2推送缓存是一个短期的内存中的缓存,它和连接绑定,最后才使用它。
HTTP/2推送缓存和连接绑定,这意味着如果连接关闭,推送资源也就无法使用了。当资源从连接的推送缓存中被“认领”并拿出后,就不能再从推送缓存中使用它了。推送缓存还有一点和HTTP缓存不同,那就是不缓存的资源也可以被推送,并可以从推送资源中读取它们。
5.3.2 使用RST_STEAM拒绝推送
客户端可以通过发送RST_STREAM帧来拒绝推送资源。RST_STREAM帧是一个控制信号,它不会激进到断开整个连接。可能会出现在服务端收到RST_STREAM帧并做出响应之前,可能整个推送的资源已经发完了。
5.4 如何实现条件推送
服务器可以记录它在一个客户端的连接上推送过哪些资源。这项技术的实现取决于服务端,可以基于连接,或者会话ID等。
这个的缺点是服务端需要基于已有的数据猜测是否需要推送资源,如果请求经过负载均衡,服务端可能没有推送过资源的完整信息,因为一个客户端的请求可能会被均衡到不同的服务器上。
通过判断HTTP的缓存头部,如果判断有这个头部,就不推送,这个方法的缺点比如服务端也要对客户端的内容进行猜测,以及跳转到另外一个样式文件已缓存的页面时,可能会多推送资源。
使用Cookie或Storage来记录哪些资源已经被推送。当推送资源时,设置一个会话cookie,当页面中每个请求到达时,检查是否存在这个cookie。如果不存在就推送资源被设置cookie,反之亦然。缺点是cookie可以被单独重置(例如在浏览器中关闭cookie或者使用访客模式)。
目前cookie可能是跟踪资源是否已经被推送过且被缓存的最好的方法。
提议:缓存摘要,浏览器用它来告诉服务器缓存里有什么内容。当连接建立时,浏览器发送一个CACHE_DIGEST帧,列出当前域名的HTTP缓存中的所有资源。CACHE_DIGEST帧应该在连接建立之后尽快发送。缓存摘要只是一个提案,还没称为正式标准。人们对缓存摘要的一个顾虑是安全性,浏览器缓存可能包含敏感信息,如之前访问的URL,或者可能包含区分用户的信息等等。安全和隐私问题是停止缓存摘要标准化的另外一个原因。
5.5 推送什么
HTTP/2推送的基本规则:
- 在SETTINGS帧中将SETTINGS_ENABLE_PUSH设置为0,客户端可以禁用推送。此后,服务端不能使用PUSH_PROMISE帧。
- 推送请求必须使用可以缓存的方法(GET、HEAD或一些POST请求)。
- 推送请求必须是一些安全请求(GET或HEAD)。
- 推送请求不能包含请求体。
- 只将推送请求发送到权威服务器的域。
- 客户端不能推送,只有服务端可以。
- 资源可以在当前请求的响应中推送。如果没有请求,则服务端不可能发起一个推送。
由于这些规则,只有GET请求会被推送。由于权威性的限制,你只能推送服务器提供的资源。
HTTP/2推送是用来做性能优化的,应该只用来推送页面需要的关键资源,少推比多推更好。
5.8 对比推送和预加载
HTTP/2推送存在很多小问题,即使它能按预想的(经常不符合预期)工作。使用HTTP/2推送有明确的风险,比如会浪费带宽,或者降低网站的速度。一个主要问题是,服务器不知道浏览器缓存中有哪些资源,可能缓存摘要能解决这个问题,但前提是它能成为标准。
预加载可以告诉浏览器,页面需要一个资源,而不用等浏览器自己发现它需要这个资源。
在HTTP link中首部中:
Link: "</assets/css/common.css>;rel=preload;as=style;nopush"
在HTML中:
<link rel="preload" href="/assets/css/common.css" as="style">
当浏览器看到这行代码都应该以高优先级加载这个资源。在预加载资源时,as属性非常重要,没有这个属性,浏览器会忽略预加载暗示,或者资源被下载两次。
预加载没有HTTP/2推送name块,但是它是一个浏览器发起的请求,有一些优势:
- 浏览器知道缓存里有什么,然后它就知道是否要发出对应的请求。
- 使用预加载暗示,就没有那么多对推送缓存复杂性的担心,资源会被下载并缓存到HTTP缓存中。如果预加载的资源没有被使用到,下载它也是浪费了时间,这个与HTTP/2推送有同样的问题。
- 使用预加载从其他域加载资源。
- 不管预加载的资源有没有被用到,Chrome开发者工具都会有显示;HTTP/2推送的只有用到才会显示。
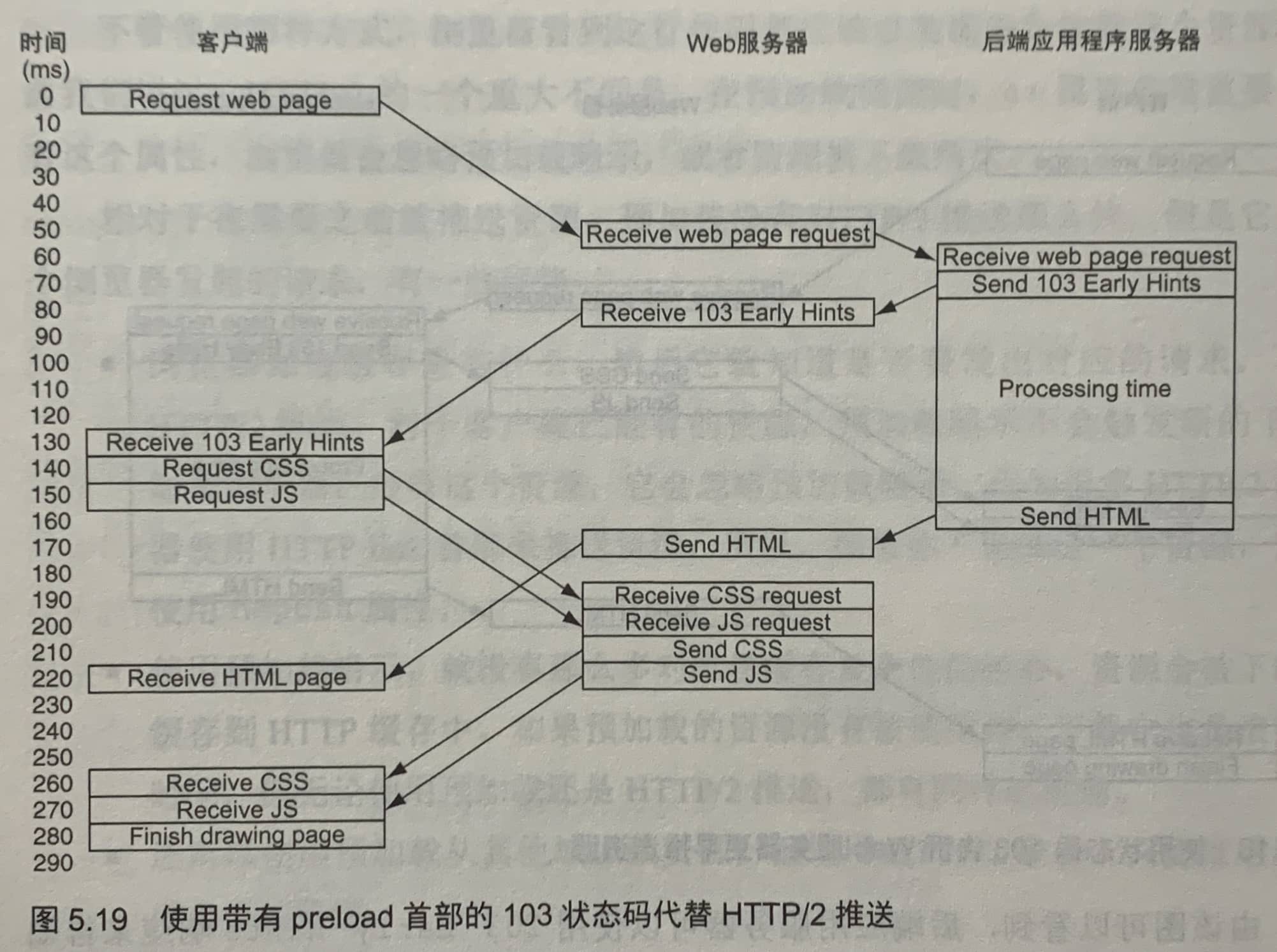
上图是一个使用103状态码配合预加载的案例,这个方法的优点是不太需要担心浪费带宽,因为浏览器会自动处理需要的资源,这在使用服务端生成页面的场景上性能提升效果有大一些。但目前浏览器对103状态码的支持还很差。
第6章 HTTP/2优化
6.2 一些HTTP/1.1优化方法是否成了反模式


6.2.3 越大的资源压缩越有效
在通过网络发送之前,应该压缩所有的Web资源。对于某些格式(如图片的JPEG和PNG,字体的WOFF和WOFF2),格式本身就实现了压缩,服务器不应该再次压缩。对于主要由文本组成的资源,如HTML、CSS和JavaScript,使用gzip(或更新的brotli)之类的压缩,通常由Web服务器自动处理。
几乎所有这些压缩格式,都有一个共同点,即压缩大文件比压缩小文件效果好。大多数压缩算法的实现都是找到数据中的重复部分,然后使用引用指向不重复的数据来减小数据大小。
HTTP/2可能不需要像HTTP/1.1那样有那么多的资源合并,但是在拆分文件之前要考虑一下带来的压缩率下降问题。
6.2.4 带宽限制和资源竞争
可以通过为请求设置正确的优先级来解决资源抢占问题。优先级策略在很大程度上不受站长的控制,但是它可能是浏览器和服务端性能有差别的关键因素。
6.2.5 域名分片
域名分配用来突破浏览器对每个域名设置的最多6个连接的限制。通过在不同的子域名或者其他的域名上托管资源,网站可以同时开启多个下载。但也许使用资源合并或精灵图是更好的方案。研究表明,很多额外的连接只用来加载一到两个资源,所以创建连接的开销比使用这种方法带来的收益要高。
在HTTP/2中,域名分片的意义没那么大,并且设置和管理这些额外的基础设施也是一种负担。所以,当HTTP/2应用更普遍的时候,应减少域名分片的使用。
6.2.6 内联资源
内联资源的缺点是这段代码要么跟后面加载的CSS文件有重复,要么不进缓存,导致网站后续的页面无法从缓存中使用它。同时,内联也是比较复杂的操作。HTTP/2中,内联可能还会作为常用性能优化手段存在一段时间,有些网站需要使用这种技术提升首次加载的性能。
6.3 在HTTP/2下依然有效的性能优化技术
由于Web的性质,网络性能优化很大程度上是优化网络层的应用。
6.3.1 减少要传输的数据量
使用合适的文件格式和大小
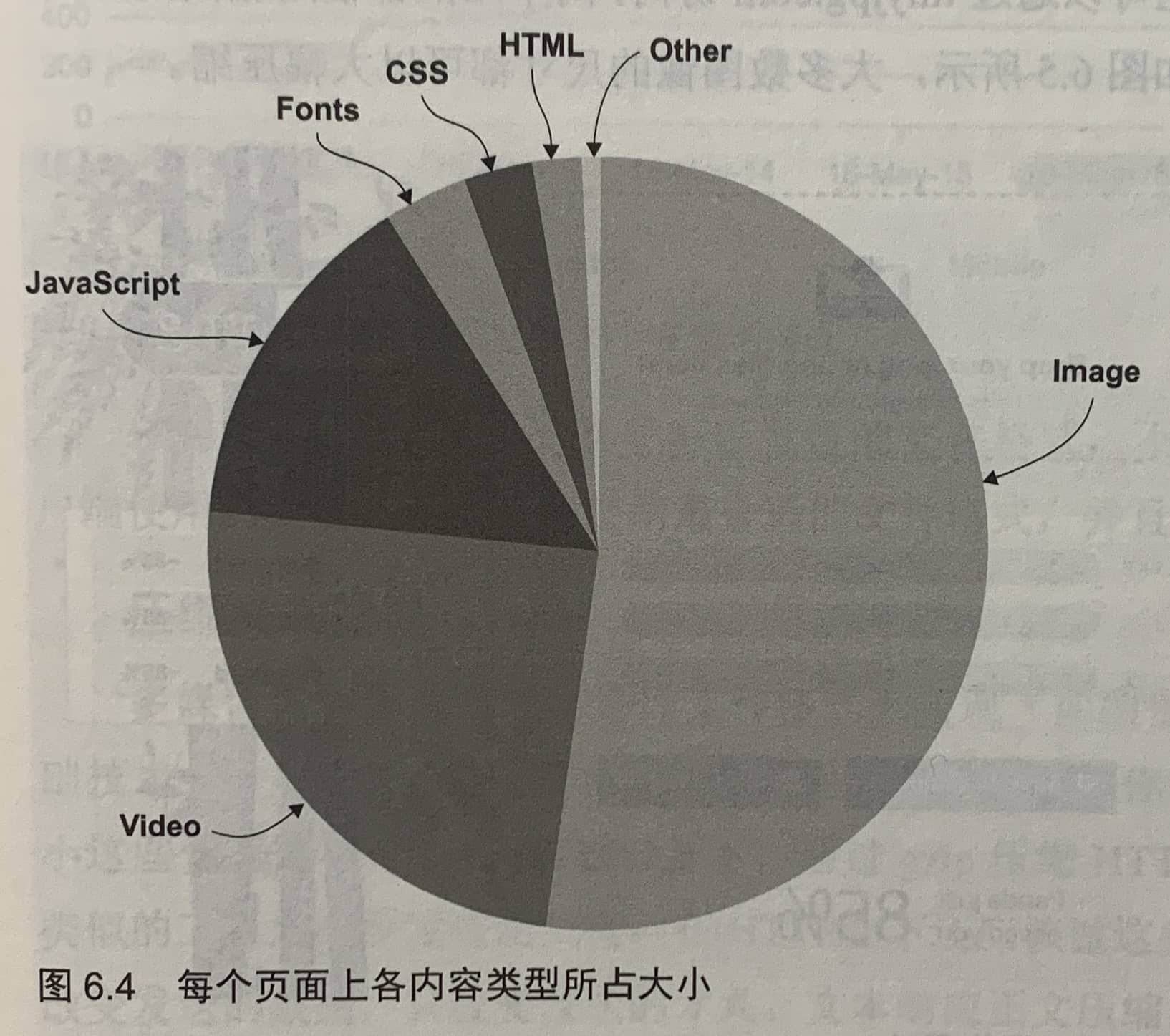
使用tinyping.com对JPEG和PNG图像进行压缩,以减少文件大小。除了查看图像质量,还应该考虑图像宽高。发送一个5120像素×2880像素的图像,却以100像素宽度显示,会浪费下载时间和浏览器的处理时间。绝不应该将大尺寸、原始尺寸的图像放在网页上。如果需要这些类型的图像,请提供单独的下载链接。
压缩文本数据
在HTTP/1.1下,通过gzip压缩HTTP消息体,或者使用其他工具来减少发送的数据,在HTTP/2下还应该做这些事情。
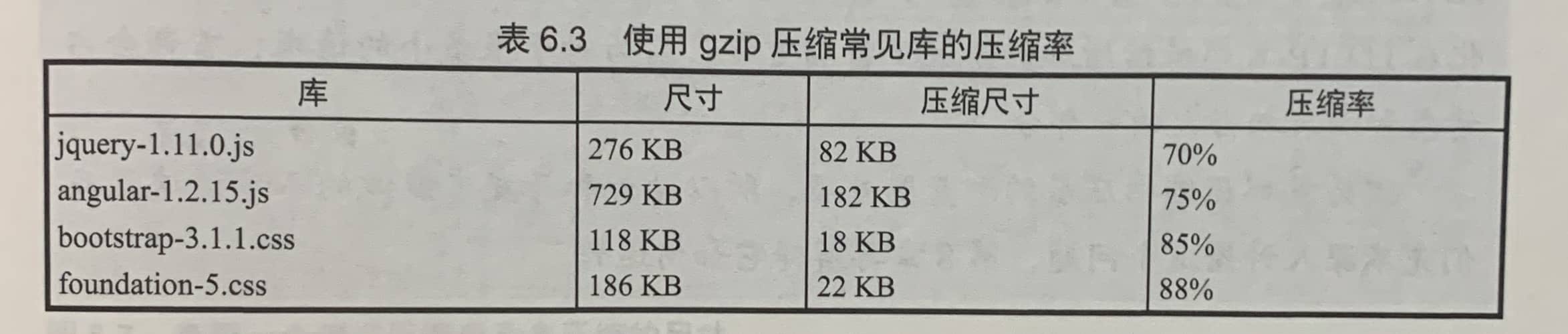
在发送前压缩数据的唯一缺点是,服务端要压缩,客户端要解压,这都需要花费时间和计算性能,但在主流硬件上,这个损耗几乎可以忽略不计。
gzip仍然是最流行的压缩技能,尽管brotli等压缩算法正变得越来越流行。brotli提供更好的压缩率(取决于设置),因此可以带来更多的收益。
当启用正文压缩时,内容编码会通过content-encodingHTTP首部告诉浏览器。
压缩HTTP首部
关于压缩,与HTTP/2有一点不同,那就是首部压缩。HTTP/1只允许压缩请求和响应的正文部分,然而通过HPACK,HTTP/2还能压缩HTTP首部。不适用HPACK,如果两个请求发送相同的数据,就需要发送两次相同的首部。
最小化代码
最小化HTML、CSS和JavaScript的代码。
与让Web服务器压缩文件相比,最小化代码的操作更加复杂,并且最小化相对于压缩的性能提升也比较少,需要权衡最小化代码的收益。
6.3.2 使用缓存防止重复发送数据
一个HTTP响应可能包含一个cache-control首部(或者更老的expires首部),用以说明资源缓存的有效期是多久。
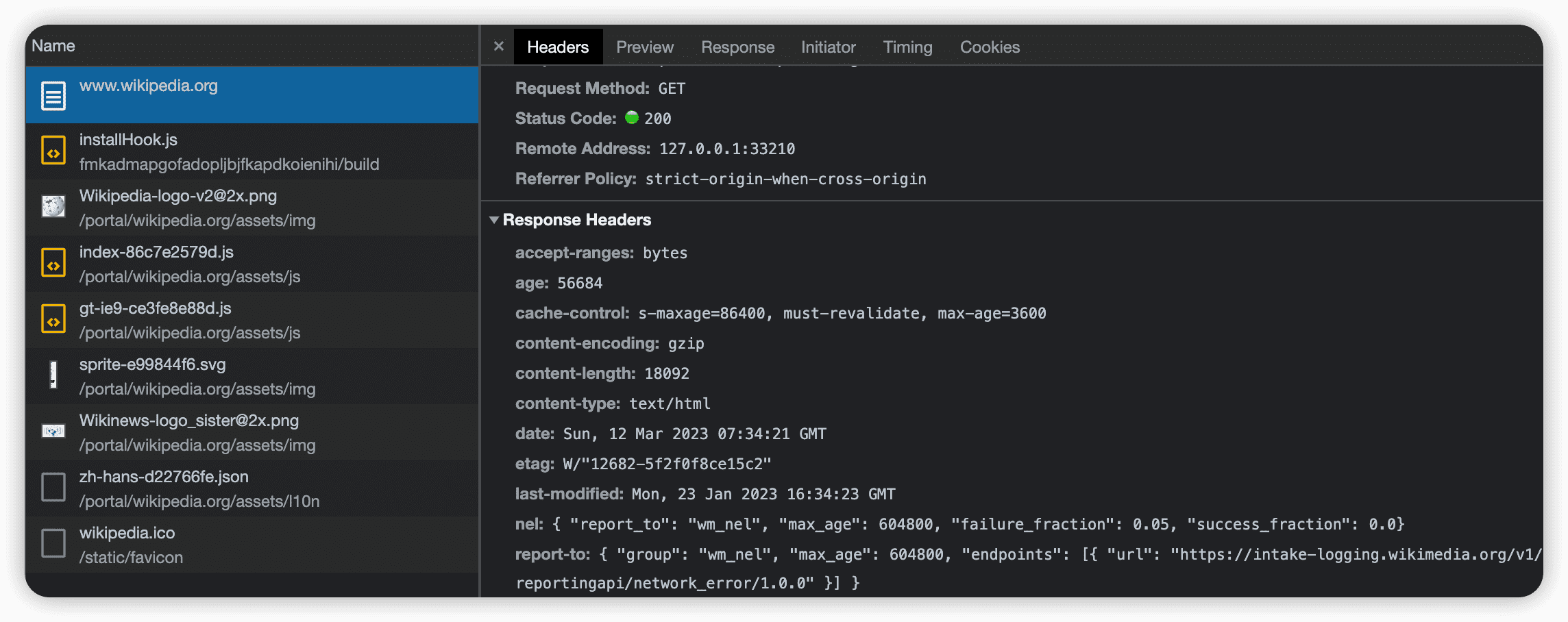
上图中,Wikipedia页面可以被缓存3600秒(max-age=3600)。
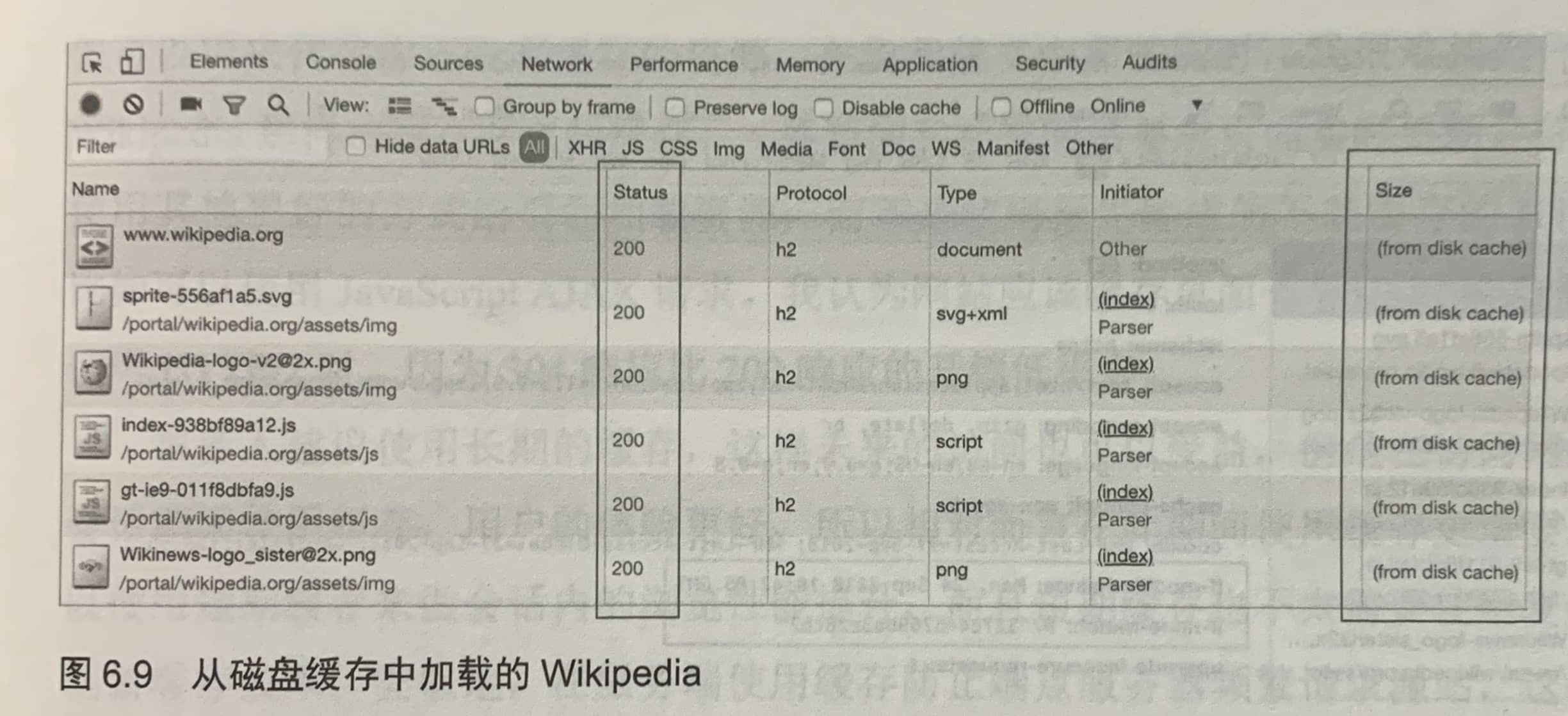
Size这一列的内容表明,从磁盘缓存中加载网站。如果看到from memory cache,而不是from disk cache,则说明你是从另外一个Wikkipedia页面,而不是从其他网站过来的,那这个时候相关的资源已经在最近的内存缓存中了。
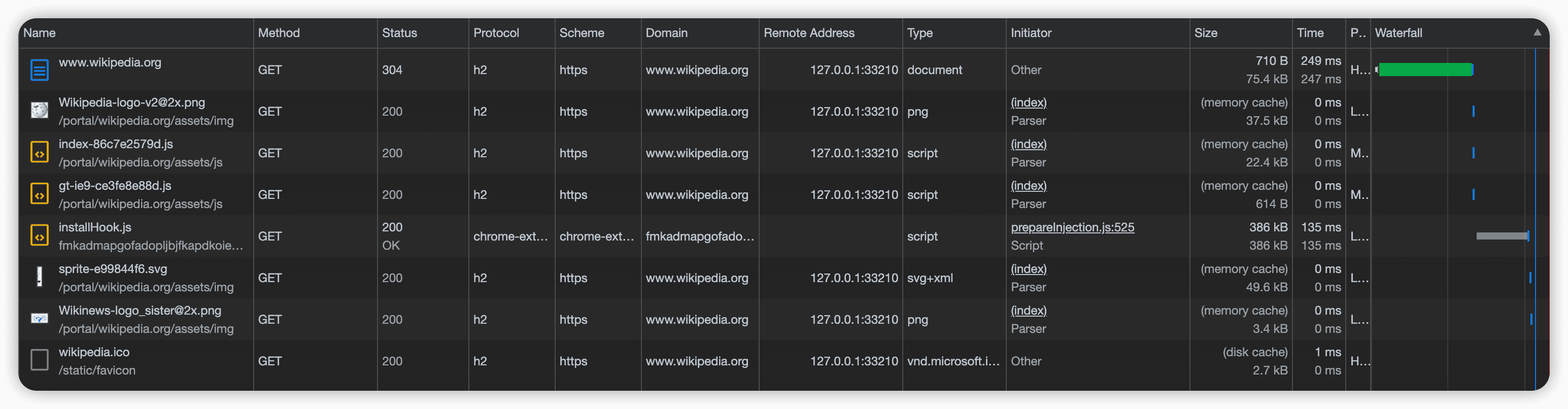
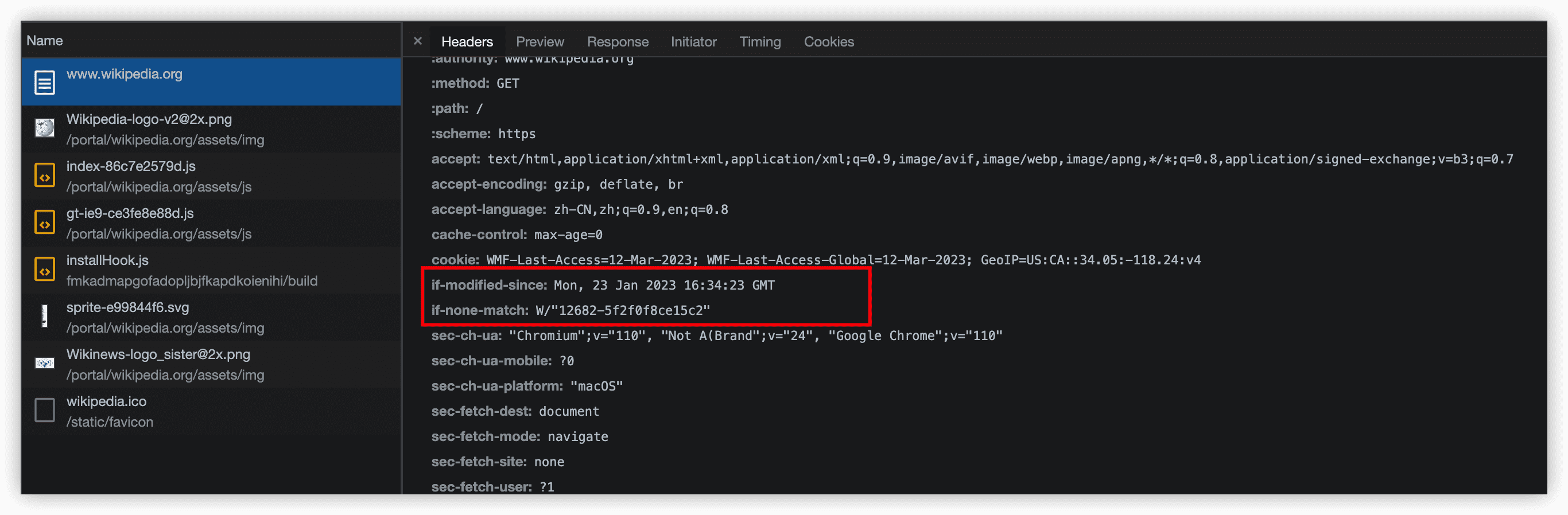
条件GET请求。如果同时提供两个值if-modified-since和if-none-match,则if-none-match首部中的eTag值更优先。协商缓存,服务器进行检查,看到页面没有更新,返回一个304响应,告诉浏览器持有的副本还可以使用。
304响应也有开销,它需要一次到服务器的完整网络调用。
6.3.3 Service Worker可以大幅减少网络加载
Service Worker支持在网页和网络之间添加一层JavaScript代理。
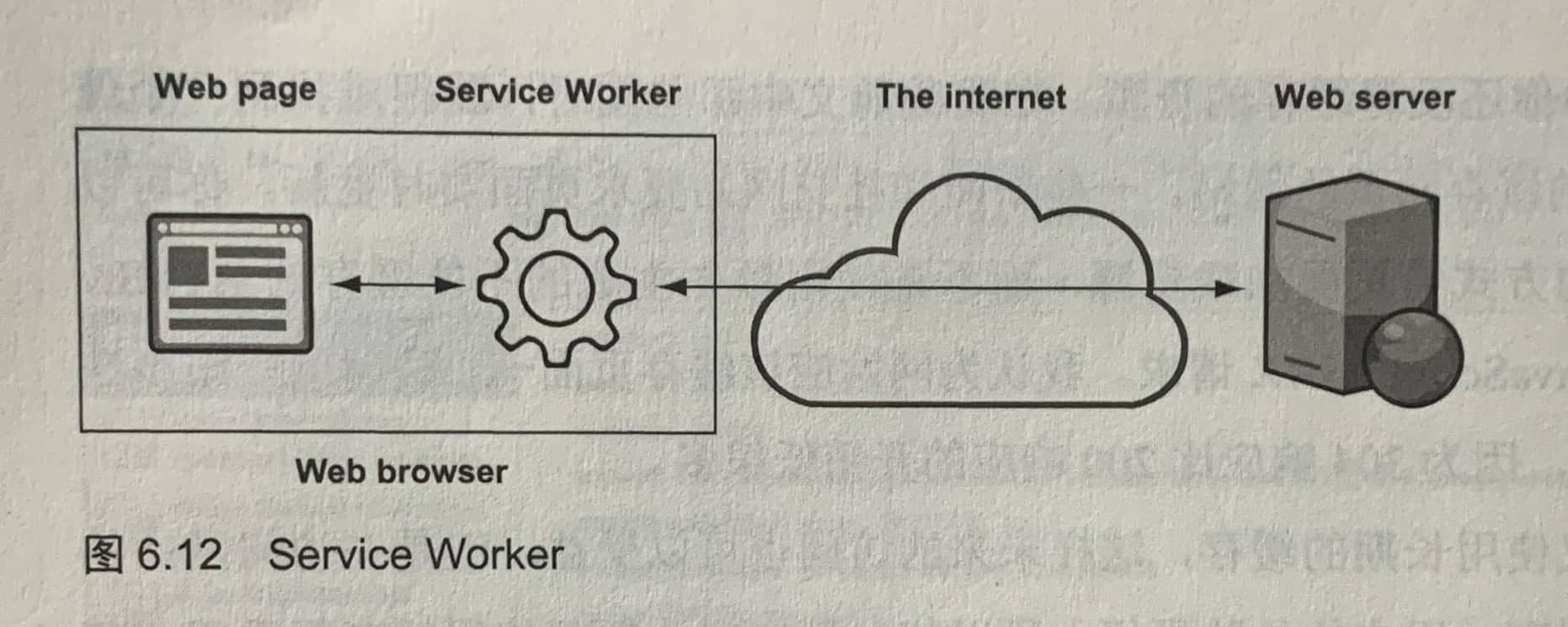
Service Worker可以查看、回复,或者更改HTTP请求。可以使用它提供类似本地移动应用的体验。当网站使用Service Worker时,Service Worker可以中断请求,当离线时,Service Worker可以返回一个之前缓存的资源版本。这就使得在离线时也能使用缓存的网站,像移动端应用一样。
Service Worker为在Web开发中优化HTTP端提供了多种方法。虽然使用较短的缓存周期,但是当资源过期时Service Worker并不从缓存中将其删除。这样我们可以使用304响应,而且不用担心长期缓存的问题。
6.3.4 不发送不需要的内容
确保只发送需要的数据。
6.3.5 HTTP资源暗示
- DNS Prefetch
<link rel='dns-prefetch' href='//m.media-amazon.com'>,这个暗示使DNS查询在需要连接之前发生,从而节省了建立连接的时间。- 这项技术对于不是从HTML中直接解析出来的、依赖其他资源的连接非常有用。
- PRECONNECT
- preconnect(提前连接)做了进一步延伸。它除了提前做DNS解析以外,还提前创建连接,这可以节省创建新的连接时的TCP和HTTPS开销。大多数当前主流的浏览器都对它提供了支持。
- PREFETCH
- prefetch(预取)用来加载低优先级的资源。preload试图让当前页面加载更快,而preftch通常用于给将来要访问的页面加载内容。因为它加载的资源的优先级很低,所以直到当前页面加载完成时它才会开始加载。它加载的资源会放到缓存中,方便后续使用。
- PRELOAD
- preload(预加载)告诉浏览器使用高优先级给本页加载资源。它是preconnect之后的一个本地步骤,但不像prefetch,它给当前页面加载资源。
- PRERENDER
- prerender是开销最大的资源暗示。使用它可以下载整个页面(包含页面需要的其他资源)并提前渲染。如果肯定会访问下一个页面,则可以直接把它加载了。Chrome正打算把它标记为不推荐使用,以后可能不再支持它。过渡使用prerender的风险很高,会浪费客户端的带宽和运算资源。
6.3.6 减少最后1公里的延迟
使用CDN,让服务器尽量离浏览器近一些。
6.3.7 优化HTTPS
整个世界都在向HTTPS迁移。HTTPS在过去几年获得了大幅增长,这主要是因为一些免费的证书颁发机构(如Let's Encrypt)和浏览器厂商(如Chrome和Firefox)也在推动HTTPS的发展。
SSLLabs Server Test用于做一个全面的HTTPS配置测试,这是一个HTTPS缺陷和最佳实践测试工具。
可以用SSLLabs工具扫码其他的网站,将它们的设置和自己的做对比。
6.4 同时对HTTP/1.1和HTTP/2做优化
计算HTTP/2流量,在Web服务器的日志文件里添加日志。
识别当前的连接是HTTP/1.1还是HTTP/2,并针对不同的协议版本返回不同的响应。
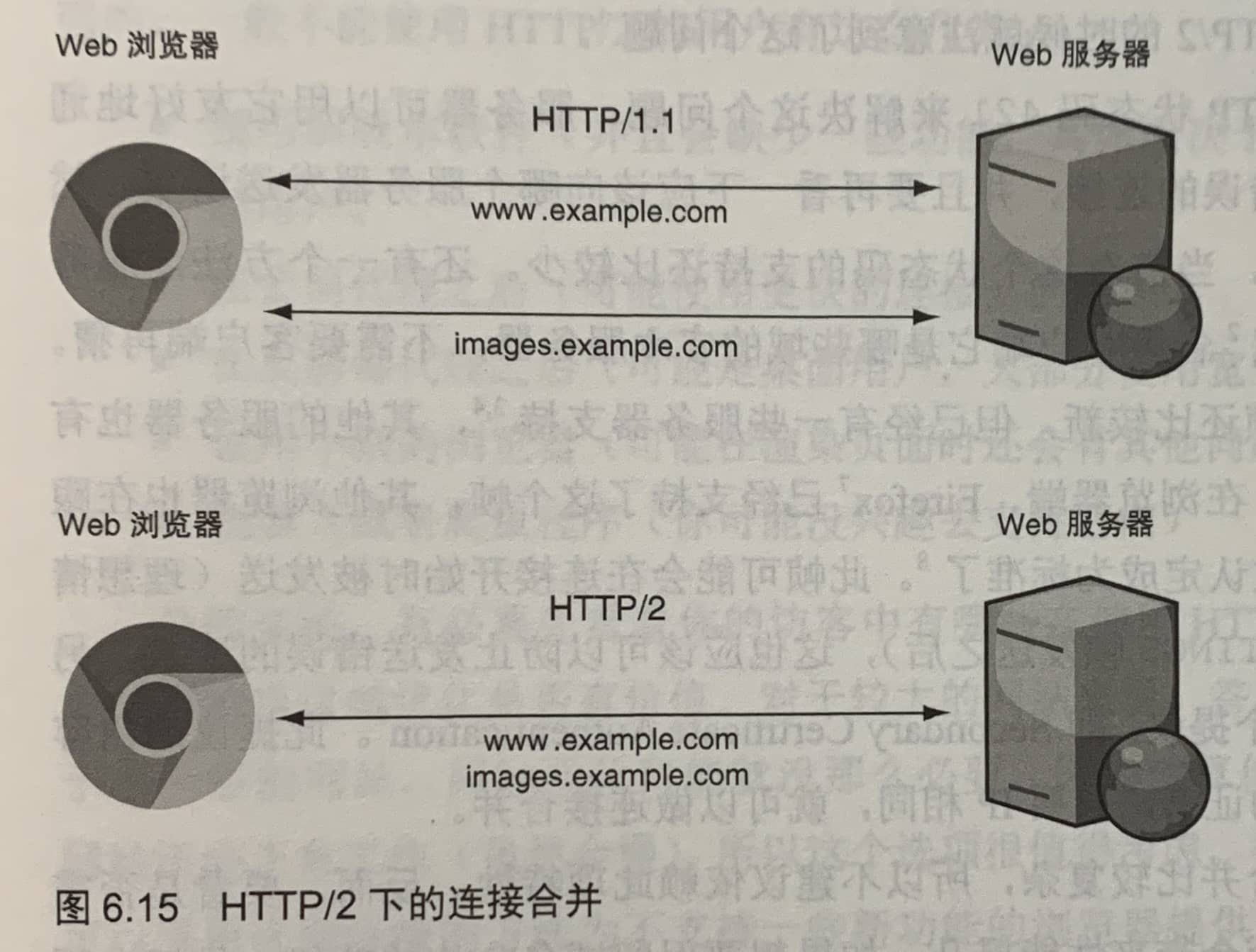
HTTP/2规范允许多个域名使用同一个HTTP/2连接,前提是它们是authoritative(官方)的域名,也就是这些域名被解析到同一个IP地址,并且HTTPS证书同时包含这些域名。
第3部分 HTTP/2进阶
第7章 高级HTTP/2概念
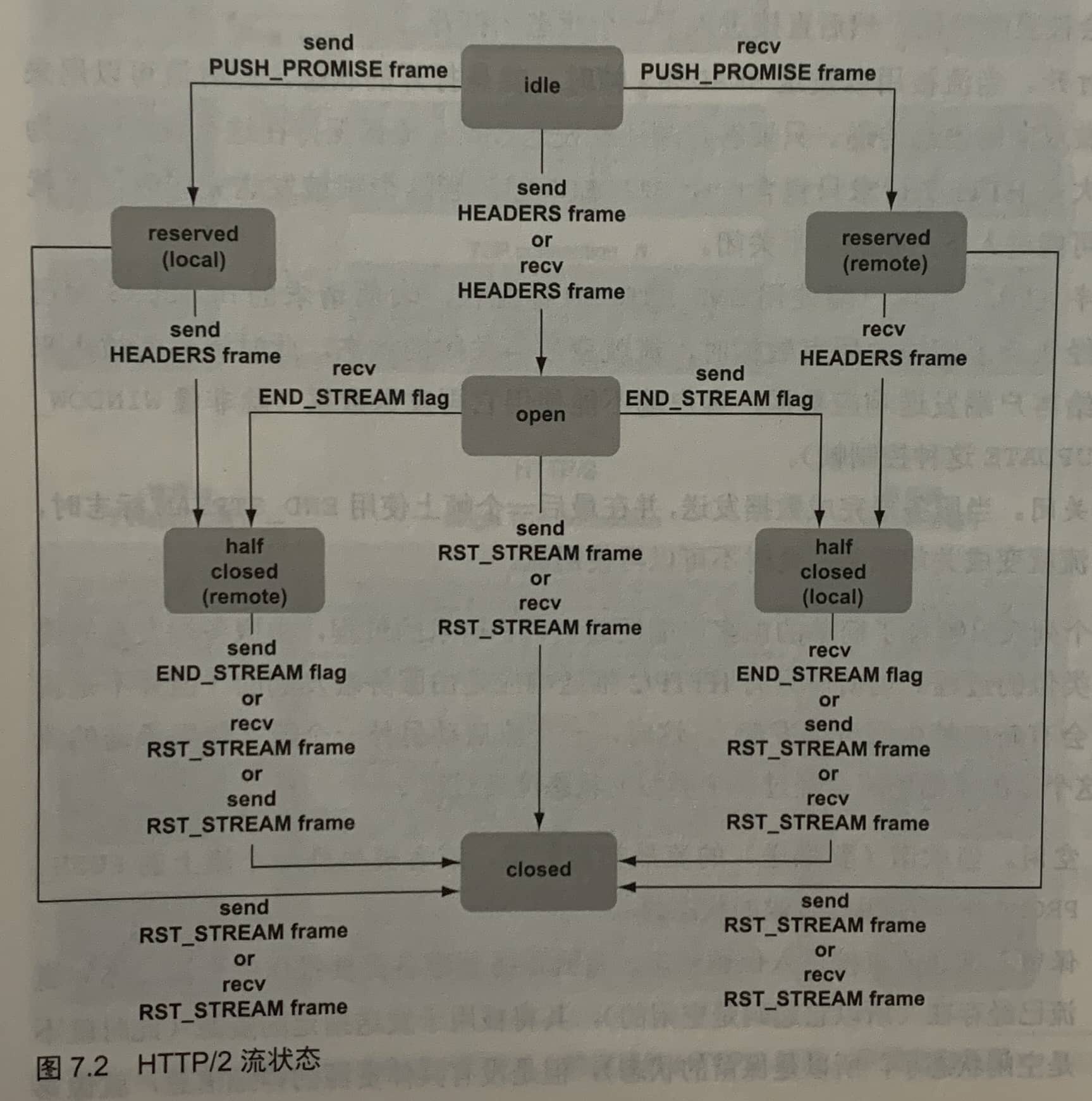
7.1 流状态
在流传输完它的资源之后,流会被关闭。当请求新资源时,会启用一个新的流。流是一个虚拟的概念,它是在每个帧上标志的一个数字,也就是流ID。所以关闭或创建于一个流的开销,远小于创建HTTP/1.1连接(包含TCP三次握手,可能还有HTTPS协议协商)的开销。实际上,HTTP/2连接比HTTP/1连接开销更高,因为在它上额外添加了“魔法”前奏消息,并在发送请求之前还至少要发送一个SETTINGS帧。但HTTP/2的流开销更低。
HTTP/2的流会经过一些生命周期状态。客户端发送HEADERS帧以开启一个HTTP请求(比如GET),服务器响应此请求,然后流结束。这个过程经历如下状态:
- 空闲。流刚被创建或者引用时的状态。实际上,大多数流处在这个状态的时间都很短,因为如果不想使用一个流,你也不会引用它,所以大多空闲的流会被直接使用,然后直接进入下一个状态:打开。
- 打开。当流被用以发送HEADERS帧时,就是打开的状态,此时流可以用来做双向的消息传递。只要客户端还在发送数据,流都保持这个状态。因为大多HTTP/2请求只包含一个HEADERS帧,当这个帧被发送完成时,流就可能进入下一个状态:半关闭。
- 半关闭。当客户端使用END_STREAM标志位,表明请求的HEADERS帧已经包含了请求的所有数据时,流就变成半关闭的状态,此时流只能被用来给客户端发送响应数据,客户端不能使用它再发送数据。
- 关闭。当服务器完成数据发送,并在最后一个帧上使用END_STREAM标志时,流就变成关闭状态,此时不可以再使用流。
7.2 流量控制
HTTP/1.1下流量控制不是必须的,因为不管何时最多只会有一个消息在传输,因此,可以使用传输层的TCP流量控制。在HTTP/2下,使用有多个流组成的多路复用的连接,只使用传输层的流量控制就不够了。不仅需要连接层的控制,还需要流层级的控制,比如你可能想要接收某一个流的更多数据。
HTTP/2中的流量控制和TCP方法类似。在连接开始时(使用SETTINGS帧),确定流量控制窗口大小(如果不指定,默认为65535个8位字节)。然后每次都会从总量中减去发送的数据的大小,而后再将接收到的响应数据(通过WINDOW_UPDATE帧)大小加回去。有一个连接层的流量控制窗口,它有点类似TCP流量控制窗口,而且每个流也有一个流量控制窗口。发送方能发送的数据最大值不超过最小的流量控制窗口(整个连接和单个流的窗口,都不能超出其大小)的大小。当流量控制窗口大小变为0的时候,发送方必须停止发送数据,直到接收到响应消息,告诉你其已将窗口大小更新为非0值。
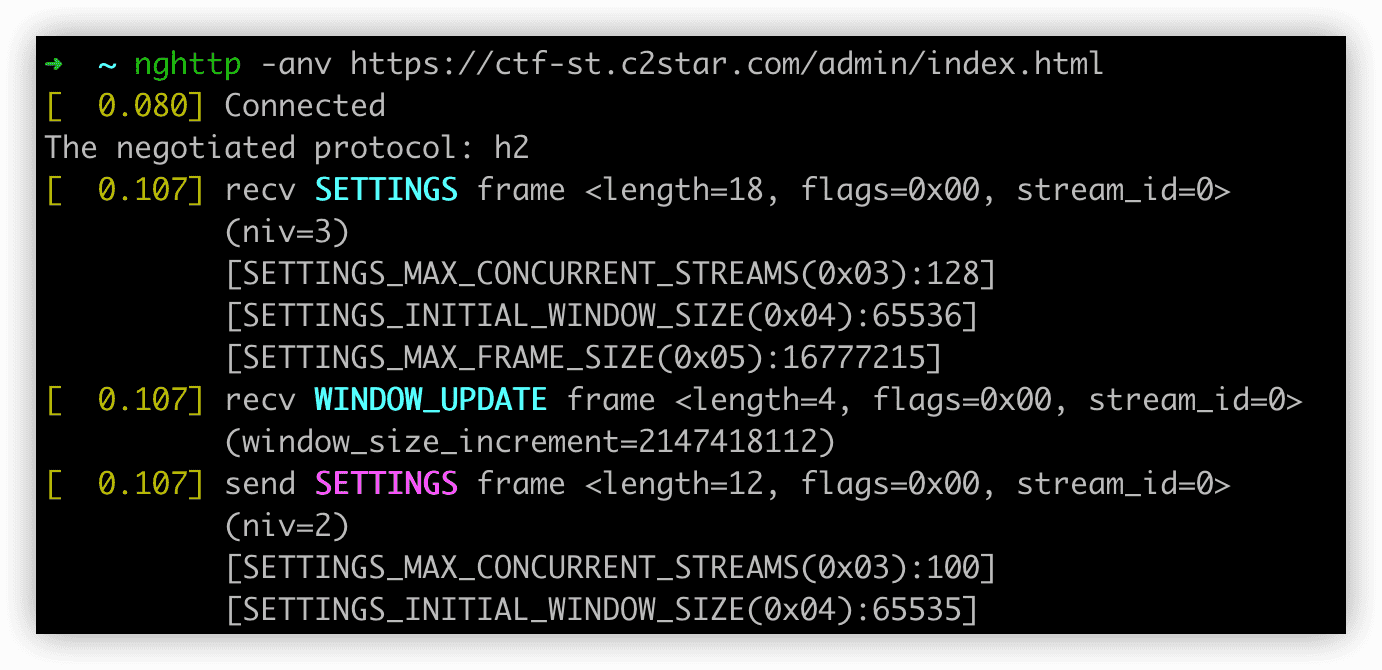
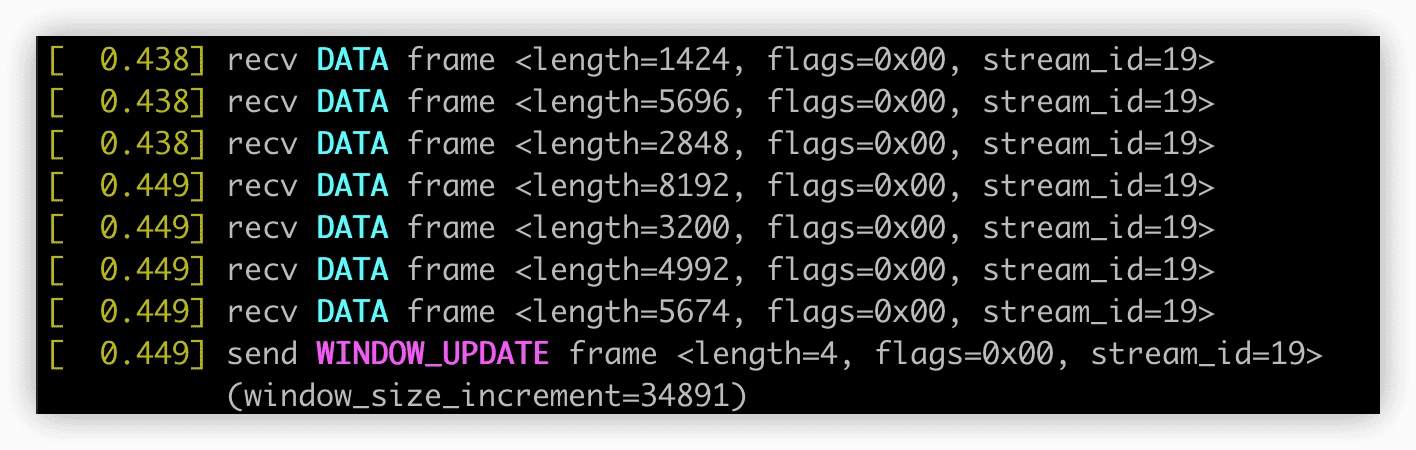
流量控制在DATA帧上使用。当客户端不再发送确认帧时,还可以发送控制帧(特别是用来控制流量的WINDOW_UPDATE帧)。
[ 0.107] recv WINDOW_UPDATE frame <length=4, flags=0x00, stream_id=0>
(window_size_increment=2147418112)
这个帧说明,网站准备接收2147418112个8位字节,因为这个帧使用的流ID是0,所以这是会应用到所有流的连接层的限制,其是流本身的流量控制之外的限制。流0不得用于DATA帧,也不需要有自己的流量控制。
[ 0.449] send WINDOW_UPDATE frame <length=4, flags=0x00, stream_id=19>
(window_size_increment=34891)
[ 0.449] send WINDOW_UPDATE frame <length=4, flags=0x00, stream_id=0>
(window_size_increment=36113)
在接收到一些DATA帧之后,客户端会发送WINDOW_UPDATE帧通知服务器它已经消费了多少帧。
7.3 流优先级
HTTP/2 定义了两种不同的方法来设置优先级:
- 流依赖
- 流权重
可以在请求的HEADERS帧中设置这些优先级,或者在其他时间使用单独的PRIORITY帧来设置。
7.3.1 流依赖关系
一个流可以依赖另外一个流,只有当所依赖的流不需要使用连接来发送数据时,这个流才可以开始发送资源。
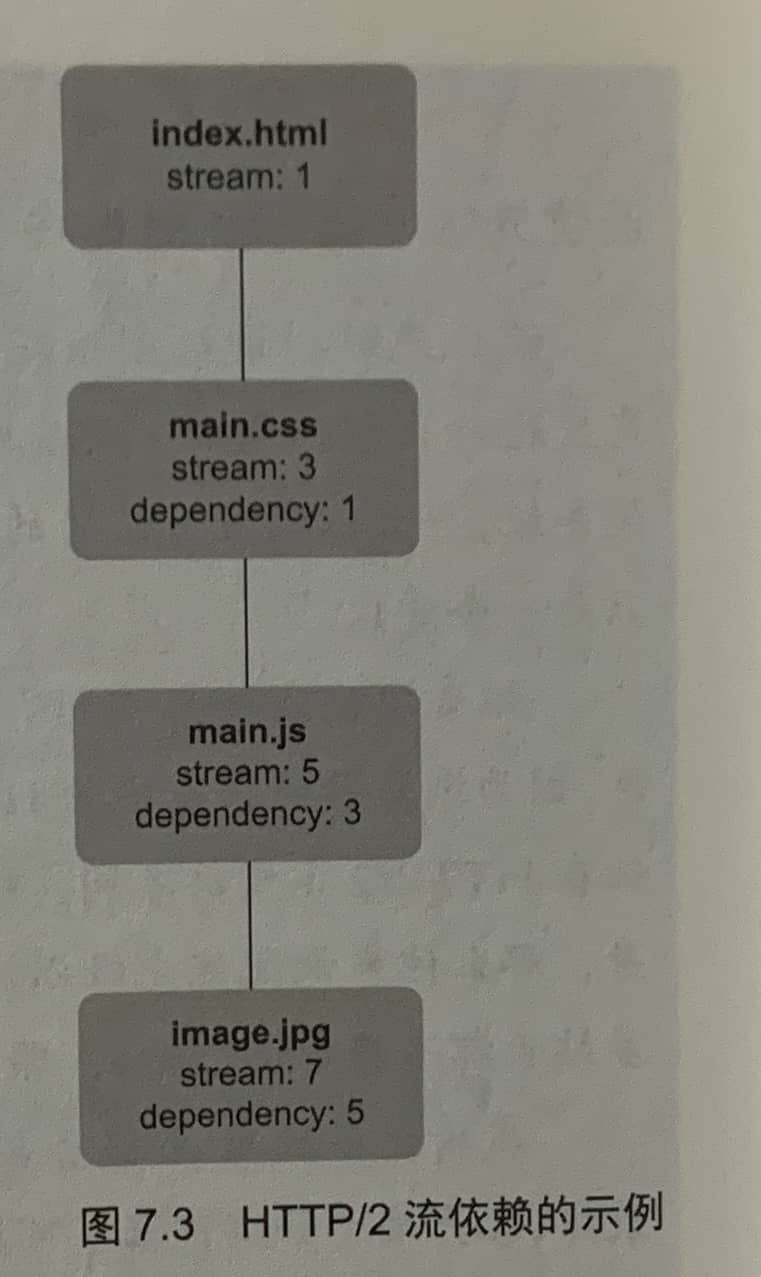
所有的流都默认依赖于流0,它是控制流,没有依赖。
这个依赖结构并不意味着流被它们的父依赖阻塞。使用流优先级的目的是尽量高效利用连接,而不是作为一种阻塞机制。上图中,当服务器拉取main.cs和main.js时,它可以开始发送image.jpg,当这些资源都可以返回给客户端时,服务器可能暂停发送image.jpg,并发送main.css,然后是main.js,之后才会继续发送image.jpg的剩余数据。或者,服务器可以使用一个更简化的模型,先发送完image.jpg,让其他的准备好的资源先排队。具体实现取决于服务器。
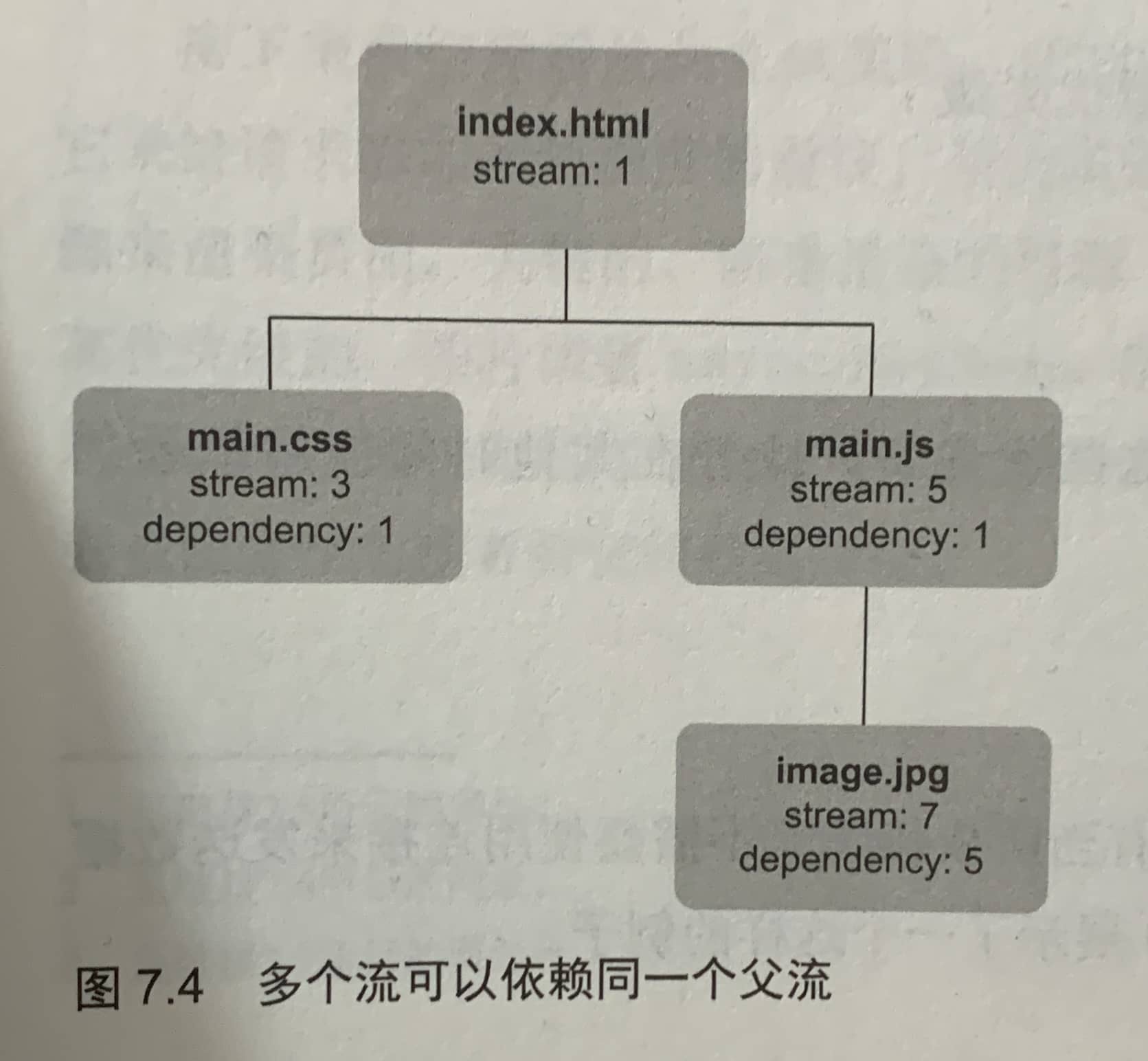
多个流可以有同一个依赖,每个流都可以指定它依赖的流。
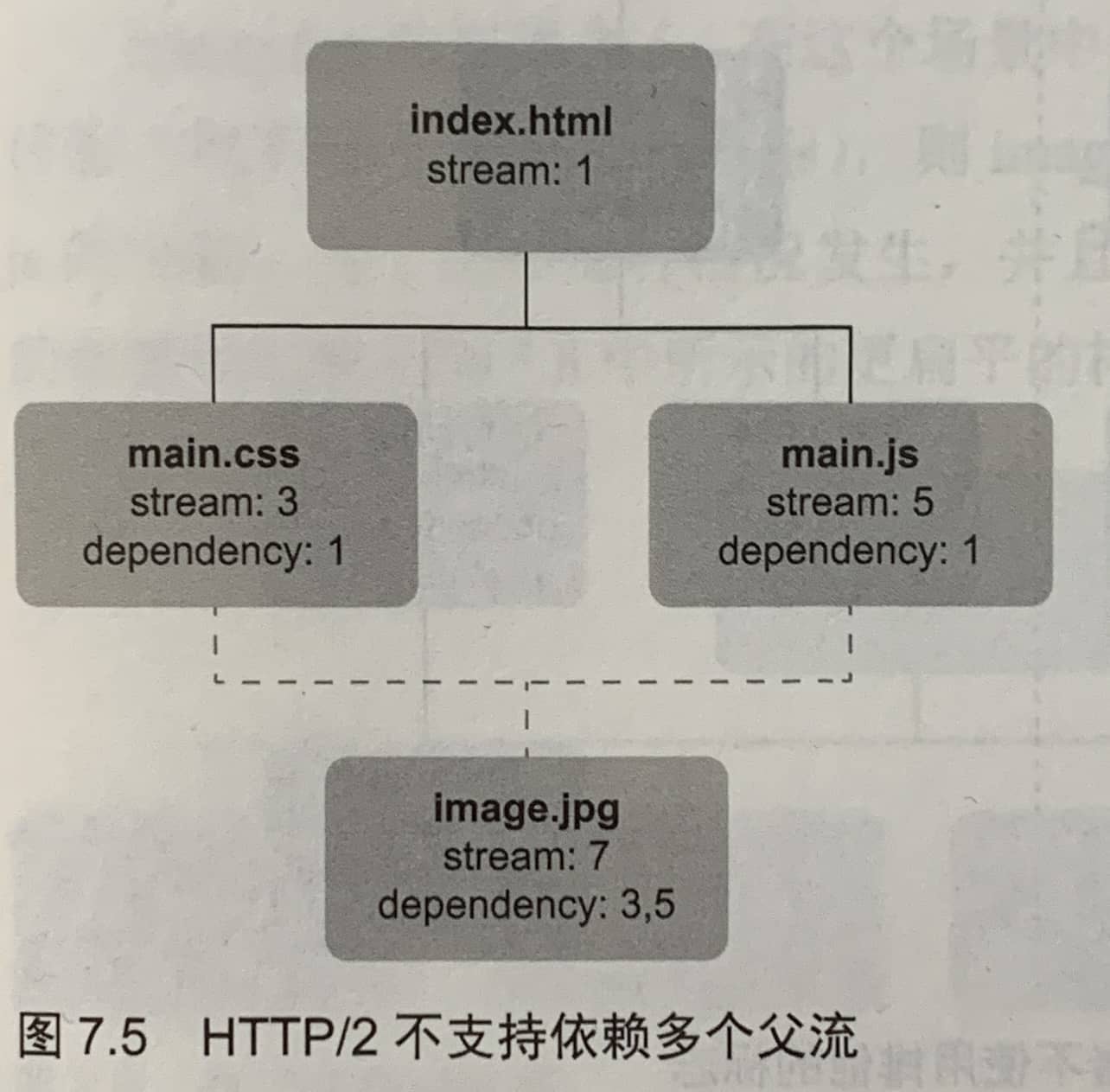
7.3.2 流权重
流权重,用于给两个依赖同一个父资源的请求设定优先级。

为了使优先级模型更简单,一些客户端会使用PRIORITY帧预设值一些假流,并为它们设置对应的优先级,然后将请求挂载在这些流下面。

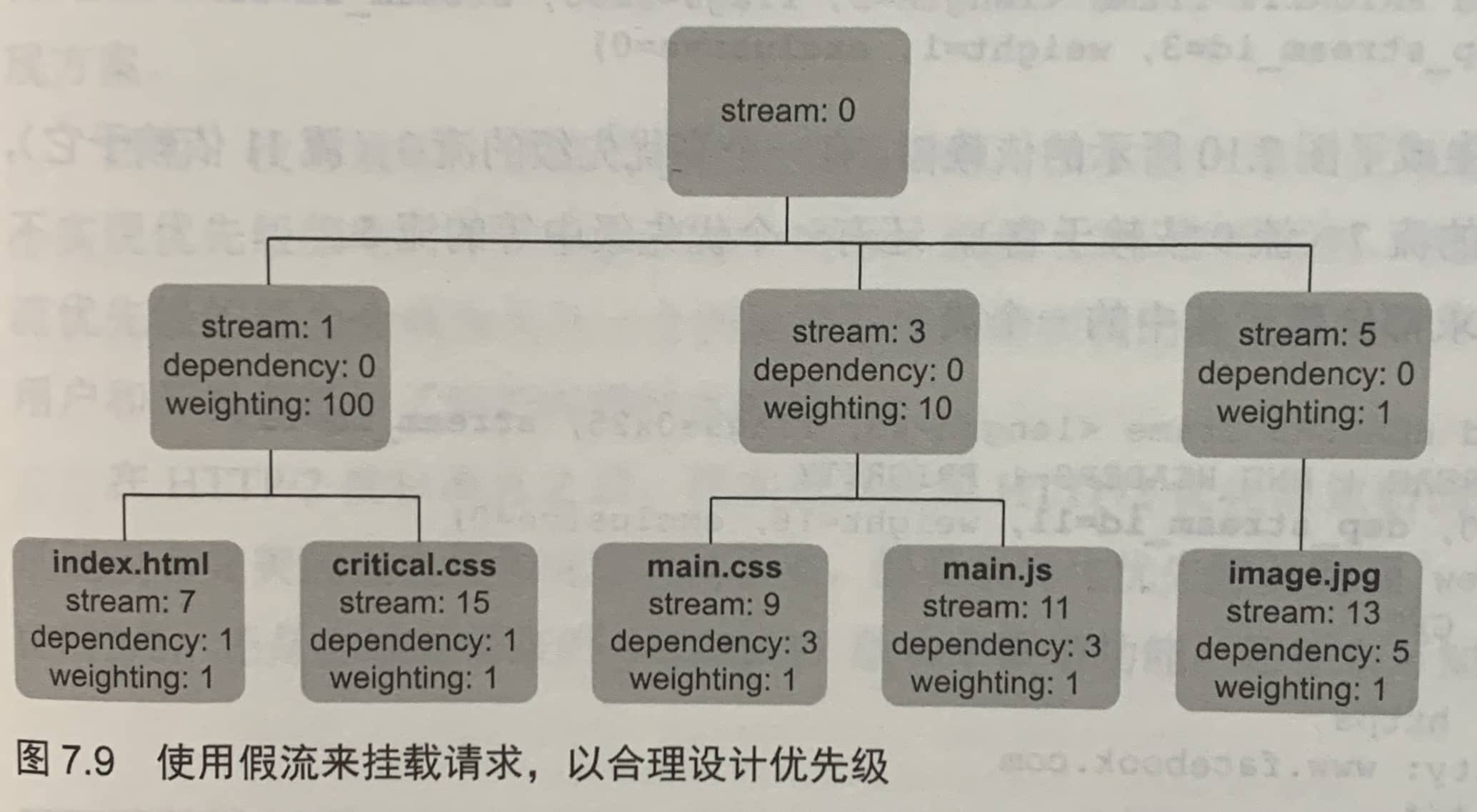
这些假流仅用于优先级排序,永远不会被用来直接发送请求。
7.3.4 Web服务器和浏览器中的优先级策略
很多服务器和客户端都支持优先级策略,但没给站长太多控制权。大多数服务器使用客户端建议的优先级,或者不支持优先级策略。
7.4 HTTP/2一致性测试
H2spec是一个HTTP/2一致性测试工具,可以测试HTTP/2服务器是否正确遵循规范。
第8章 HPACK首部压缩
8.1 为什么需要首部压缩
HTTP首部信息在每次请求和响应是都有大量重复的字段,这就造成了浪费。
8.2 压缩的运作方式
有损压缩是指在压缩数据的同时,为了减小数据的大小,不可避免地丢失部分原数据信息,因此压缩后的数据无法完全还原为原始数据,虽然可能经过特殊处理后得到近似的数据。通常应用于音频、视频等不可压缩的数据,例如MP3、JPG等格式。有损压缩可以获得更高的压缩率,但会对数据质量造成一定损失。
无损压缩是指在压缩数据的同时,不损失任何原数据的信息,压缩后的数据可以通过解压缩还原为原始数据。通常应用于文本、数字等可压缩的数据,例如zip文件格式、PNG图片格式等。
8.2.1 查找表
第一种方法是将冗长的、重复的数据拿出来,使用引用来代替。解压缩时使用查询表中的原始文本替换引用。此过程可以是动态的,它对于结构一致的数据尤其有效。

8.2.2 更高效的编码技术
使用可变长度编码,如Huffman编码,将每个值的使用频率为其分配一个唯一代码,并且保证没有一个代码是其他代码的前缀。从而降低文本大小。
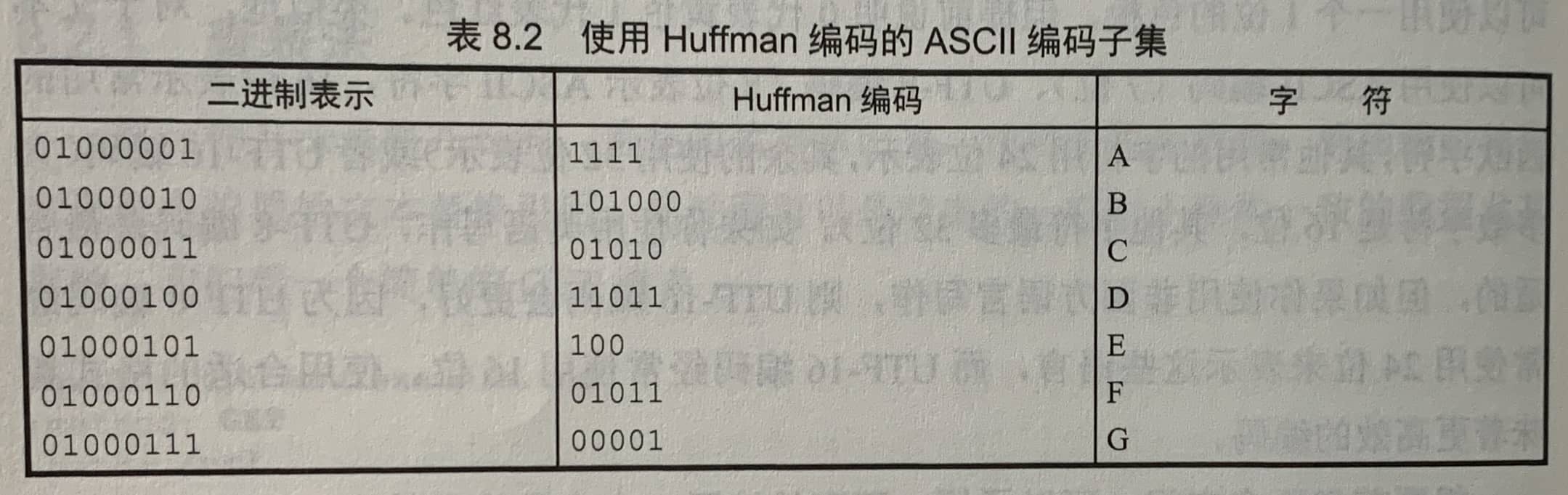
8.2.3 Lookback(反查)压缩
反查压缩在当前位置放置应用,指向重复文本。
8.3 HTTP正文压缩
HTTP正文压缩通常用于文本数据。媒体数据一般通过制定的格式提前压缩过了,不需要再压缩。例如JPEG,是专门针对图片的压缩格式,不需要再由Web服务器压缩,再压缩会浪费处理性能。
8.4 HTTP/2的HPACK首部压缩
HTTP工作组制定了一个新的规范,叫做HPACK,它基于查询表和Huffman编码,但不是基于反查的压缩方法。
8.4.1 HAPCK静态表
HPACK有一个静态表,包含61个常见的HTTP首部名称。
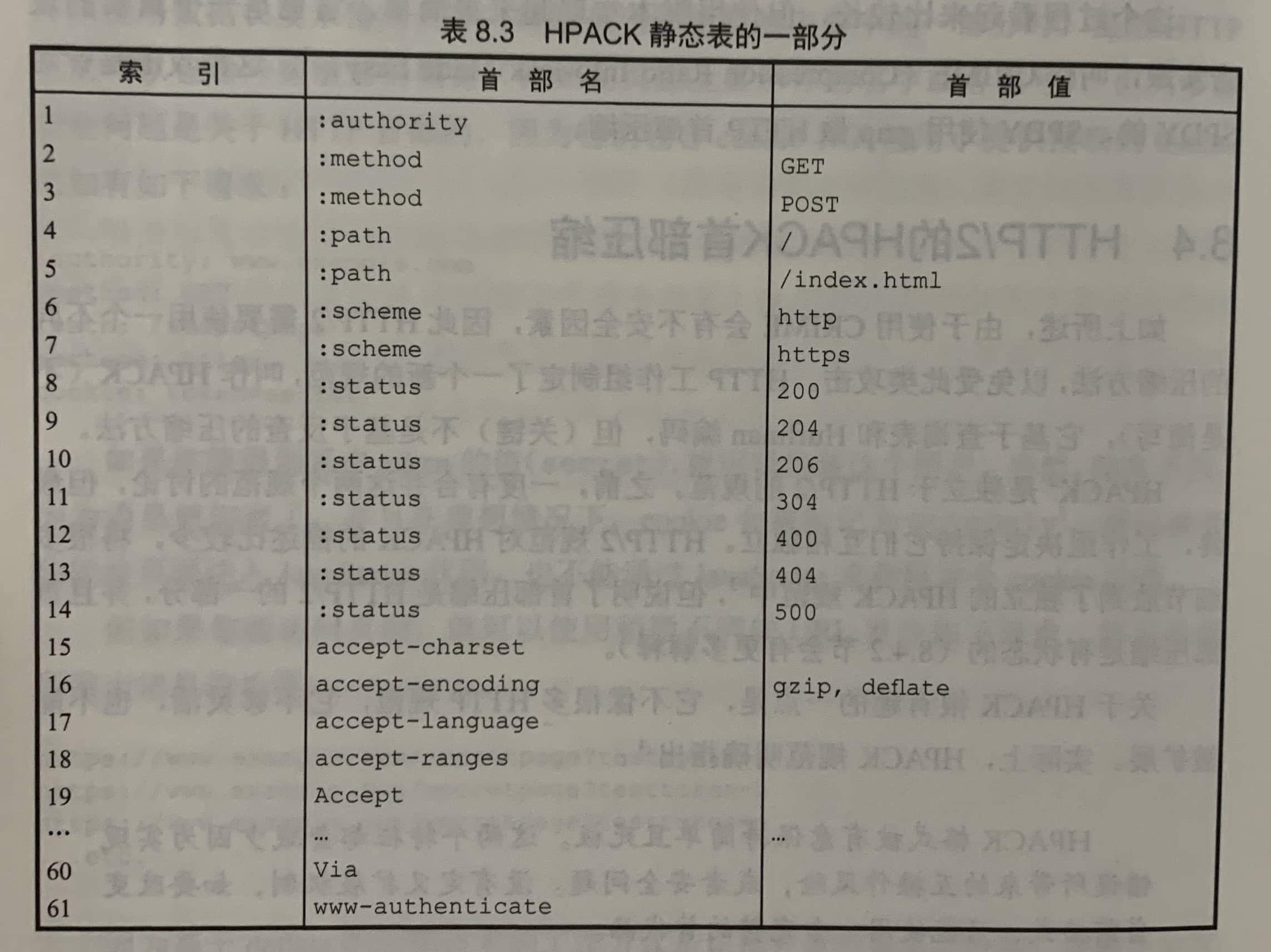
这个表同时被请求和响应使用。
8.4.2 HPACK动态表
HPACK动态表是HPACK协议中的一个用于压缩和解压缩HTTP首部的数据结构。它是一个双向的、长度有限的表,用于存储最近传输的HTTP首部字段,以便进行更高效的压缩和解压缩。HTTP/2的压缩操作在发送和接收端都有一个动态表,这两个动态表可以根据需要进行添加、删除和清空操作,从而实现更高效的首部压缩和解压缩。HPACK协议规定,动态表中的最长支持存储最近插入的前N个首部字段,其中N的大小取决于动态表的容量大小限制;如果动态表中的首部字段已达到了容量上限,则需要淘汰最早插入的首部字段,以便新的首部字段可以插入到表中。

第4部分 HTTP的未来
第9章 TCP、QUIC和HTTP/3
9.1 TCP的低效率因素,以及HTTP
HTTP依赖TCP的有序可靠传输服务。
TCP的5个主要问题:
- 有一个连接创建的延迟。
- TCP慢启动算法限制了TCP的性能,它小心翼翼地处理发送的数据量,以尽可能防止重传。
- 不充分使用连接会导致限流阀值降低。如果连接未被充分使用,TCP会将拥塞窗口的大小减小。
- 丢包也会导致TCP的限流阀值降低。TCP认为所有的丢包都是由窗口拥堵造成的,但其实也不是。
- 数据包可能被排队。乱序接收到的数据包会被排队,以保证数据是有序的。
TCP握手和HTTPS握手延迟

TCP拥塞算法的三个阶段:慢启动、拥塞避免、快速重传与快速恢复。
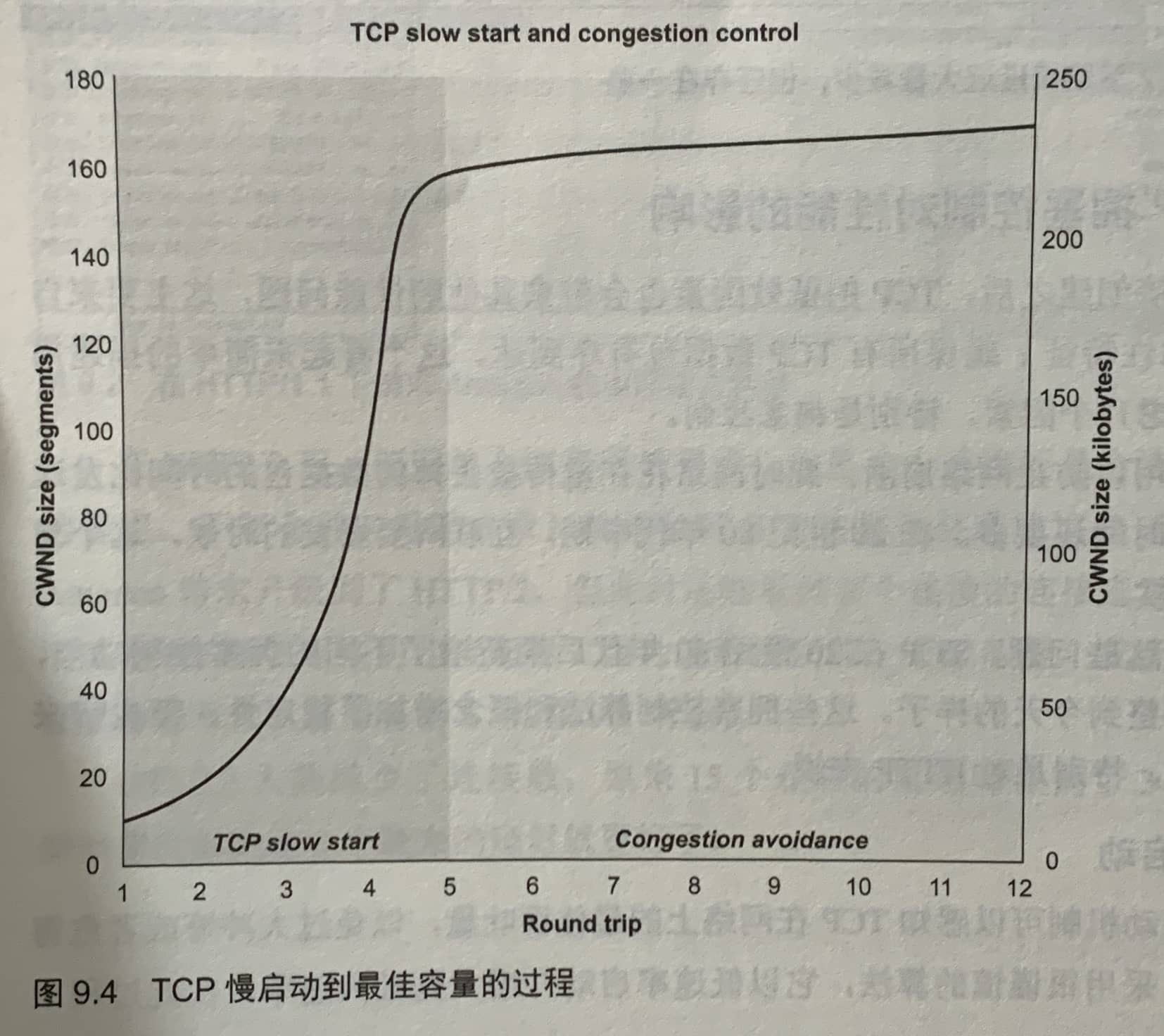
连接闲置时会降低性能。
丢包降低TCP性能。丢包带来的影响在HTTP/2中尤其严重,因为HTTP/2只使用单个连接,会对所有资源造成影响。
丢包会导致数据排队。



上图中,因为TCP保证有序交付,所以尽管流7和流9已经被完整接收,但它需要等到流5接收到之后才会交付给上层协议。而HTTP/1.1的多个连接反而不会给script.js和image.jpg资源造成堵塞。
TCP的新特性通常和操作系统底层绑定,所以升级TCP通常需要升级整个操作系统。
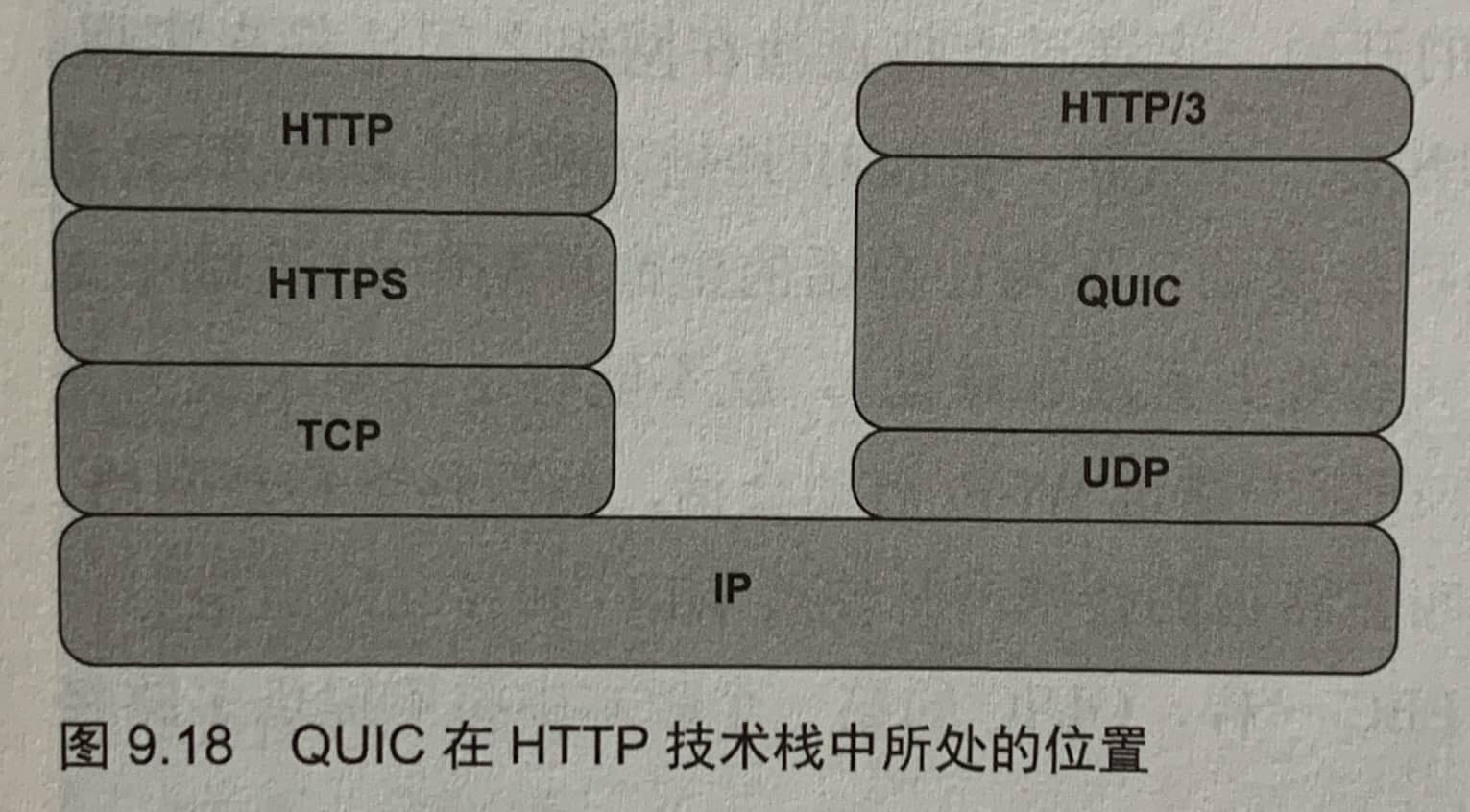
9.2 QUIC
QUIC是一个基于UDP的协议,目标是替换TCP和HTTP栈中的某些部分,以解决低效率因素。
QUIC特性:
- 大量减少连接创建时间。
- 改善拥塞控制。
- 多路复用,但不要带来队头阻塞。
- 前向纠错。
- 连接迁移。
FEC(Forward Error Correction,前向纠错)试图通过在邻近的数据包添加一个QUIC数据包的部分数据来减少数据包重传的需求。这个想法是,如果只丢了一个数据包,那应该可以从成功传送的数据包中重新组合出该数据包。
连接迁移旨在减少连接创建的开销,它通过支持连接在网络之间迁移来实现。在TCP下,两端的IP地址和端口决定一个连接。更改IP地址需要建立新的TCP连接。QUIC允许在家中通过Wi-Fi启动会话,然后移至移动网络,无须重启。
QUIC取代了TCP提供的大多数功能(创建连接、可靠性和拥塞控制部分),取代了HTTPS的全部(降低了创建延迟),甚至还有HTTP/2的一部分(流量控制和首部压缩)功能。
QUIC的目标是使用一次往返建立连接,通过同时担任连接层(TCP)和加密层(TLS)来实现此目标。QUIC不会替代HTTP/2。但它会接管传输层的一些工作,上层运行较轻的HTTP/2实现。
QUIC为什么选择基于UDP构建:
- TCP的改进进度非常缓慢。
- SCTP与QUIC有很多相同的功能,但是SCTP的采用率很低。
- IP协议不能针对端口应用程序特定的访问,该协议必须在操作系统级别实现,不能通过应用程序来实现。
- UDP是一种基础协议,在内核中实现。在内核之外,可以通过部署应用程序来实现快速创新。
采用UDP的问题是UDP通常会被防火墙和中间设备屏蔽。另外一个问题是用户空间并不总是与高度优化的内核空间一样高效,UDP是一种开销更高的协议。
QUIC旨在成为一种通用的协议,HTTP只是它的一种用途。
认为HTTP cookie不好的原因:
- 它可以用来做广告追踪。
- 默认情况下它们是不安全的。
- 它们会随着每个请求被发送

HTTP Cookie字段
| 字段名 | 含义 | 作用 |
|---|---|---|
| Name | Cookie的名称 | 识别cookie的标识符 |
| Value | Cookie的值 | 存储在服务器端的值,通过该值来区分用户 |
| Domain | 域名 | 可以访问该Cookie的域名 |
| Path | 路径 | 可以访问该Cookie的路径 |
| Expires | 过期时间 | Cookie失效的日期和时间 |
| Secure | 仅在通过HTTPS协议访问站点时,才发送Cookie到服务器 | 提高Web应用程序的安全性,防止Cookie被窃听和劫持 |
| HttpOnly | 禁止JavaScript访问Cookie | 防止某些类型的跨站点脚本攻击(XSS攻击),保护Cookie中包含的敏感信息 |
| SameSite | 控制Cookie是否可以在跨站点请求中发送 | 减少跨站点脚本攻击(XSS攻击)和跨站点请求伪造(CSRF攻击)的风险,提高Web应用程序的安全性 |
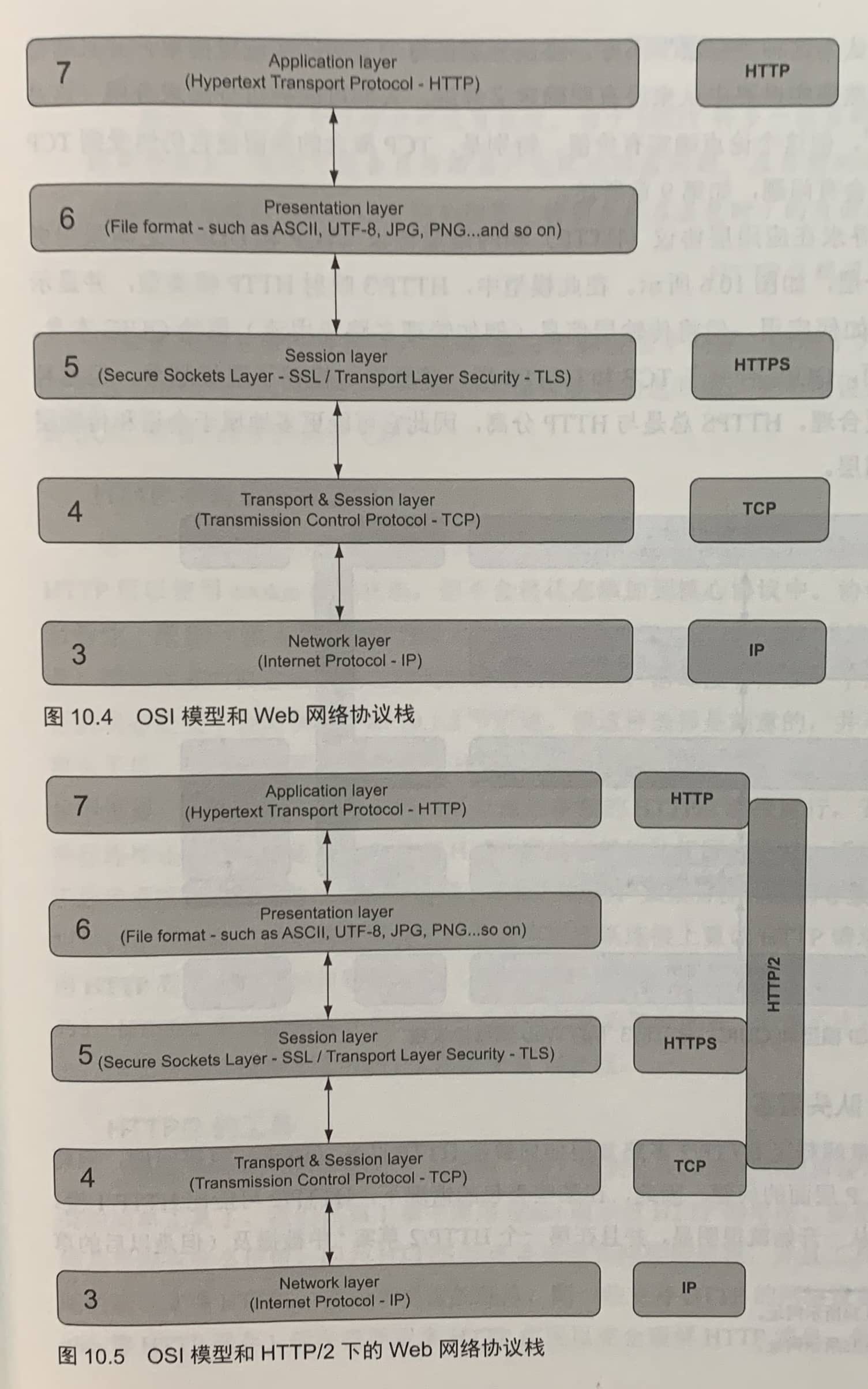
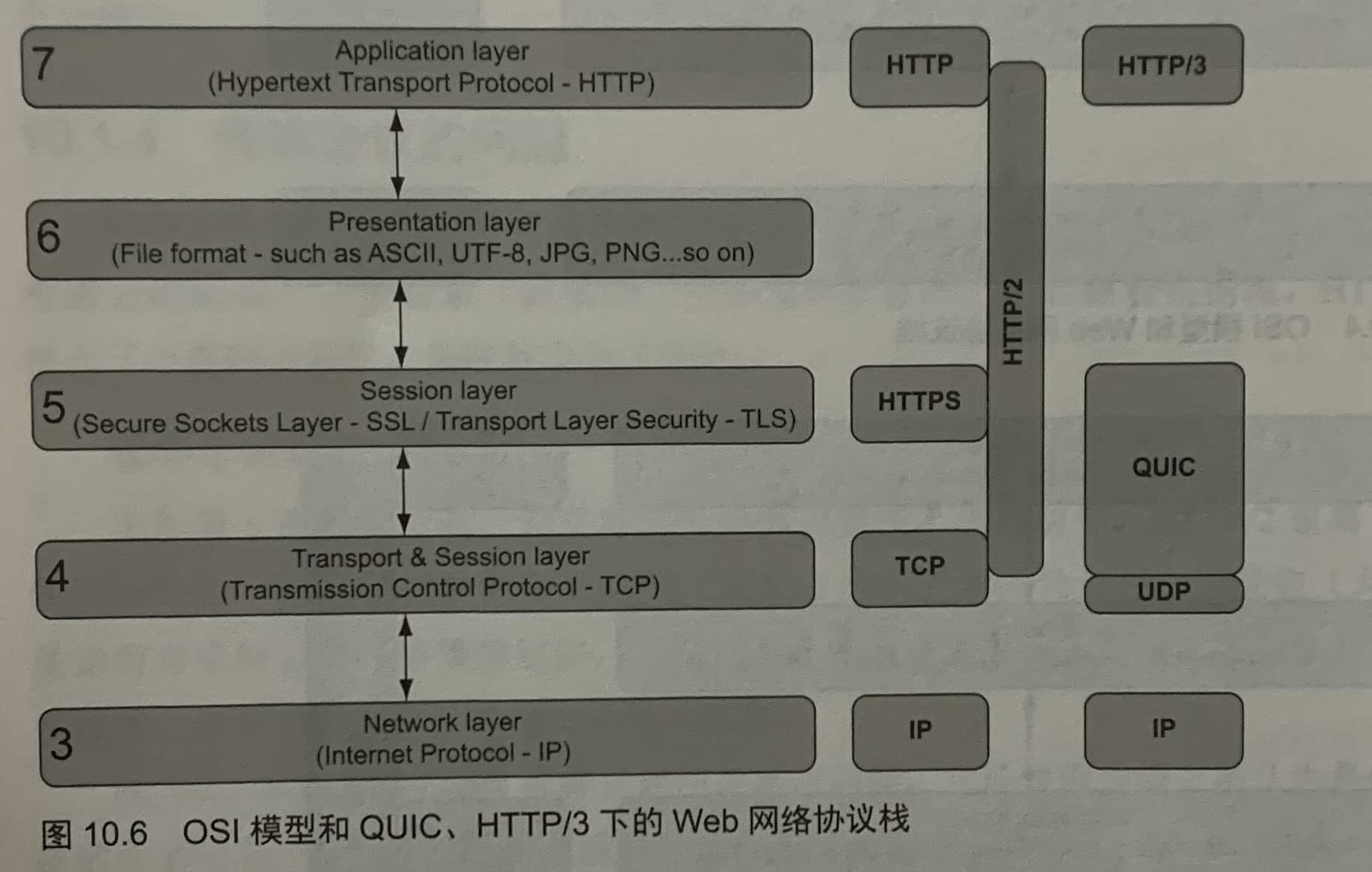
HTTP可作为启动另外一个协议的入口协议(例如SSH)。HTTP还可用于升级连接(如WebSockets)。
HTTP权威指南知识补充
第2章 URL与资源
2.4 各种令人头疼的字符
为了避开安全字符表示法带来的限制,人们设计了一种编码机制,通过转义表示法来标识不安全的字符,包含一个百分号(%),后面跟着两个表示字符的ASCII码的十六进制数。

在URL中,有几个字符被保留起来,有着特殊的含义。

第3章 HTTP报文
3.3 方法
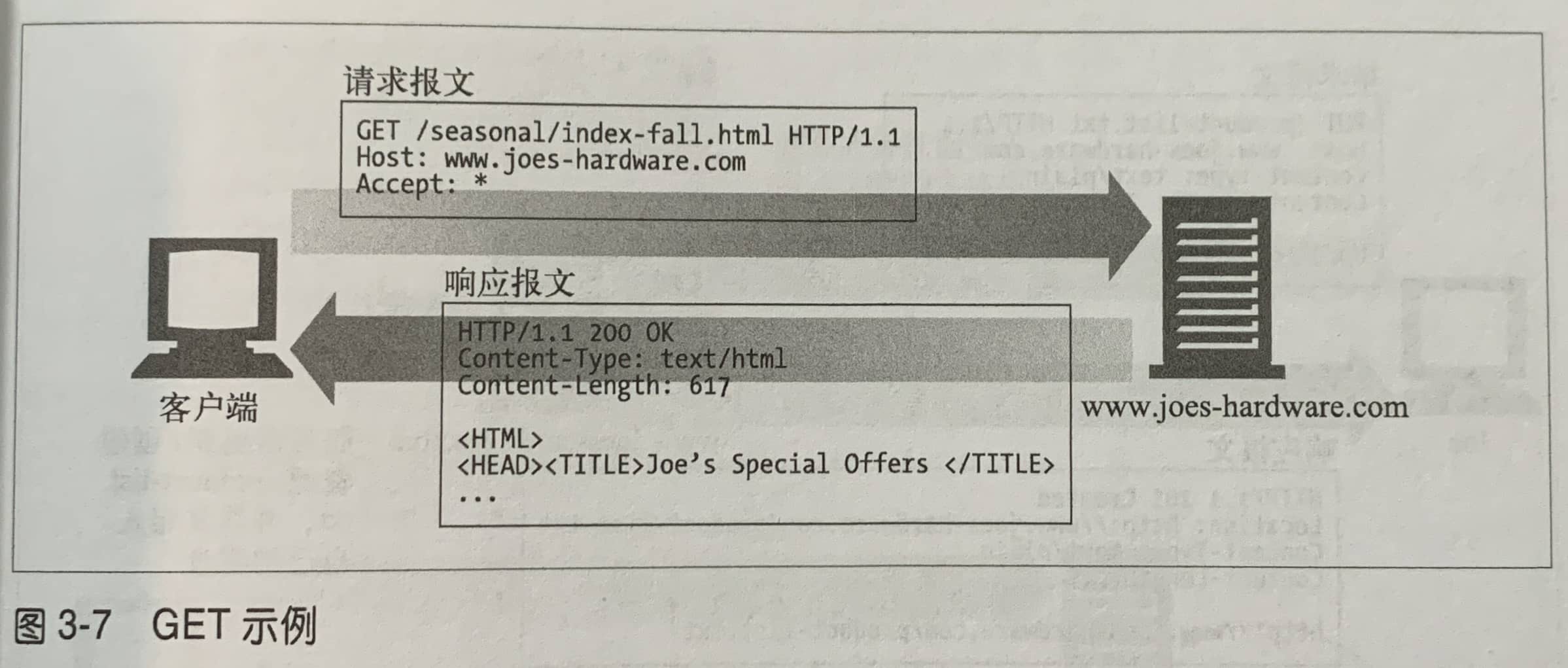
HTTP定义了一组安全方法的方法,GET和HEAD方法都被认为是安全的,这意味着使用GET或HEAD方法的HTTP请求不会产生什么动作。
| 方法 | 定义 | 用途 |
|---|---|---|
| GET | 请求指定的页面或资源。 | 获取指定页面或资源的数据,对服务器数据没有任何影响。 |
| HEAD | 与GET方法类似,但不返回响应体,只返回响应头部信息。 | 用于获取响应头部信息,同样不对服务器数据产生影响,但可以用于检查文件是否存在、文件大小等信息,也有利于减轻服务器的负担。 |
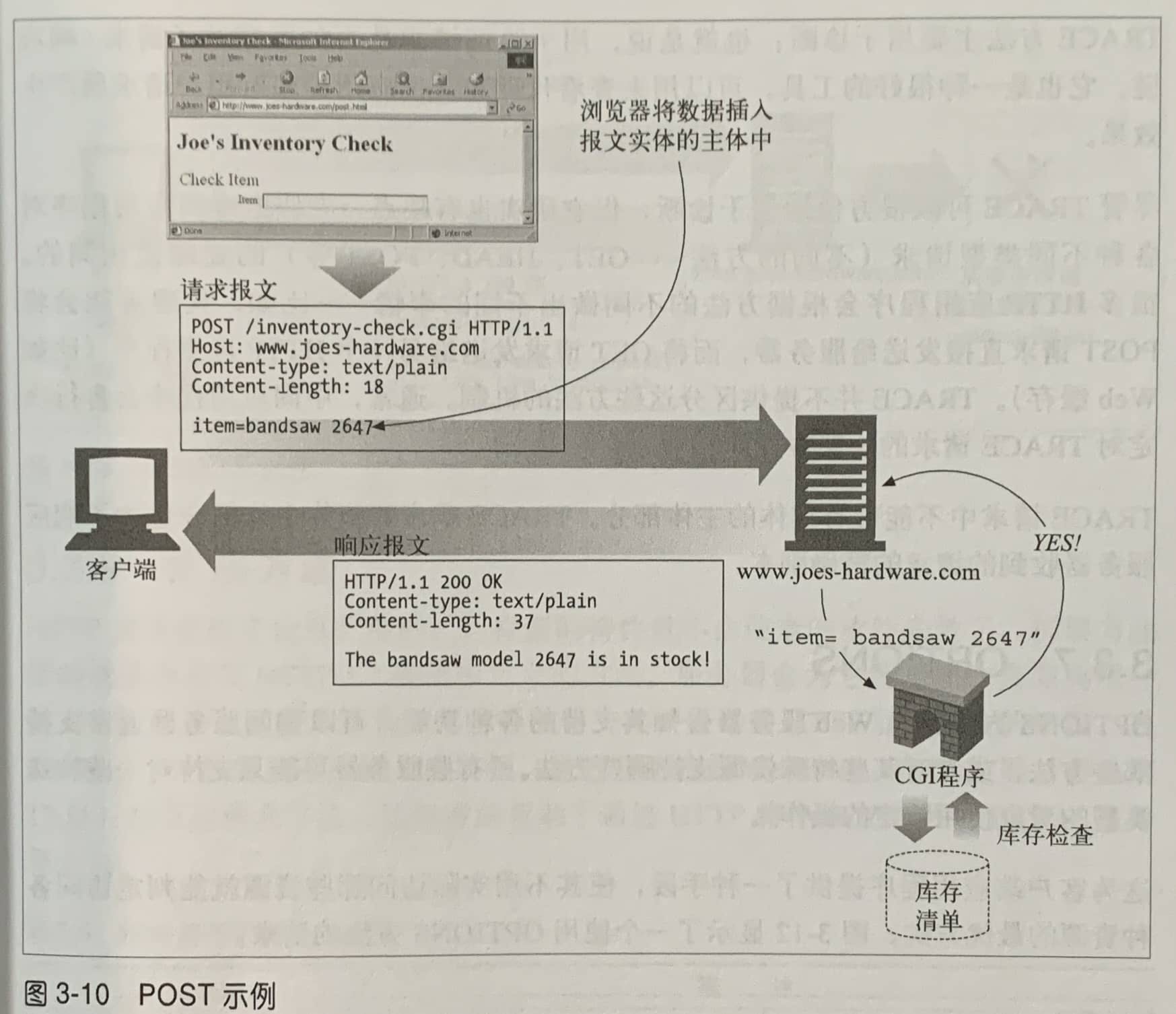
| POST | 向指定资源提交要被处理的数据。 | 用于向服务器提交数据或请求,可能对服务器数据产生更新或修改。 |
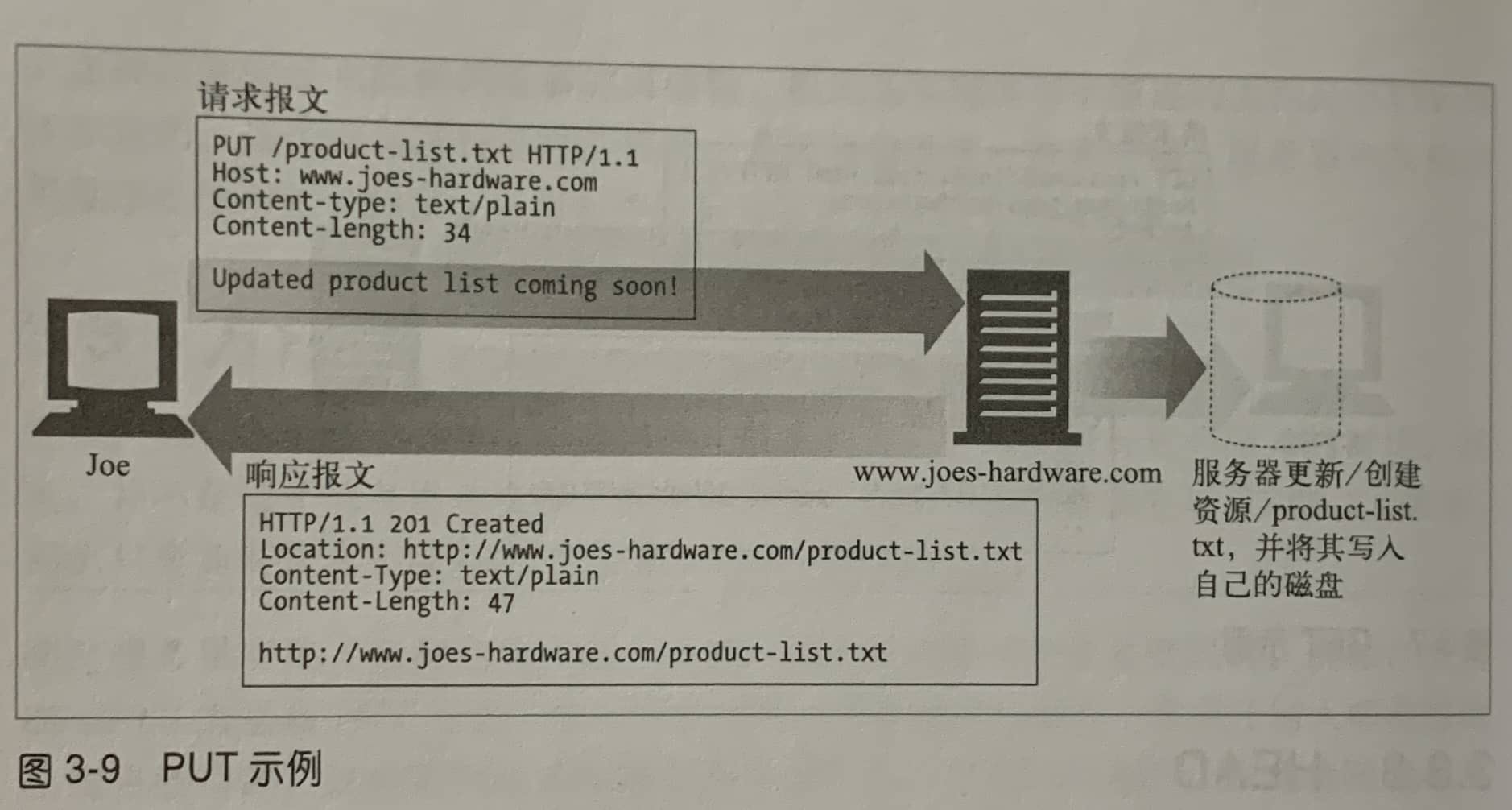
| PUT | 将请求的信息存储到指定位置。 | 用于向指定URL位置上传一个表示某个资源的内容,如果该URL已经存在资源则将其改为新的内容,如果不存在则新建一个资源。 |
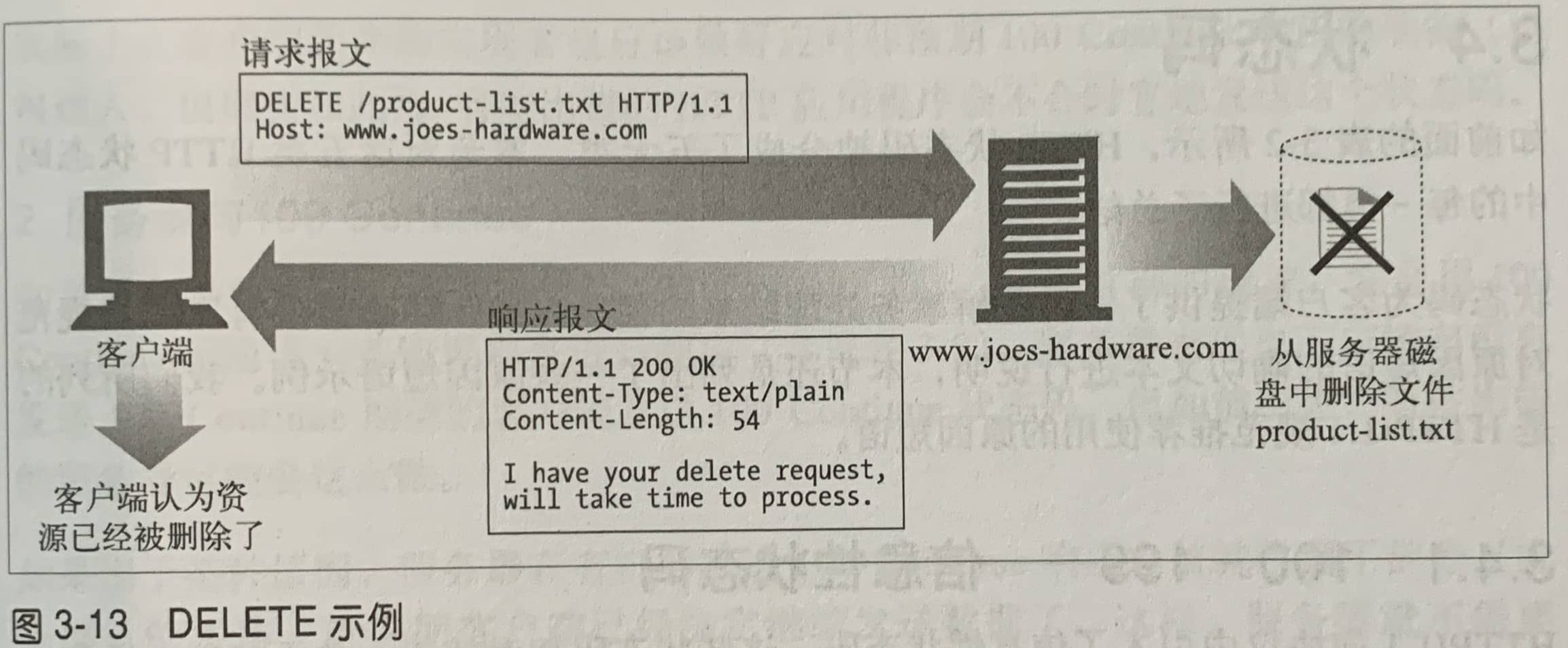
| DELETE | 请求服务器删除指定的页面或资源。 | 用于删除指定的页面或资源。 |
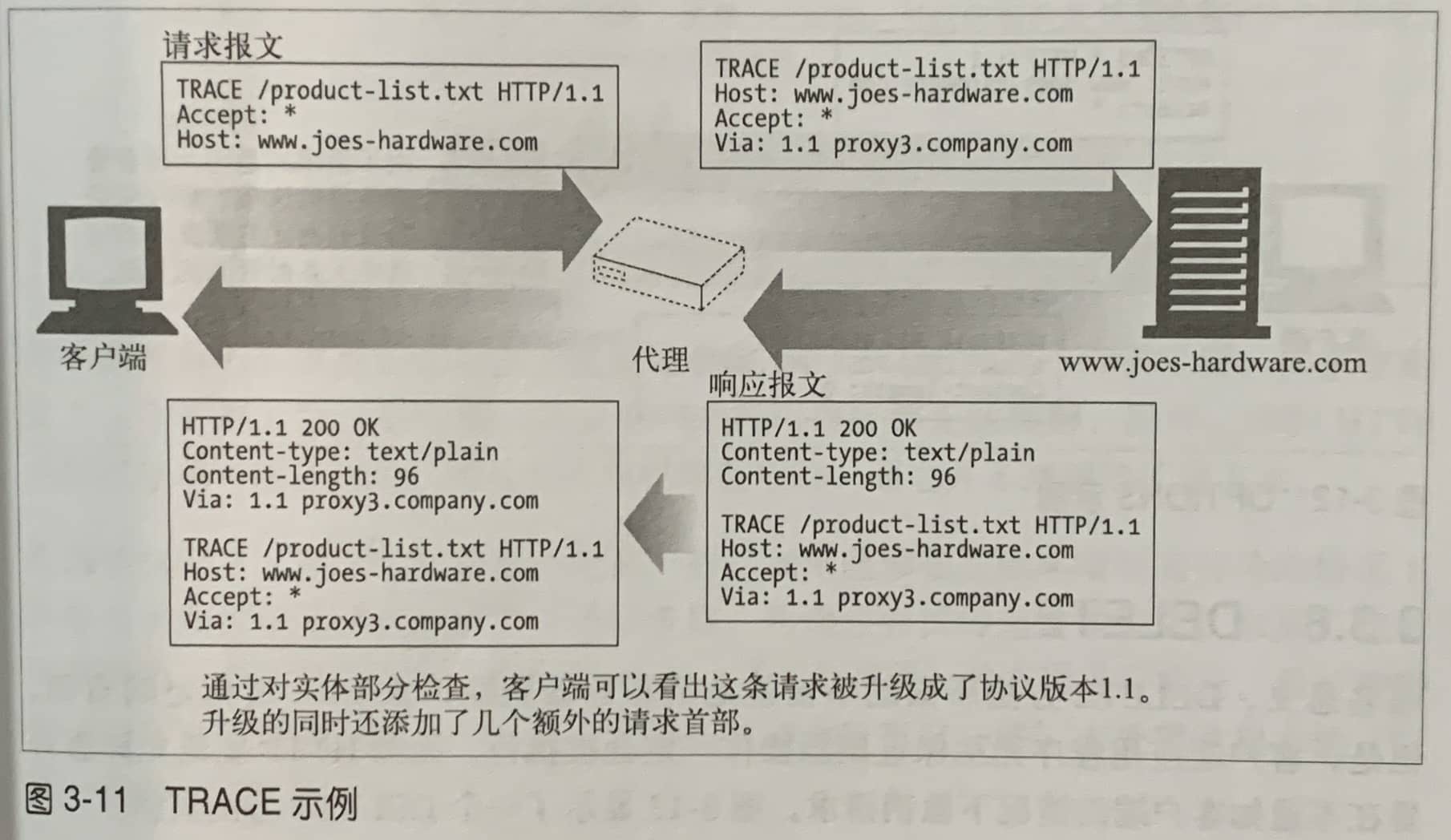
| TRACE | 回显服务器收到的请求,主要用于测试或诊断。 | 用于追踪消息在代理服务器上的传输路径,利于测试和调试。 |
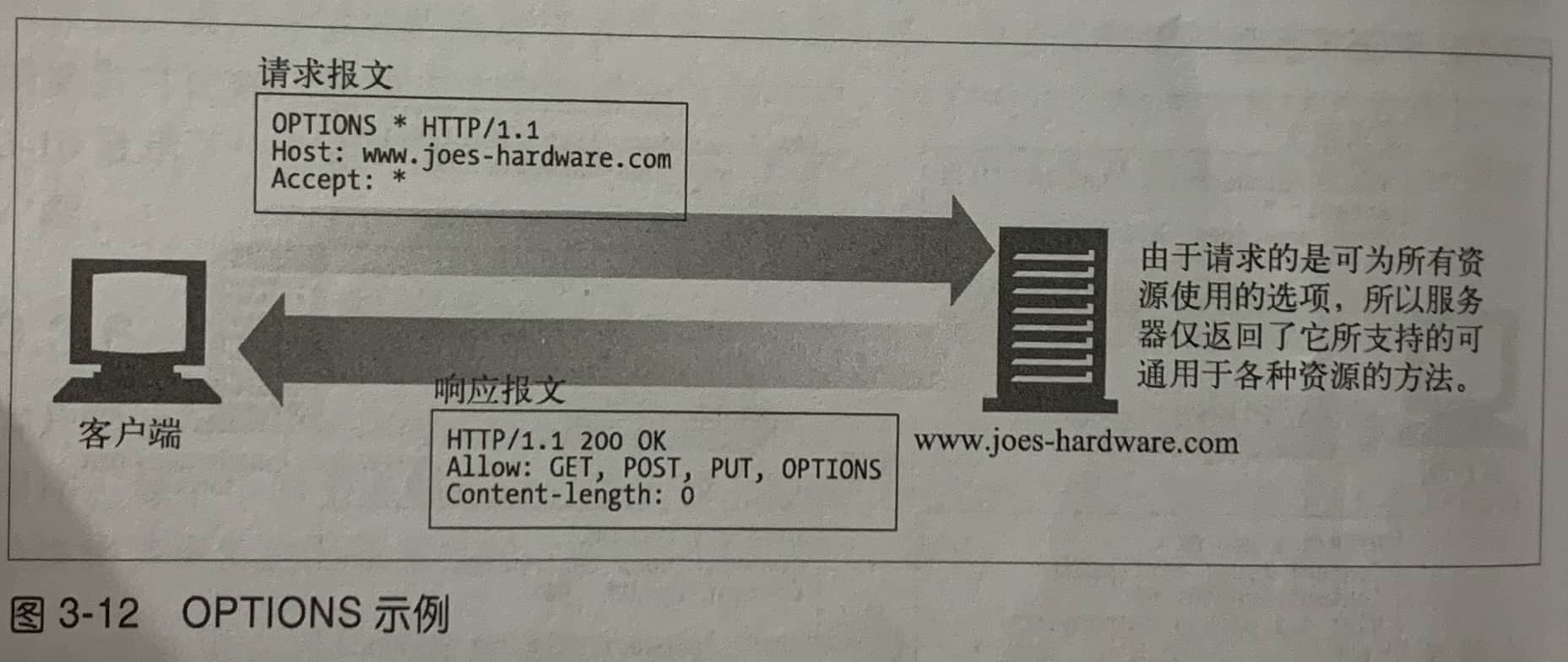
| OPTIONS | 返回服务器支持的所有HTTP请求方法。 | 用于获取服务器支持的所有HTTP请求方法,客户端通过该方法来决定发送何种请求。这个方法比较少用,一般使用HEAD和GET就行了。 |

3.4 状态码
| 状态码 | 原因短语 | 含义 |
|---|---|---|
| 信息性状态码 | ||
| 100 | Continue | 表示服务器已经接收请求头,并且客户端应该继续发送请求主体部分。 |
| 101 | Switching Protocols | 请求者已经要求服务器切换协议,服务器已经确认并准备切换。 |
| 请求成功状态码 | ||
| 200 | OK | 请求成功。一般用于GET与POST请求。 |
| 201 | Created | 已创建成功。 |
| 202 | Accepted | 已接受请求,但尚未处理完成。 |
| 203 | Non-Authoritative Information | 请求成功,但返回的meta信息不在原始的服务器,而是一个副本。 |
| 204 | No Content | 请求成功以后,响应中不包含实体的主体部分。 |
| 206 | Partial Content | 针对范围请求,返回部分内容。 |
| 重定向状态码 | ||
| 300 | Multiple Choices | 多种选择都符合要求,客户端可以自行决定一种选择。 |
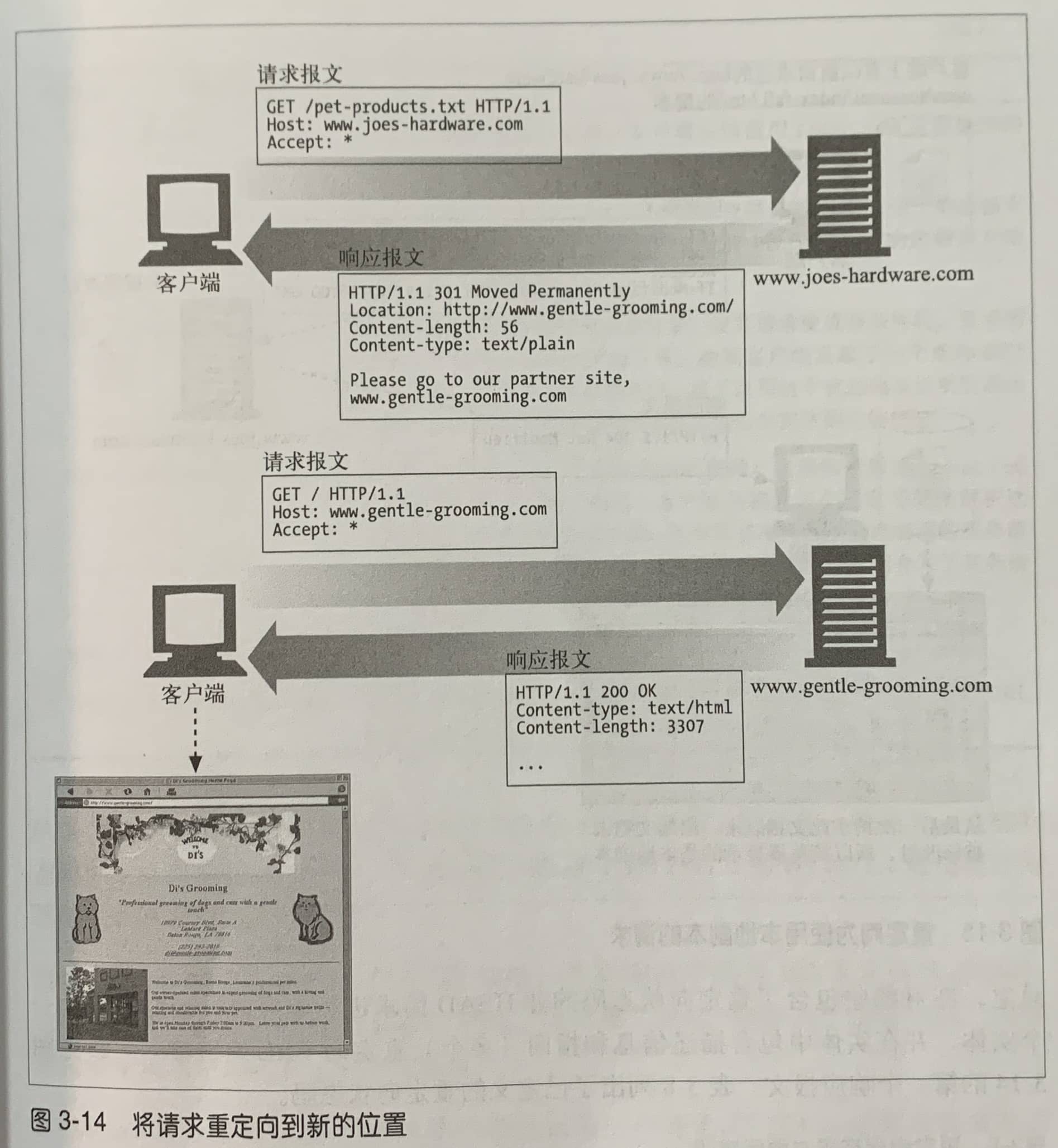
| 301 | Moved Permanently | 重定向到新的URL,永久性。 |
| 302 | Found | 重定向到新的URL,临时性。 |
| 303 | See Other | 重定向到其它URL。 |
| 304 | Not Modified | 请求资源未发生修改,可直接使用客户端缓存的版本。 |
| 客户端错误状态码 | ||
| 400 | Bad Request | 请求错误,例如请求头部信息错误,请求参数错误等。 |
| 401 | Unauthorized | 客户端未经身份验证,无法访问该资源。 |
| 403 | Forbidden | 服务器拒绝请求,没有权限访问该资源。 |
| 404 | Not Found | 请求的资源不存在。 |
| 405 | Method Not Allowed | 请求的方法不被允许。 |
| 服务器错误状态码 | ||
| 500 | Internal Server Error | 服务器错误。 |
| 501 | Not Implemented | 不支持请求的功能。 |
| 502 | Bad Gateway | 网关错误。 |
| 503 | Service Unavailable | 服务不可用。 |
| 504 | Gateway Timeout | 网关超时。 |
| 505 | HTTP Version Not Supported | 不支持的HTTP版本号。 |
3.5 首部
首部与方法配合工作,共同决定了客户端和服务器能做什么事情。
通用首部
客户端和服务器使用的通用首部。
请求首部
响应首部
实体首部
指的是用于应对实体主体部分的首部。
扩展首部
非标准首部,由应用程序开发者创建。
3.5.1 通用首部
| 首部 | 描述 |
|---|---|
| Connection | 控制是否保持连接的选项,如 keep-alive 或 close。 |
| Date | 发送消息的日期和时间。 |
| MIME-Version | 实体主体所使用的 MIME 版本。 |
| Trailer | 用于报文采用分块传输编码方式。列出在消息主体后面的尾部头字段。 |
| Transfer-Encoding | 指定消息主体的传输编码,如 chunked。 |
| Update | 发送端提供的关于消息处理的更新信息。 |
| Via | 包含发送消息的应用程序和版本信息,以及中间服务器的名称和版本。 |
通用缓存首部
| 首部 | 描述 |
|---|---|
| Cache-Control | 用于随报文传送缓存指示 |
| Pragma | 另一种随报文传送指示的方式,但并不专用于缓存 |
3.5.2 请求首部
| 首部 | 描述 |
|---|---|
| Client-IP | 发送请求的客户端 IP 地址。 |
| From | 发送消息的用户的电子邮件地址(非必要),通常用于平衡负载。 |
| Host | 目标服务器的主机名和端口号(非必要),用于服务器上托管多个网站的情况。 |
| Referer | 该请求的来源URL,即当前请求是从哪个URL转来的。 |
| User-Agent | 发送请求的用户代理应用程序或浏览器的信息。 |
Accept首部
| 首部 | 描述 |
|---|---|
| Accept | 客户端能够处理的媒体类型(MIME类型)列表,用逗号分隔。 |
| Accept-Charset | 客户端能够处理的字符集列表,用逗号分隔。 |
| Accept-Encoding | 客户端能够处理的内容编码列表,用逗号分隔(如gzip、deflate)。 |
| Accept-Language | 客户端能够处理的自然语言列表,用逗号分隔。 |
条件请求首部
| 首部 | 描述 |
|---|---|
| Expect | 包含一个或多个期待的特定服务器行为的关键字,如100-continue。 |
| If-Match | 仅当与请求头中提供的实体标记列表相匹配时,才发送请求内容,否则返回412。 |
| If-Modified-Since | 只有当实体自指定日期(时间)以来修改时,才发送请求内容,否则返回304。 |
| If-None-Match | 仅当与请求头中提供的实体标记列表都不相符时,才发送请求内容,否则返回304。 |
| If-Range | 如果实体未被修改,则发送其范围请求,或者发送整个实体,否则返回206或200。 |
| If-Unmodified-Since | 如果实体自指定日期(时间)以来未被修改,则发送请求内容,否则返回412。 |
| Range | 请求实体的一个或多个子范围,用于支持断点续传或只请求部分内容。 |
安全请求首部
| 首部 | 描述 | 作用 |
|---|---|---|
| Authorization | 包含客户端提供的用于验证其自身的凭据,如基本认证或摘要认证。 | 认证用户身份以授权请求,防止未经授权的访问。 |
| Cookie | 包含来自之前请求中服务器设置的一个或多个 Cookie。 | 在客户端和服务器之间跟踪会话状态,比如用户是否已经登录、用户的首选项等信息。 |
注意: Cookie 首部现在已经不推荐使用了,因为它们缺乏安全性,被认为是一种潜在的安全风险和弱点。替代方案是使用 HTTP State Management Mechanism 规范中定义的 Set-Cookie 首部。
代理请求首部
| 首部名 | 描述 | 作用 |
|---|---|---|
| Max-Forward | 限制递归代理访问该请求的最大次数 | 防止请求在代理之间无限循环 |
| Proxy-Authorization | 包含代理认证信息 | 允许代理验证客户端请求的身份 |
| Proxy-Connection | 控制代理与连接的行为 | 用于告知代理连接参数或者连接管理信息,如关闭或持久化连接 |
3.5.3 响应首部
响应首部为客户端提供了一些额外信息。
| 首部名 | 描述 | 作用 |
|---|---|---|
| Age | 从原始服务器到代理缓存形成的时间(以秒为单位) | 允许缓存服务器和客户端确定请求的新鲜度和过期时间 |
| Public | 指示服务器支持的 HTTP 方法 | 允许客户端了解服务器支持的方法,以便发送相应的请求 |
| Retry-After | 指定何时再次发送请求的建议时间 | 在响应代码为 503 (Service Unavailable) 时,用于告知客户端何时可以再次尝试访问该资源 |
| Server | 包含服务器名称和版本信息 | 允许客户端了解正在与其通信的服务器软件 |
| Title | 提供人类可读的简短描述 | 用于简短描述响应的主要内容 |
| Warning | 包含有关响应的潜在问题的附加信息 | 允许缓存服务器和客户端了解响应可能存在的问题(例如,缓存地址不一致,即将过期的信息等)。 |
协商首部
| 首部名 | 描述 | 作用 |
|---|---|---|
| Accept-Range | 指示服务器是否支持请求范围,并支持哪些范围(如字节范围) | 允许客户端询问服务器是否支持断点续传等功能 |
| Vary | 指示用于确定响应是否可以与以前的响应合并的请求头列表 | 用于告知缓存服务器哪些请求头用于确定响应是否与缓存匹配,从而避免在不合适的情况下返回缓存内容。 |
安全响应首部
| 首部名 | 描述 | 作用 |
|---|---|---|
| Proxy-Authenticate | 提供要求客户端进行身份验证的身份验证方法列表 | 在代理需要客户端提供身份验证凭据时发送 |
| Set-Cookie | 向客户端发送一个或多个cookie | 用于在客户端和服务器之间共享数据,例如用户的偏好设置或会话信息 |
| WWW-Authenticate | 提供要求客户端进行身份验证的身份验证方法列表 | 在服务器需要客户端提供身份验证凭据时发送,类似于 Proxy-Authenticate,在代理场景下使用 Proxy-Authenticate,其他情况下使用 WWW-Authenticate |
3.5.4 实体首部
实体首部提供了有关实体及其内容的大量信息,可以告知报文的接收者它在对什么进行处理。
| 首部名 | 描述 | 作用 |
|---|---|---|
| Allow | 列出对特定网络资源支持的 HTTP 方法 | 允许客户端了解哪些 HTTP 方法在该资源上可用 |
| Location | 提供一个将客户端重定向到资源的 URI | 在资源被移动或删除时,用于告知客户端新的位置,通常用于重定向操作。 |
内容首部
| 首部名 | 描述 | 作用 |
|---|---|---|
| Content-Base | 为 relative URL 提供基础 URI,用于将 HTML 中的链接转换为绝对 URL | 用于在将 HTML 文档保存到磁盘时保留 URL 的根路径 |
| Content-Encoding | 指示实体主体已经压缩的编码格式 | 允许客户端采取适当的解压方法处理主体内容 |
| Content-Language | 指示实体主体使用的自然语言 | 允许客户端了解主体内容所使用的语言,从而可以自动翻译内容为客户端所需要的语言 |
| Content-Length | 实体主体的长度(以字节为单位) | 用于告知客户端实体主体的大小,以便它能够确保接收到完整的实体主体 |
| Content-Location | 提供与实体主体相关的 URI | 在将相同内容的文档发布到不同的 URI 或将一份文档拆分成多个 URI 时,用于告知客户端当前资源的 URI |
| Content-MD5 | 实体主体使用的 MD5 校验和 | 允许接收方验证实体主体是否已损坏 |
| Content-Range | 表示该响应中发送了实体的哪部分,用于支持分段下载 | 用于告知客户端实体主体的偏移量和长度,从而可以实现文件的分段下载 |
| Content-Type | 指定实体主体的 MIME 类型 | 用于告知客户端如何理解实体主体,以及如何处理实体主体中的数据 |
实体缓存首部
| 首部名 | 描述 | 作用 |
|---|---|---|
| ETag | 在资源发生变化时,用于标识该资源的当前状态 | 允许客户端在以后发出的请求中使用 If-Match 和 If-None-Match 头部,判断资源是否已经被修改 |
| Expires | 指定在该日期之后资源将被认为过期的日期 / 时间 | 用于在客户端不访问缓存服务器的情况下确保资源不被缓存太久 |
| Last-Modified | 指示资源上一次修改的日期 / 时间 | 允许客户端控制缓存版本,以便缓存服务器只缓存内容的最新版本。客户端可以使用 If-Modified-Since 头部来检查资源是否已经被修订。 |
第4章 连接管理
4.5 持久连接
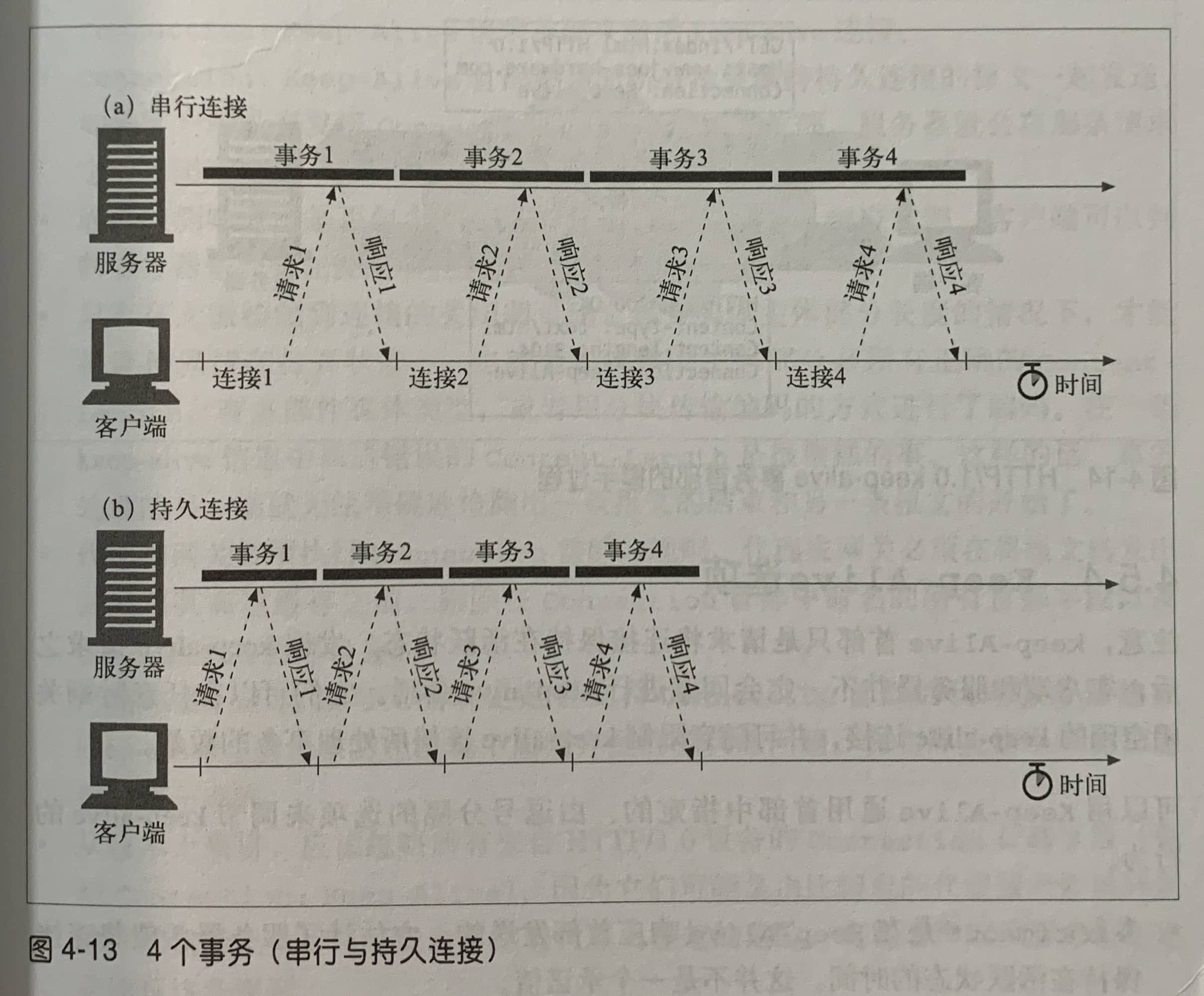
HTTP/1.1允许HTTP设备在事务处理结束之后将TCP连接保持在打开状态,以便为未来的HTTP请求重用现存的连接。在事务处理结束之后仍然保持在打开状态的TCP连接被称为持久连接。非持久连接会在每个事务结束之后关闭。持久连接会在不同事务之间保持打开状态,直到客户端或服务器决定将其关闭为止。
持久连接去除了进行连接和关闭连接的开销。
HTTP/1.1下,持久连接默认情况下所示激活的。除非特别指明,否则HTTP/1.1假定所有连接都是持久的。除非响应中包含了Connection: close首部,不然HTTP/1.1连接就仍维持在打开状态。但是,客户端和服务器仍然可以随时关闭空闲的连接,不发送Connection: close并不意味着服务器承诺永远将连接保持在打开状态。
4.6 管道化连接
管道化连接指的是在发送请求后,客户端可以在收到服务端的响应前先发送另一个请求,从而实现多个请求并行处理的机制。这种机制可以极大地提高网络通信的效率,因为服务端在处理一个请求时可能需要一段时间,此时客户端可以利用这段时间发送其他请求,从而减少等待时间,提高数据传输的速率。
管道化连接的优点是可以通过减少通信时的等待时间来提高数据传输的效率,尤其对于需要请求多个资源的应用程序而言,可以有效减少请求的响应时间。
管道化连接存在的问题主要是在服务端对请求的处理顺序以及缓存的管理上可能会出现一些不可避免的冲突,这可能导致后续请求的延迟或者失败。另外,在某些条件下,管道化连接可能还会导致网络拥塞和不必要的流量消耗,造成网络传输效率的降低。HOL队头阻塞。
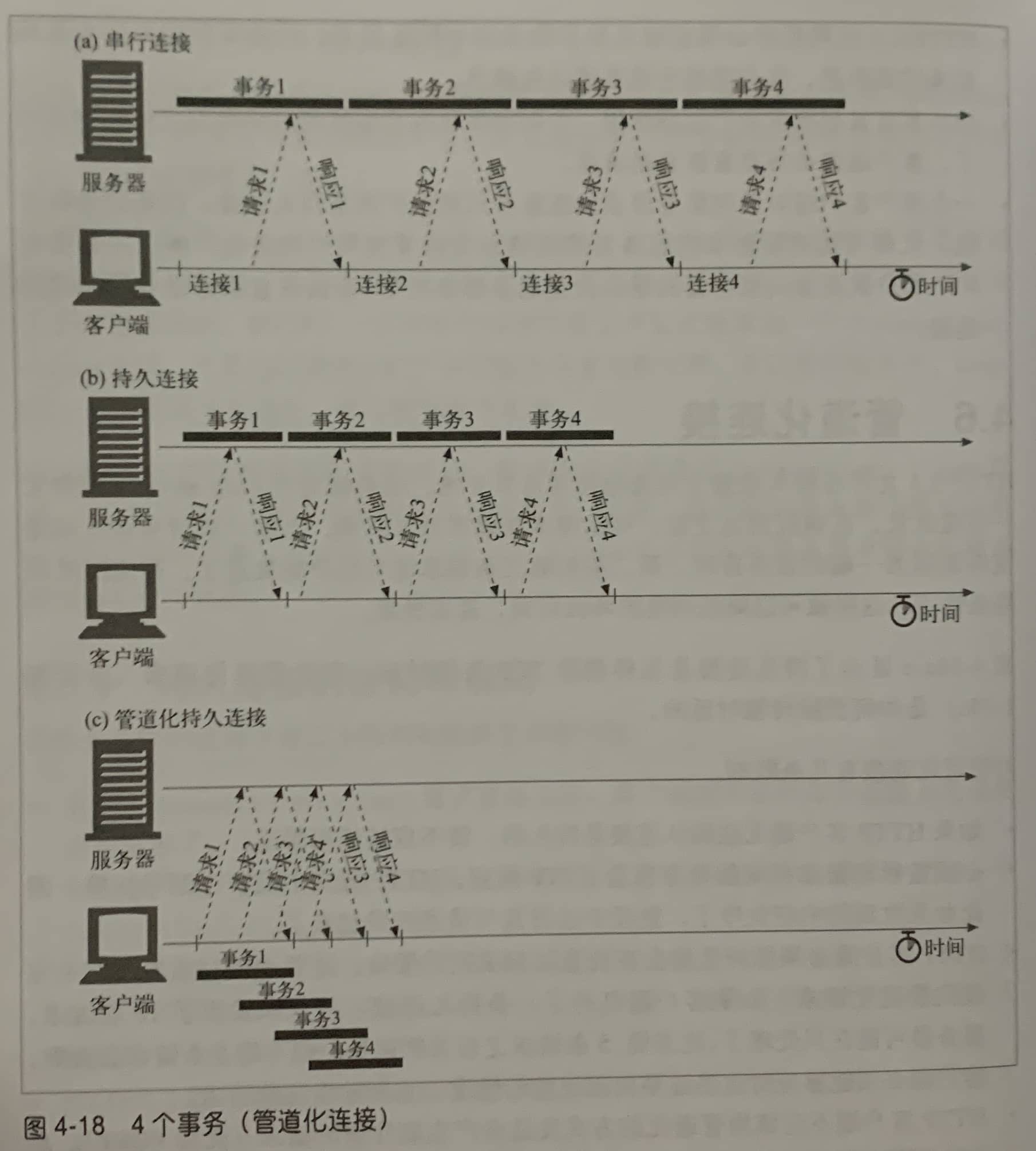
HTTP/2不再使用HTTP/1.x中的Connection、Keep-Alive和Transfer-Encoding首部字段、以及分块传输编码和多个连接等机制,这些机制的一部分被HTTP/2所替代或舍弃。
第7章 缓存
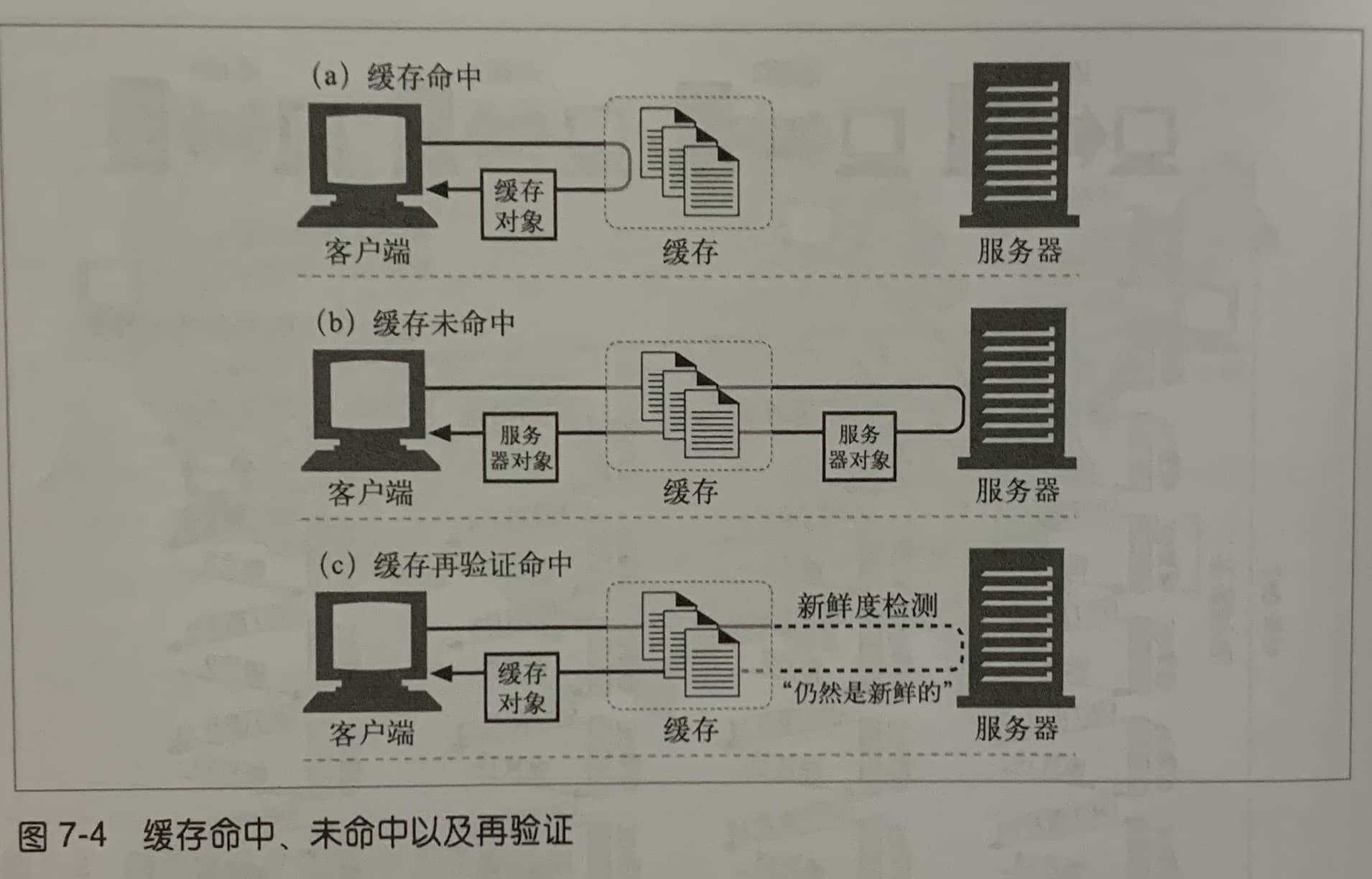
- 强缓存
强缓存是通过Expires和Cache-Control头部字段控制的。当浏览器第一次请求一个资源后,在资源的响应头中设置Expires或Cache-Control的max-age指令来指定缓存的过期时间,以后只要在这段时间内再次请求该资源,浏览器就可以直接从缓存中取得资源,而不必向服务器请求。因为该缓存策略不需要向服务器请求,因此被称为“强缓存”。
Expires使用的是绝对时间,Expires的过期时间是根据服务器时间来计算的,如果客户端和服务器的时间不同步,就可能会导致缓存出现问题。Cache-Control使用的是相对时间。
Cache-Control头部字段是HTTP/1.1中定义的一个缓存机制,可以控制客户端和服务器如何缓存响应,并且提供更加细粒度的缓存控制。
Cache-Control包含了多个指令,每个指令都对应了一种对缓存的约束。这些指令都可以在Cache-Control字段中以逗号分隔的方式列出,并且每个指令都有自己的语法和语义。下面是常用指令的一些说明:
no-cache: 指定需要重新验证缓存的有效性。服务器在返回响应之前验证是否可以使用缓存中的响应数据,并在必要时重新生成响应。当no-cache设置为true时,客户端和代理服务器在使用缓存的响应前,需要先与服务器进行确认,确认响应仍然有效,才可以使用缓存。
no-store: 禁止缓存响应。如果设置no-store,则响应不会被缓存,每次请求都会重新获取响应。
max-age: 指定缓存持续的最长时间,单位为秒。例如,max-age=3600表示响应可以被缓存1小时。
must-revalidate: 在缓存过期后,下一次请求必须重新从服务器获取响应。也就是说,当设置must-revalidate为true时,缓存的响应失效后,必须进行重新验证,如果响应仍然有效,则可以缓存响应;否则就需要从服务器获取新的响应。
public: 响应可以被任何缓存所缓存。
private: 响应只被特定的客户端缓存,例如浏览器的缓存。
no-transform: 禁止代理服务器修改响应的实体内容。
immutable: 可以将响应看做是不可变的,即使在向服务器进行验证后,响应的实体内容也不会发生变化。如果设置了immutable,则可以通过缓存响应来提高性能,并且无需进行服务器验证。
除了上述指令,还有其他一些指令,例如s-maxage(仅适用于共享缓存),proxy-revalidate(只针对代理服务器),no-cache="field-name"(仅在指定的响应头字段发生改变时才需要重新验证缓存),等等。
在使用Cache-Control头部字段时,可以将多个指令以逗号分隔的方式列出。例如,Cache-Control: no-cache, max-age=3600。可以指定多个指令来控制缓存策略,从而满足不同的应用场景。
- 协商缓存
协商缓存是通过Last-Modified和ETag头部字段控制的。当浏览器第一次请求一个资源后,在资源的响应头中设置Last-Modified和ETag两个字段,分别记录了资源最后修改的时间和资源内容的唯一标识符。再次请求该资源时,浏览器会带上If-Modified-Since或If-None-Match请求头,分别对应上次请求的Last-Modified或ETag,向服务器请求该资源的最新状态。如果服务器判断该资源状态未发生变化,则返回304 Not Modified响应,告诉浏览器可以使用本地的缓存副本。这种缓存策略需要向服务器请求,因此被称为“协商缓存”。
Last-Modified和ETag都是HTTP头部字段,可以用于协商缓存,从而控制浏览器缓存的行为。它们的区别在于,Last-Modified记录了资源最后一次修改的时间,而ETag则是记录了一个针对资源内容的唯一标识符,例如文件的MD5哈希值或数据库表的版本号。相比ETag,Last-Modified有以下缺点:
Last-Modified只能精确到秒级别,如果同一秒钟内修改了多次,就无法区分出具体哪一次修改是最新的。
有些文件系统并不支持Last-Modified,例如一些网络文件系统(NFS),这可能会影响其正确性。
如果文件的最后修改时间被错误地更改,那么它的Last-Modified就会失去准确性,可能导致客户端接收到更新后的文件,而实际上文件本身却可能并没有更改。
Last-Modified是依赖于时间的,如果服务端的时间与客户端的时间不同步,可能会导致误差,而ETag则不需要依赖于时间,可以提供更加准确的判断和缓存控制。
相比之下,ETag的实现更加准确并且更可靠。当内容发生改变时,ETag总是会产生不同的值,并且可以使用Hash算法来计算文件的ETag值,这样更有保证。因此,现代Web应用中,建议使用ETag进行缓存控制。
- 使用场景
由于这两种缓存机制的实现方式不同,因此它们的使用场景也不同。强缓存一般用于静态文件,如图片、css、js等,因为这些资源的内容相对不变,可以直接使用最近一次请求返回的响应结果。协商缓存则适用于动态内容,如HTML页面,由于内容具有一定的动态性,因此需要进行缓存的条件判断。协商缓存可以提供更高的缓存命中率,减少了无效请求的发送,从而减轻了服务器的压力。
- 优先级
强缓存优先级高于协商缓存。如果存在强缓存,浏览器会直接从缓存中取出资源,并忽略协商缓存的请求。只有在强缓存失效后,才会发送协商缓存请求。如果协商缓存仍然可以使用,则服务器返回304 Not Modified响应,否则返回200 OK响应,并附带最新的资源内容。
Cache-Control > Expires > ETag(If-None-Match) > Last-Modified(If-Modified-Since)
第11章 客户端识别与cookie机制
HTTP最初是一个匿名、无状态的请求/响应协议。服务器处理来自客户端的请求,然后向客户端回送一条响应。Web服务器几乎没有信息可以用来判定是哪个用户发送的请求,也无法记录来访用户的请求序列。

cookie分为会话cookie和持久cookie。会话cookie是一种临时cookie,当用户退出浏览器时,会话cookie就被删除了。持久cookie存储在硬盘上,浏览器退出,计算机重启后它们仍然存在。如果没有设置Expires或Max-Age参数,这个cookie就是一个会话cookie。
cookie的基本思想就是让浏览器积累一组服务器特有的信息,每次访问服务器时都将这些信息提供给它。cookie是由服务器贴到客户端上,由客户端维持的状态片段,只会回送给那些合适的站点。
当服务器需要向客户端浏览器发送一个Cookie时,可以在HTTP响应头中使用Set-Cookie字段来设置。以下是Set-Cookie字段的所有字段以及它们的含义和作用的详细列表:
| 字段名 | 含义和作用 |
|---|---|
| Name | Cookie的名称 |
| Value | Cookie的值 |
| Domain | 可以访问该Cookie的域名 |
| Path | 可以访问该Cookie的路径 |
| Expires | Cookie的过期时间 |
| Max-Age | Cookie的最大使用期限,以秒为单位 |
| Secure | 仅通过HTTPS连接发送Cookie |
| HttpOnly | 该Cookie只能通过HTTP请求发送,而无法通过脚本访问 |
| SameSite | 设置Cookie的SameSite属性,可以防止跨站点请求伪造攻击(CSRF) |
其中,Name和Value是必需的字段,其余字段都是可选的。Expires和Max-Age只需指定其中一个字段。Secure、HttpOnly和SameSite属性可以组合使用来增强Cookie的安全性。
第12章 基本认证机制
HTTP提供了一个原生的质询/响应框架,简化了对用户的认证过程。
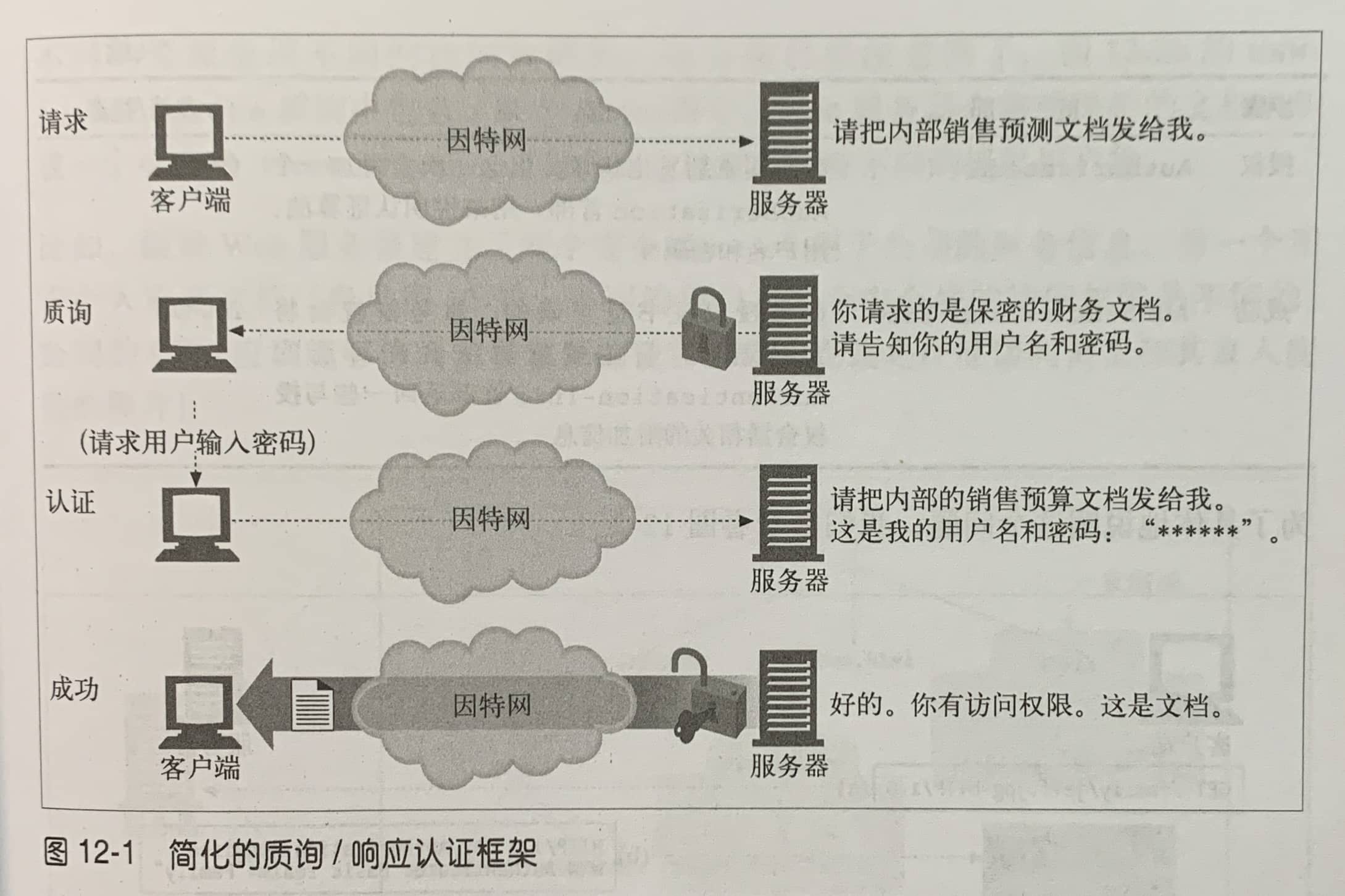
HTTP定义了两个官方的认证协议:基本认证和摘要认证。



基本认证需跟HTTPS结合,因为在HTTP下密码是以明文形式传输,任何人都可以读取并将其捕获。
MIME类型
