
[TOC]
第一部分 Linux命令行
第1章 初识Linux shell
1.1 什么是linux
Linux分为四部分:
- Linux内核
- GNU工具
- 图形化桌面环境
- 应用软件
1.1.1 深入探究Linux内核
内核负责以下四种功能:
系统内存管理
软件程序管理
运行中的程序称为进程,进程可以在前台运行,输出显示在屏幕上,也可以在后台运行,隐藏到幕后。
Linux内核会创建第一个init进程来启动系统上所有其他进程。
硬件设备管理
驱动程序代码相当于应用程序和硬件设备的中间人,允许内核与设备之间交换数据。
文件系统管理
1.1.2 GNU工具
GNU组织(GNU's Not Unix)开发了一套完整的Unix工具。GNU是一套操作系统工具。
核心GNU工具
GNU coreutils软件包由三部分构成:
- 用以处理文件的工具
- 用以操作文本的工具
- 用以管理进程的工具
shell
shell是一种特殊的交互式工具。它为用户提供了启动程序、管理文件系统中的文件以及运行在Linux系统上的进程的途径。shell的核心是命令行提示符,它允许你输入文本命令,然后解释命令,并在内核中执行。
将多个shell命令放入文件中作为程序执行的文件称为shell脚本。所有Linux发行版默认的shell都是bash shell。
几种常见的shell:
ash
korn
tcsh
zsh
一种结合了bash、tcsh和korn的特性,同时提供高级编程特性、共享历史文件和主题化提示符的高级shell
1.1.3 Linux桌面环境
- X Window系统
- KDE桌面
- GNOME桌面(Red Hat Linux)
- Unity桌面(ubuntu)
- 其他桌面
1.2 Linux发行版
完整的Linux系统包称为发行版。
Linux发行版通常归类为3种:
完整的核心Linux发行版
代表有:
- Slackware
- Red Hat
- Gentoo
特定用途的发行版
代表有:
- CentOS
- Ubuntu
- PCLinuxOS
LiveCD测试发行版
通过CD来启动PC,无需在硬盘安装任何东西就能运行LInux发行版
代表有:
- Knoppic
- Ubuntu
- PCLinuxOS
第2章 走进shell
2.2 通过Linux控制台终端访问CLI
在很多Linux发行版中,在完成启动过程之后会切换到图形化环境。
可以使用(Ctrl+Alt)+F1~F7功能键进入虚拟控制台。
在Linux虚拟控制台中是无法运行任何图形化程序的。
setterm -background white可修改背景色,-foreground修改字体颜色。
如果要在GUI(图形化界面)访问CLI,可以使用终端仿真软件包。
2.3 通过图形化终端仿真访问CLI
常用的有GNOME Terminial、Konsole Terminial和xterm。
第3章 基本的bash shell命令
3.1 启动shell
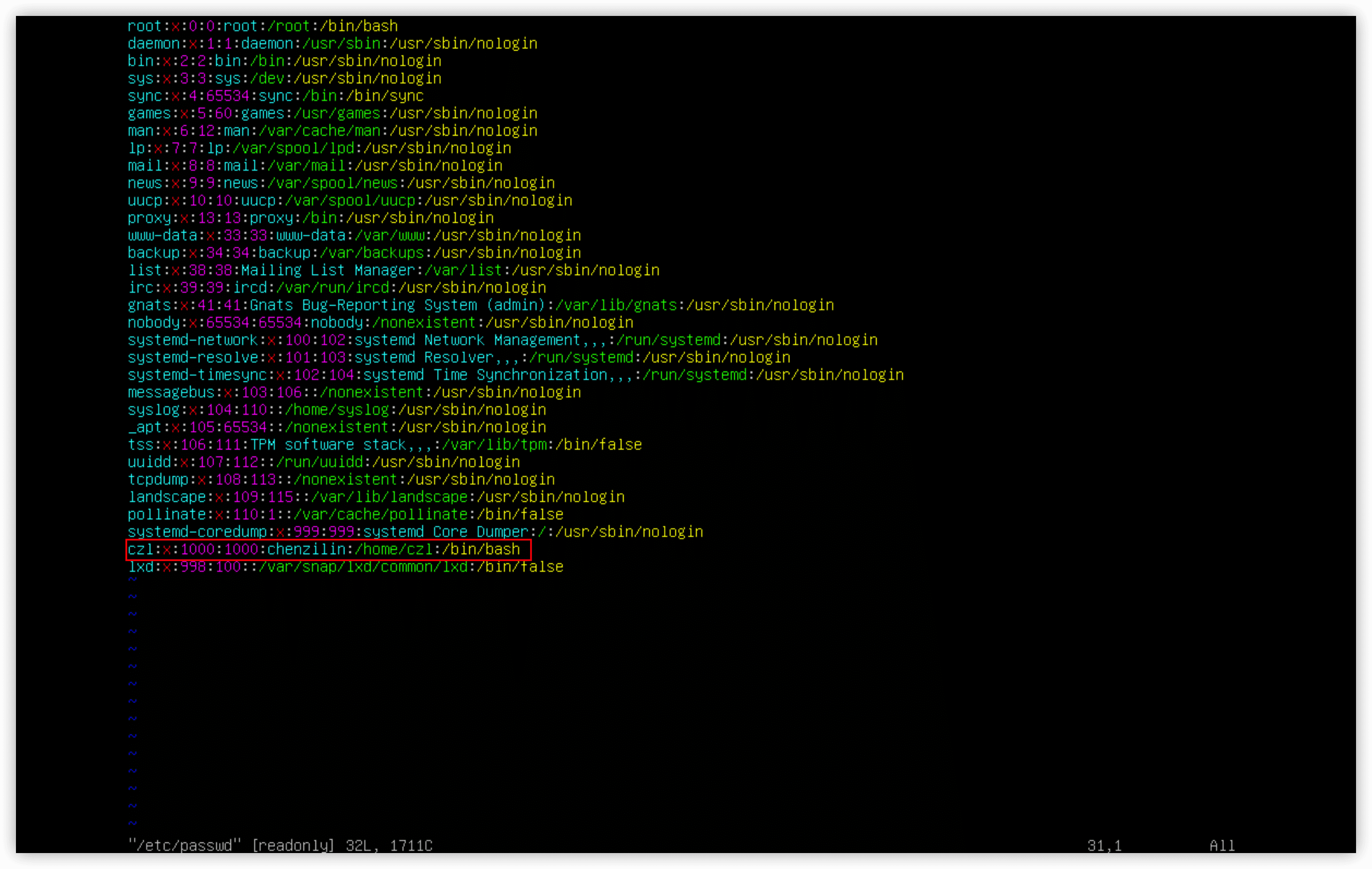
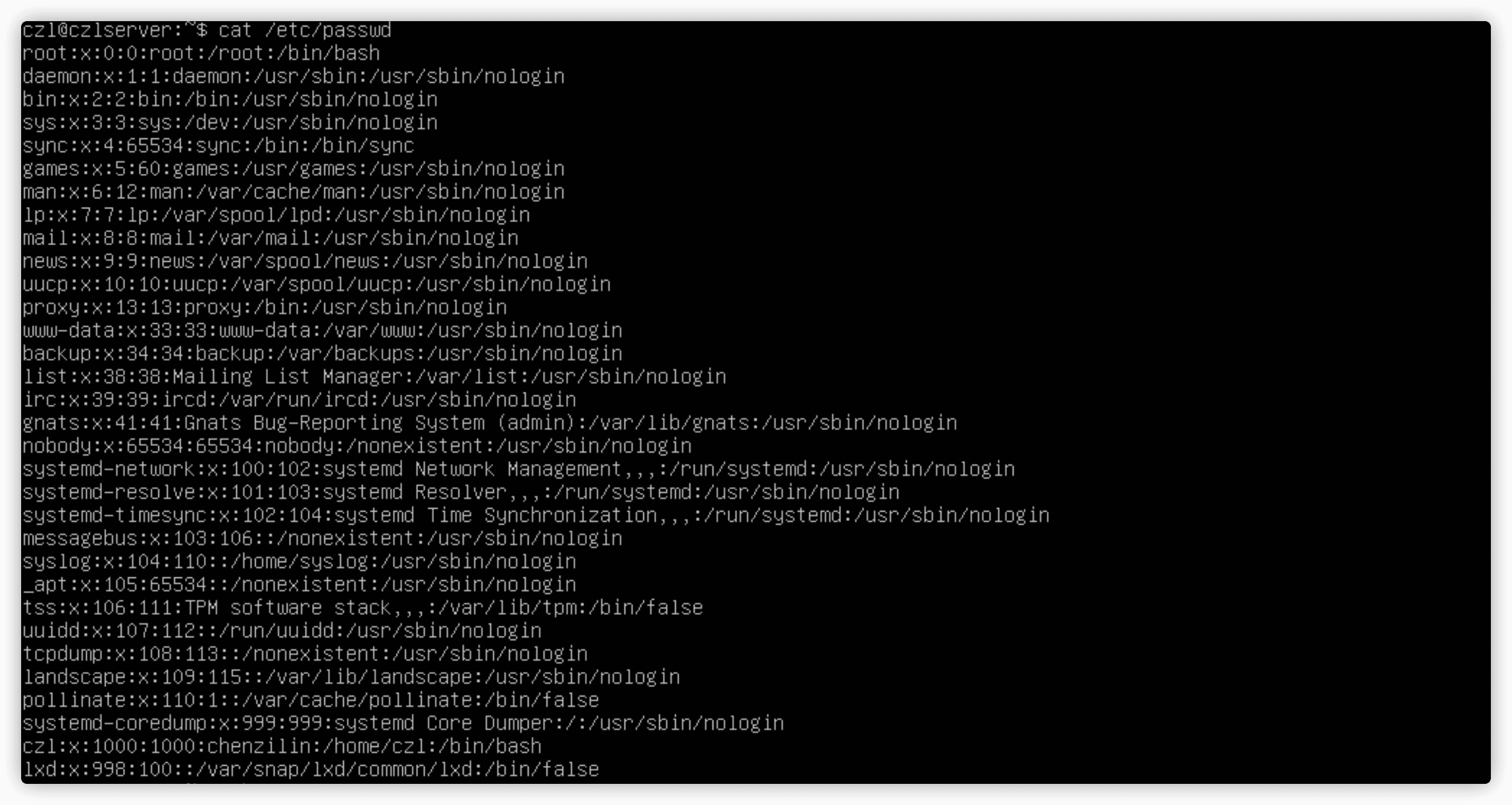
/etc/passwd文件包含了所有系统用户账户列表以及每个用户的基本配置信息。
3.2 shell提示符
默认bash shell提示符是美元符号($),这个符号表明shell在等待用户输入。
3.3 bash手册
man命令用来访问存储在Linux系统上的手册页面。man xxx。
man -k terminal查找与终端相关的命令。
还有一种叫做info页面的信息,输入info xxx查看info页面的相关内容。
也可以查看帮助信息,通过-help或者--help选项。
3.4 浏览文件系统
3.4.1 Linux文件系统
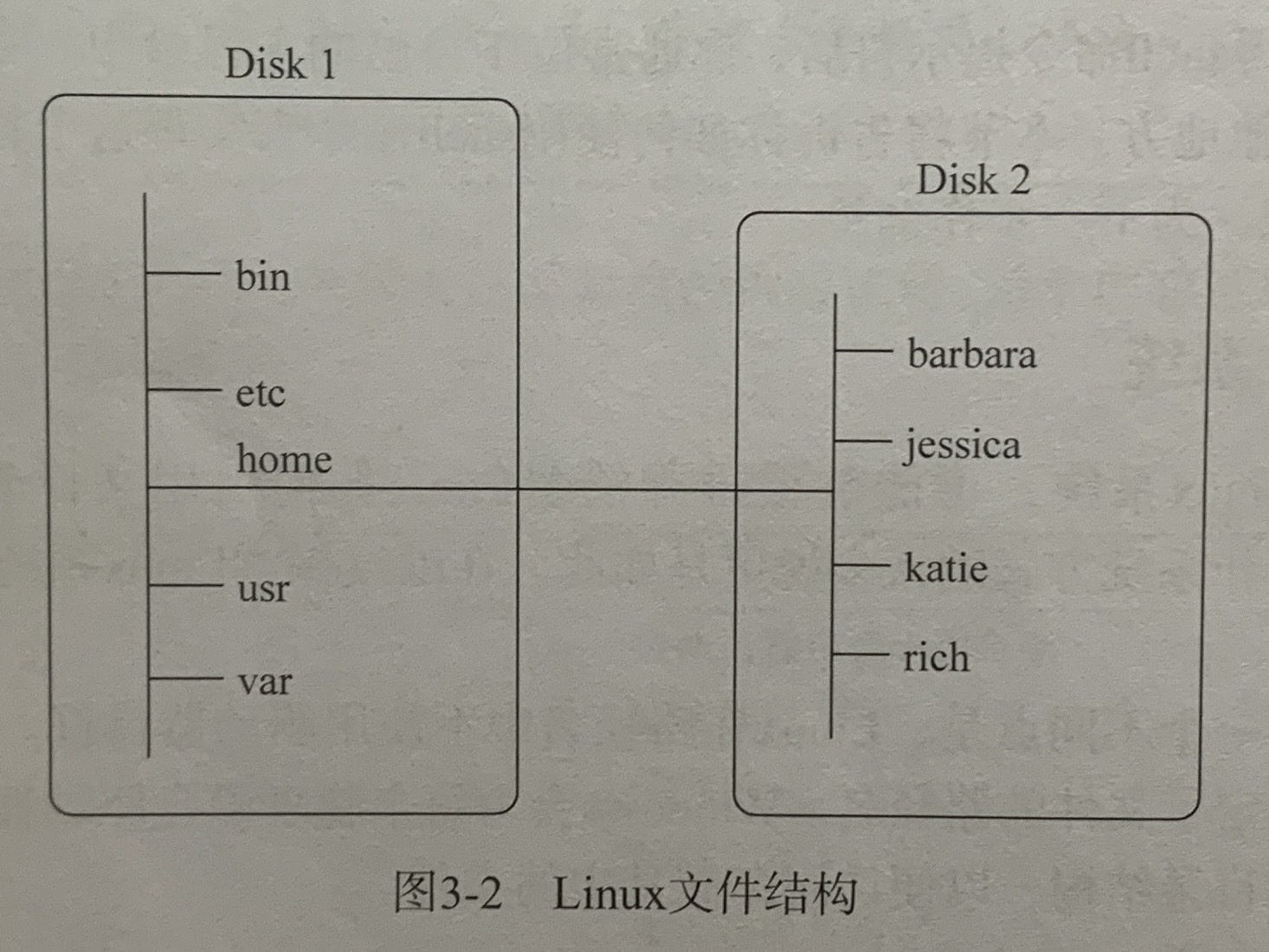
Linux将文件存储在单个目录结构中,这个目录被称为虚拟目录(virtual directory)。虚拟目录将安装在PC上的所有存储设备的文件纳入单个目录结构中。Linux虚拟目录结构只包含一个称为根(root)目录的基础目录。
在Linux中,反斜线(\)用来标识转义字符,文件路径用斜线(/)表示。
在Linux上安装的第一块硬盘称为根驱动器。根驱动器包含了虚拟目录的核心,其他目录都是从那里开始构建的。Linux会在根驱动器上创建一些特别的目录,称为挂载点(mount point)。挂载点是虚拟目录中用于分配额外存储设备的目录。虚拟目录会让文件和目录出现在这些挂载点目录中,然而实际上它们却存储在另外一个驱动器中。

3.5 文件和目录列表
3.5.1 基本列表功能
ls查看当前目录的文件列表。
-F用来区分文件和目录。
-R表示递归选项,可以显示目录的子目录中的文件。
3.5.1 显示长列表
-l显示长列表。
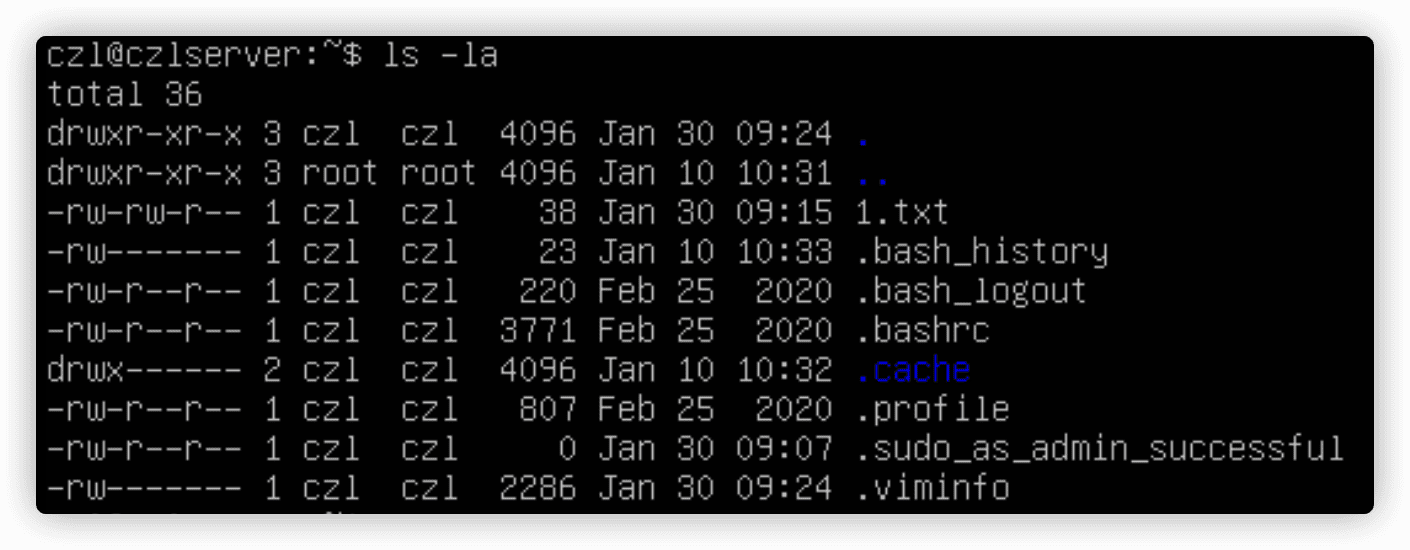
每一行都包含了关于文件(或目录的)的下述信息:
- 文件类型,比如目录(d)、文件(-)、字符型文件(c)或块设备(b);
- 文件的权限;
- 文件的硬链接总数;
- 文件属主的用户名;
- 文件属组的组名;
- 文件的大小(字节);
- 文件的上次修改时间;
- 文件名或目录名。
3.5.3 过滤输出列表
在命令行参数之后添加过滤参数,比如ls -l my_script。
通配符(正则)匹配:
?代表一个字符。*代表零个或多个字符。
ls -l f[a-i]ll。
3.6 处理文件
3.6.1 创建文件
touch用于创建空文件。
3.6.2 复制文件
cp soure destination用于复制文件。
-i,强制shell咨询是否需要覆盖已有文件。
-R递归地复制整个目录的内容。
cp * Document/将所有文件和目录复制到Document目录下。
3.6.4 链接文件
如需要在系统上维护同一文件的两份或多份副本,除了保存多份单独的物理文件副本之外,还可以采用保存一份物理文件副本和多个虚拟副本的方法,这种虚拟的副本就称为链接。链接是目录中指向文件真实位置的占位符。
在Linux中有两种不同类型的文件链接:1.符号链接(软链接) 2.硬链接。
**符号链接(软链接)**就是一个实实在在的文件,它指向存放在虚拟目录结构中某个地方的另一个文件。
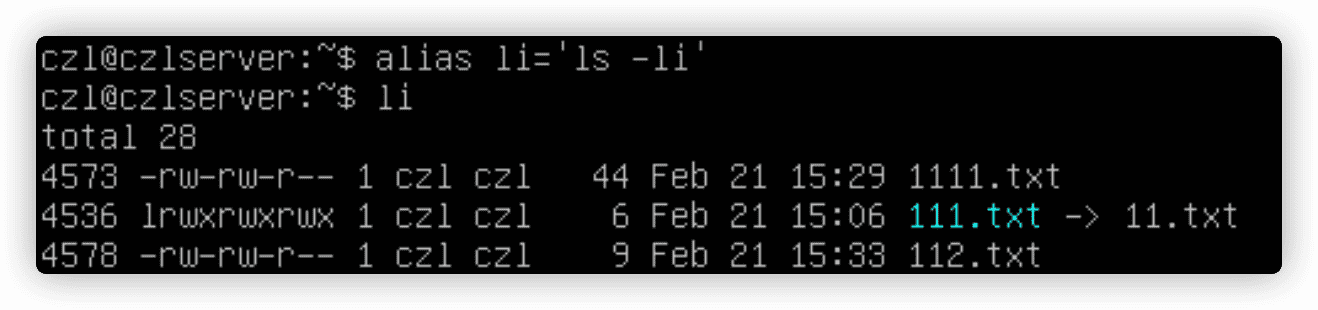
使用ln -s xxx xxx为一个文件创建符号链接,原始文件必须事先存在。
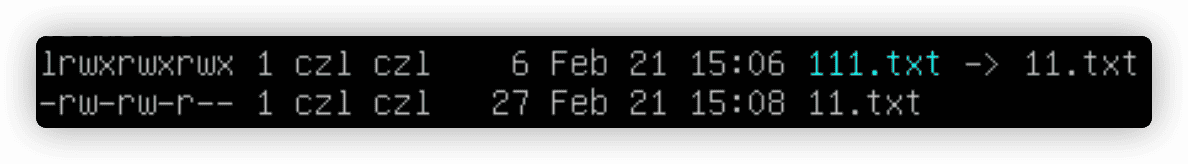
111.txt和11.txt是两个不同的文件,他们的大小不一样,另一种证明链接文件是独立文件的方法是查看inode编号。inode编号是一个用于标识文件或目录是唯一的数字,使用ls -i查看。
硬链接会创建独立的虚拟文件,其中包含了原始文件的信息及位置。但是它们从根本上而言是同一个文件。引用硬链接文件等同于引用了源文件。ln xxx xxx创建硬链接文件。
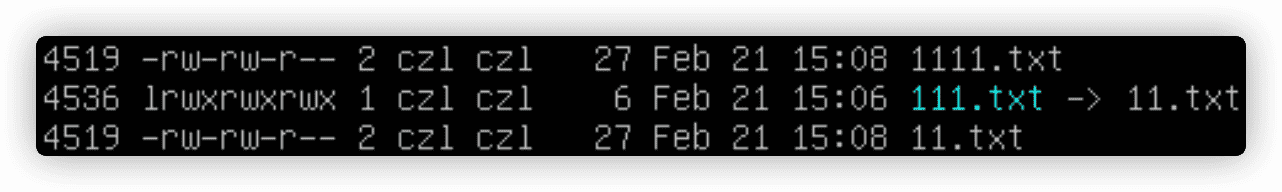
3.6.5 重命名文件
重命名文件称为移动(moving)。mv命令可以将文件和目录结构移动到另一个位置或者重命名。mv xxx xxxx。
移动文件的inode编号和时间戳不会改变。
3.6.5 删除文件
rm -i xxx提示并删除文件。
bash shell中没有回收站,文件一旦删除,就无法再找回。
可以通过通配符删除成组的文件。rm -i f?ll。
谨慎使用-f选项进行强制删除。
3.7 处理目录
3.7.1 创建目录
mkdir xxx创建目录。
mkdir -p xx/xxx/xxxx创建多个目录和子目录。
3.7.2 删除目录
rmdir xxx默认只能删除空目录。
rm -rf xxx删除目录及其所有内容,-r代表递归,-f代表强制删除。
3.8 查看文件内容
3.8.1 查看文件类型
file xxx 可以查看文件的类型。
在 Linux 和 Unix 系统中,有多种不同的文件类型,常见的有:
- 常规文件(REG):普通的文本或二进制文件,如 .txt、.pdf、.jpg 等。
- 目录(DIR):文件夹,用于存储文件和其他目录。
- 字符设备(CHR):字符设备文件,如终端设备、串口、普通文件等。
- 块设备(BLK):块设备文件,如磁盘、硬盘、光驱等。
- 命名管道(FIFO):FIFO 文件,用于在不同进程间进行通信。
- 符号链接(LNK):符号链接,用于指向其他文件或目录。
- 套接字(SOCK):套接字文件,用于在不同主机之间进行网络通信。
- 共享内存(SHM):共享内存文件,用于在不同进程间共享数据。
还有其他文件类型如:
- 路径名(DOOR):用于在不同进程间通信
- 事件通知(EVENT):用于进程间的事件通知
- 半双工管道(PIPE):用于半双工通信
这些文件类型只是部分, 具体取决于操作系统的版本和实现。
3.8.2 查看整个文件
1. cat命令
cat xxx。
-n选项给所有的行加上序号。
-b选项给有文本的行加上行号。
-T选项不让制表符出现。
2. more命令
cat命令的缺陷是一旦运行,就无法控制后面的操作。more命令用于解决这个问题。
more xxx,more命令会在显示每页数据之后停下来。
3. less命令
less命令是more的升级版。能够在文本文件前后翻动,还有一些高级搜索功能。
3.8.3 查看部分文件
使用cat或more加载大型文件需要加载完整个才能看到,这不利于查看大型文件。
1.tail命令
tail命令会显示文件最后几行的内容。
-n选项修改所显示的行数,例如tail -n 20 xxx显示20行。
2.head命令
head命令显示文件开头的那些行的内容。
-n选项修改所显示的行数。
第4章 更多的bash shell命令
4.1 监测程序
4.1.1 探查进程
程序运行在系统上时,称之为进程(process)。
ps命令查看进程信息,默认只显示运行在当前控制台下的属于当前用户的进程。
ps命令支持3种不同类型的命令行参数:
- Unix风格的参数,前面加单破折号;
- BSD风格的参数,前面不加破折号;
- GNU风格的参数,前面加双破折号。
ps命令的参数非常多,记住全部是不太现实的,一般是记住最有用的参数即可。
-ef参数查看系统上运行的所有进程,-e显示所有进程,-f扩展了输出内容。
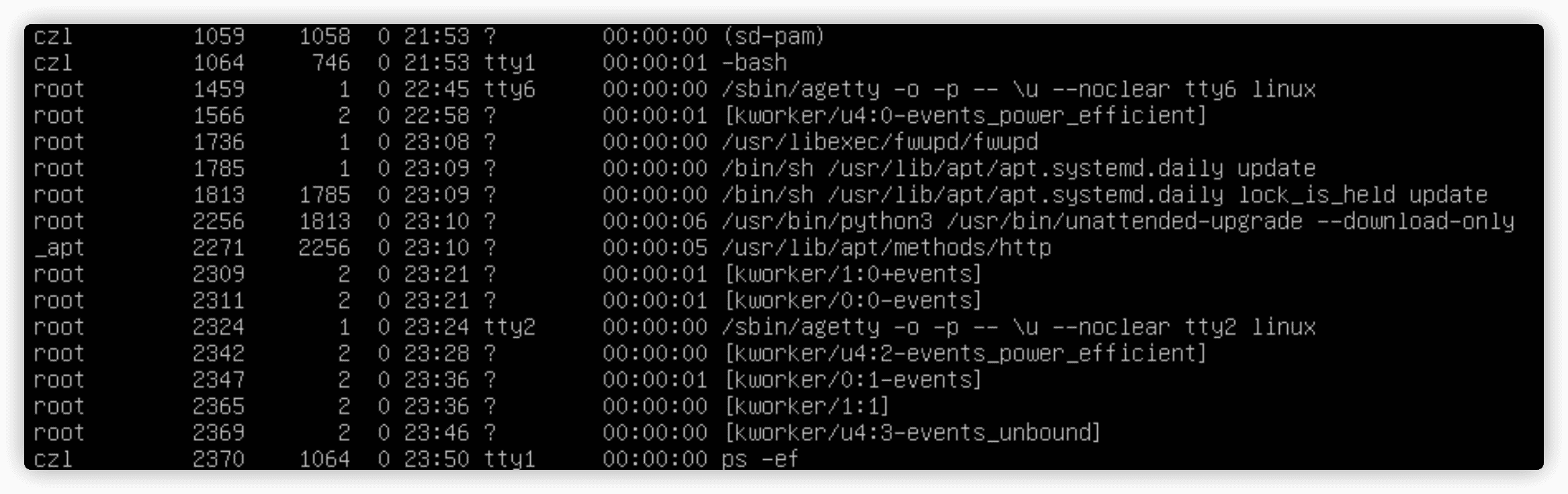

- UID:启动这些进程的用户。
- PID:进程ID。
- PPID:父进程的进程号(如果该进程是由另一个进程启动的)。
- C:进程生命周期中的CPU利用率。
- STIME:进程启动时的系统时间。
- TTY:进程启动时的终端设备。
- TIME:运行进程需要的累计CPU时间。
- CMD:启动的进程名称。
4.1.2 实时监测进程
ps命令只能显示某个特定事件点的信息。
top命令实时显示进程信息。
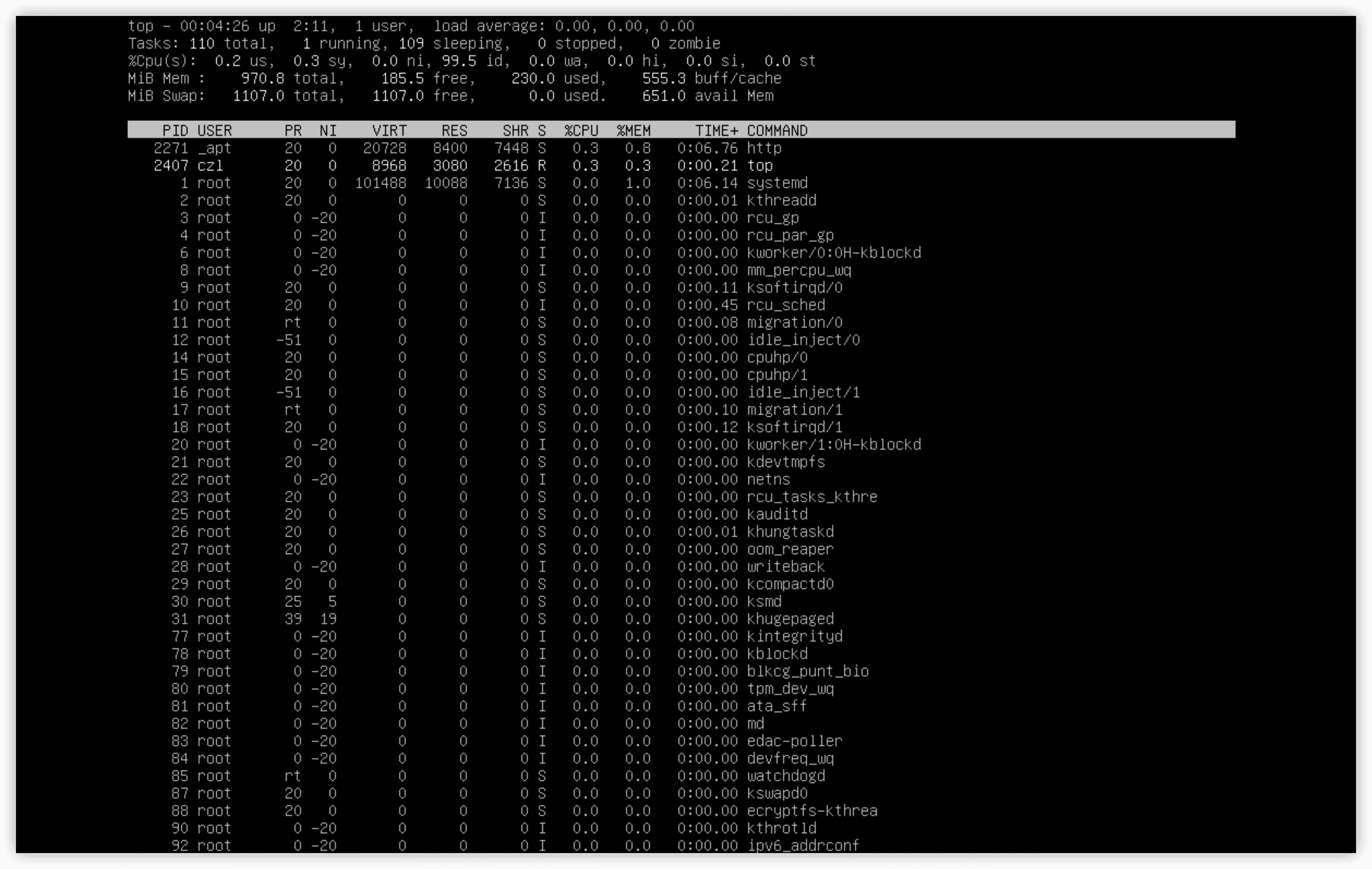
输出的第一部分显示的是系统的概况:第一行显示了当前时间、系统运行时间、登录的用户数以及系统的平均负载(load average)。
平均负载有3个值,最近1分钟的、最近5分钟的和最近15分钟的。值越大说明系统的负载越高。
通常系统的负载值超过2,说明系统比较繁忙了。
第二行显示进程的概要信息——top命令的输出中将进程叫做任务(task):运行、休眠、停止或者僵化状态。
第三行是CPU的概要信息。其后两行是系统内存的状态,第一行是物理内存,第二行是系统交换内存。
- PID:进程的ID。
- USER:进程属主的名字。
- PR:进程的优先级。
- NI:进程的谦让度值。
- VIRT:进程占用的虚拟内存总量。
- RES:进程占用的物理内存总量。
- SHR:进程和其他进程共享的内存总量。
- S:进程的状态。
- %CPU:进程使用的CPU时间比例。
- %MEN:进程使用的内存占可用内存的比例。
- TIME+:自进程启动到目前位置的CPU时间总量。
- COMMAND:进程所对应的命令行名称
在top命令运行时,键入d修改轮询间隔,键入f对输出进行排序的字段,键入q退出top。
4.1.3 结束进程
在Linux中,进程之间通过信号来通信。
| 信号 | 名称 | 描述 |
|---|---|---|
| 1 | HUP | 挂起 |
| 2 | INT | 中断 |
| 3 | QUIT | 结束运行 |
| 9 | KILL | 无条件终止 |
| 11 | SEGV | 段错误 |
| 15 | TERM | 尽可能终止 |
| 17 | STOP | 无条件停止运行,但不终止 |
| 18 | TSTP | 停止或暂停,但继续在后台运行 |
| 19 | CONT | 在STOP或TSTP之后恢复执行 |
有两个命令可以向运行中的进程发出进程信号。
1.kill命令
kill PID关闭进程。
要发送进程信号,必须是进程的属主或登录为root用户。
-s参数支持指定其他信号。
2.killall命令
killall支持通过进程名而不是PID来结束进程,也支持通配符,这在系统因负载过大而变得很慢时很有用。
killall http*结束所有以http开头的进程。
4.2 监测磁盘空间
4.2.1 挂载存储媒体
在使用新的存储媒体之前,需要把它放到虚拟目录下,这个过程称为挂载(mounting)。在图形化桌面环境里,大多数Linux发行版都支持自动挂载特定类型的可移动存储媒体。
1.mount命令
mount命令输出当前系统上挂载的设备列表。
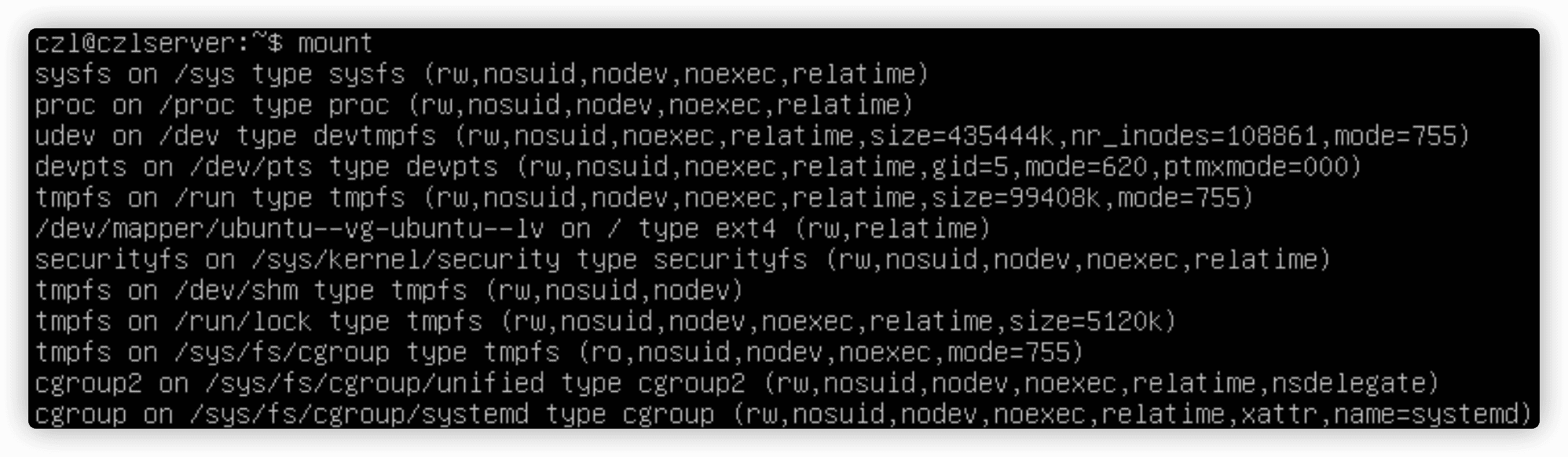
提供了四部分信息:
- 媒体的设备文件名
- 媒体挂载到虚拟目录的挂载点
- 文件系统类型
- 已挂载媒体的访问状态
mount -t vfat /dev/sbd1 /media/disk将U盘/dev/sbd1挂载到/media/disk。
2.umount命令
umount [directory | device]卸载设备。
4.2.2 使用df命令
df查看所有已挂载磁盘的使用情况,显示每个有数据的已挂载文件系统。
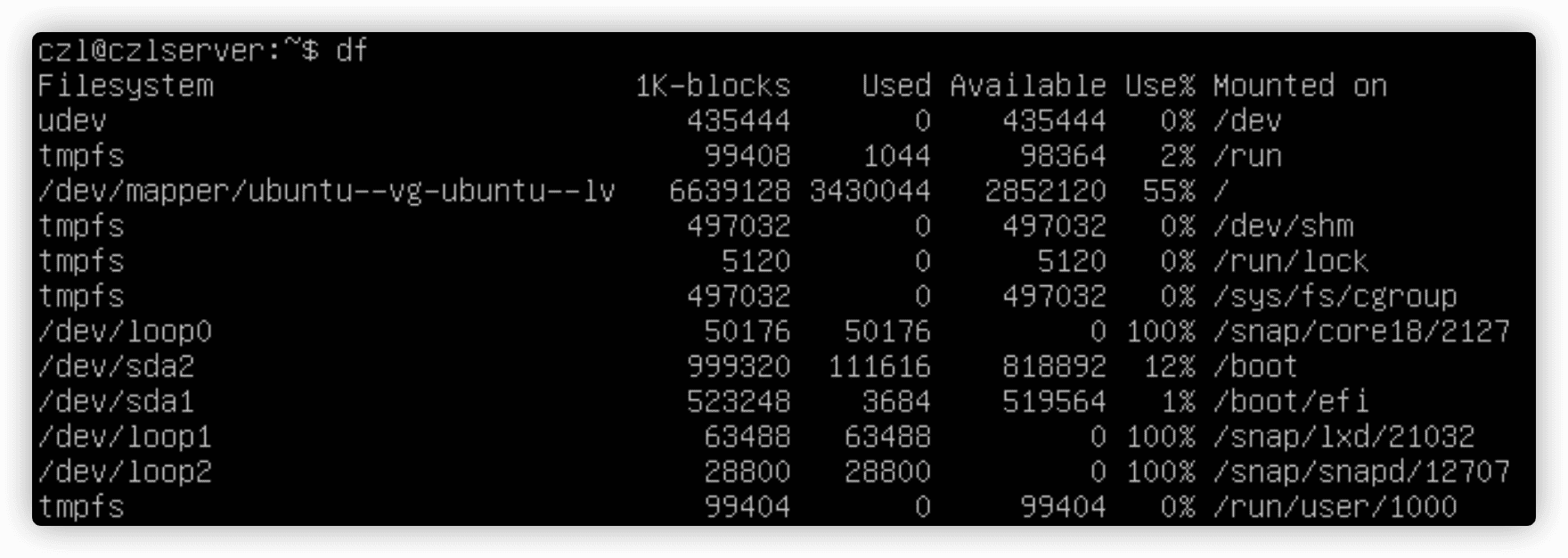
- 设备的设备文件位置;
- 能容纳多少个1024字节大小的块;
- 已用了多少个1024字节大小的块;
- 还有多少个1024字节大小的块可用;
- 已用空间所占的比例;
- 设备挂载到了哪个挂载点。
-h输出按照用户易读的方式显示。
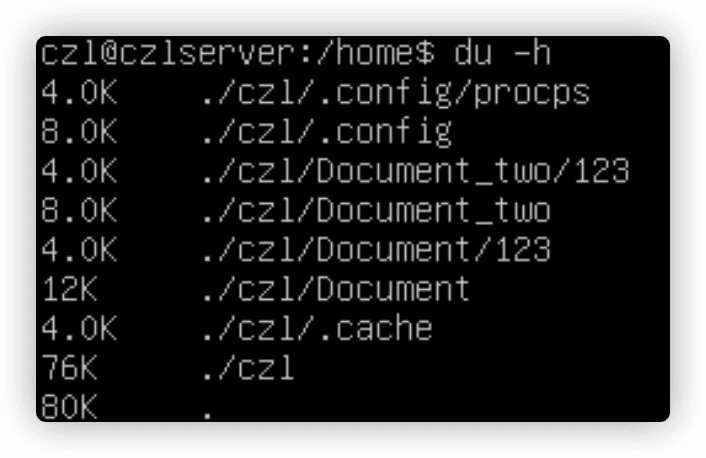
4.2.3 使用du命令
du显示某个特定目录(默认是当前目录)的磁盘使用情况,可用来快速判断系统上某个目录下是否有大文件。du不加参数用处不大。
-c显示所有已列出文件总的大小。-h易读的方式输出。-s显示每个输出参数的总计。
4.3 处理数据文件
4.3.1 排序数据
sort命令对数据进行排序,默认按照会话指定的默认语言的排序规则对文本文件中的数据进行排序。
-n告诉sort命令把数字识别成数字而不是字符。
-M按月排序。
-r降序排序。
4.3.2 搜索数据
grep命令查找数据,grep [options] pattern [file]。
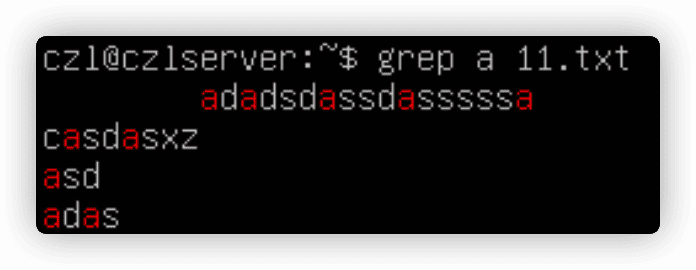
-n加入行显示。
-v反向搜索。
-c有多少行匹配。
-e多个匹配模式,grep -e aaa -e bbb xxx。
4.3.3 压缩数据
Linux文件压缩工具
| 工具 | 文件扩展名 | 描述 |
|---|---|---|
| bzip2 | .bz2 | 采用Burrows-Wheeler块排序文本压缩算法和霍夫曼编码 |
| compress | .Z | 最初的Unix文件压缩工具,已经快没人用了 |
| gzip(最流行) | .gz | GNU压缩工具,用Lempel-Ziv编码 |
| zip | .zip | Windows 上PKZIP工具的Unix实现 |
gzip xxx用来压缩文件。zcat查看压缩过的文本文件的内容。gunzip解压文件。
4.3.4 归档数据
zip命令只能压缩和归档单个文件。
使用tar命令进行文件归档。tar function [options] object1 object2 ...。

例:tar -cvf test.tar test/ test2/ 11.txt创建test.tar的归档文件,tar -xvf test.tar提取内容。
以
.tgz结尾的文件,是通过gzip压缩过的tar文件,可以用tar -zxvf filename.tgz来解压。
第5章 理解shell
shell是一个时刻都在运行的复杂交互式程序。
5.1 shell的类型

只要用户登录到某个虚拟控制台终端或是在GUI中启动终端仿真器,默认的shell程序就会开始运行。
有两种shell,一个是默认shell,一个是交互shell,默认shell是**/bin/sh**,用于那些需要在启动时使用的系统shell脚本。

/bin/dash命令启动dash shell。exit命令退出dash shell。
5.2 shell的父子关系
默认启动的交互shell是一个父shell,通过启动其他shell命令的新的shell程序,是一个子shell。
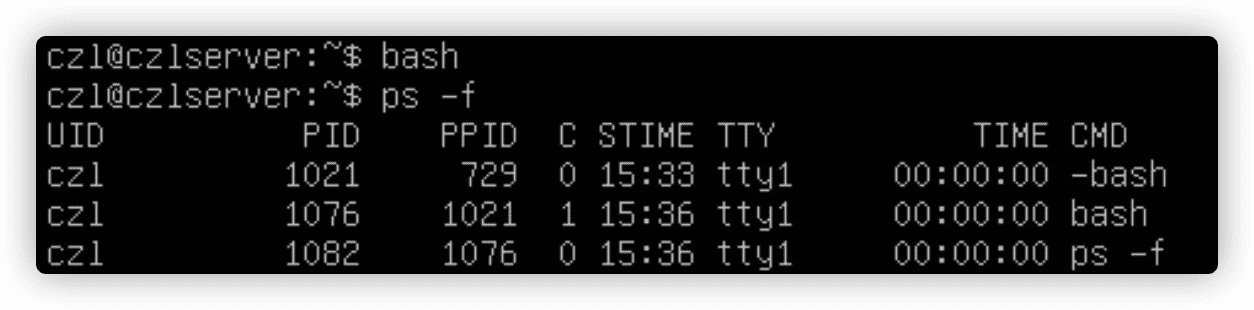
exit命令退出子shell。
5.2.1 进程列表
将命令包含在括号里,命令列表变成了进程列表,生成了一个子shell来执行对应的命令。
(pwd ; ls ; cd /etc ; pwd; cd ; pwd ; ls)。echo $BASH_SUBSHELL可以显示子shell的数量。

5.2.2 子shell用法
在交互式shell中,一个高效的子shell用法就是使用后台模式。
1.探索后台模式
sleep sceonds命令将进程等待(睡眠)多少秒。
&符号可以将命令置于后台运行。
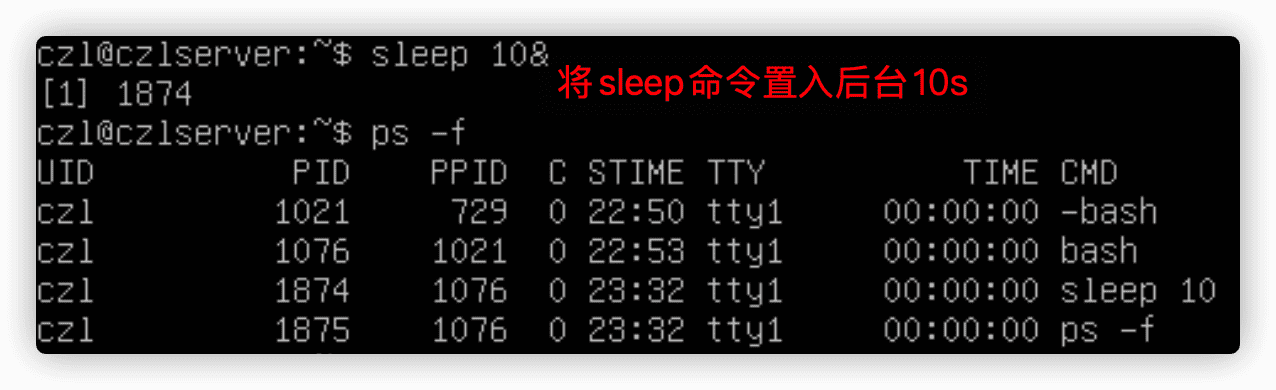
jobs命令显示后台作业信息。
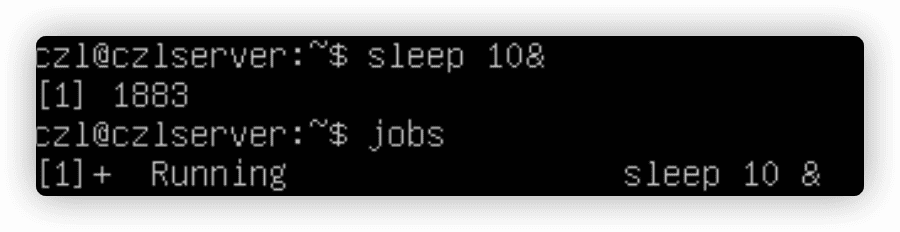
2.将进程列表置入后台
(sleep 2 ; echo $BASH_SUBSHELL ; sleep 2)&置于后台运行。
在CLI中运用子shell的创造性方法之一就是将进程列表置入后台模式。你既可以在子shell进行繁重的处理工作,同时也不会让子shell的I/O受制于终端。
3.协程
coproc命令创建协程,协程可以同时做两件事,在后台生成一个子shell,并在这个子shell中执行命令。
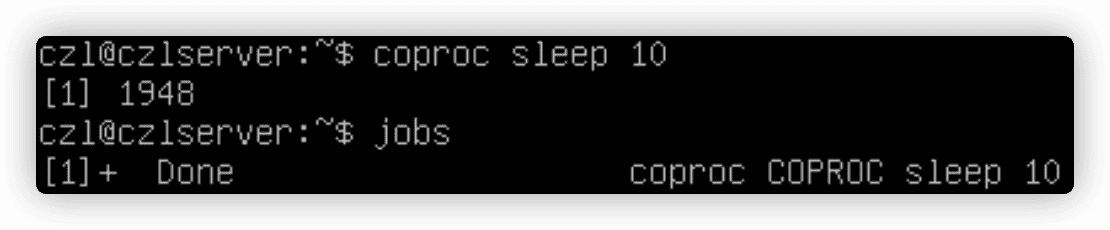
coproc my_job { sleep 10; } 修改协程的名字,这对使用多个协程时非常有用。
生成子shell的成本不低,速度还慢,要用好子shell,必须理解子shell的行为方式。
5.3 理解shell的内建命令
5.3.1 外部命令
外部命令,也被称为文件系统命令,存在于bash shell之外的程序,它们并不是shell程序的一部分。外部命令程序通常位于/bin、/usr/bin、/sbin和/usr/sbin中。
ps就是一个外部命令,可以使用which命令和type命令找到它。
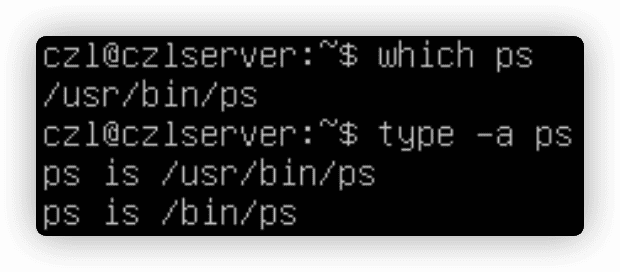
当外部命令执行时,会创建一个子进程,这种操作被称为衍生(forking)。

当进程必须执行衍生操作时,它需要花费时间和精力来设置新子进程的环境,因此外部命多少是有代价的。
5.3.2 内建命令
内建命令不需要使用子进程来执行,它们和shell编译成一体。
cd和exit命令都内建于bash shell。
type命令了解某个命令是否是内建的。
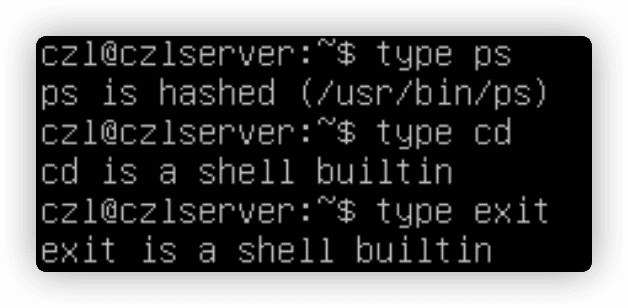
有些命令有多种实现,例如echo和pwd既有内建又有外部命令。type -a xx查看命令的不同实现。
which命令只显示外部命令文件。
1. history命令
这个命令会跟踪你用过的命令,查看最近用过的命令列表。
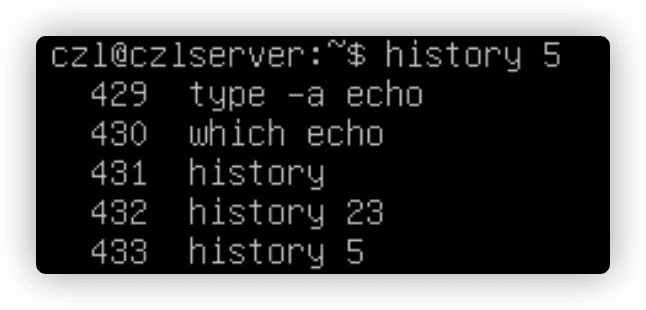
!!命令可以唤出刚刚用过的那条命令来使用。
命令历史记录被保存在隐藏文件.bash_history中,位于用户的主目录中。
2.命名别名
alias命令可以为常用的命令(及其参数)创建另一个名称,从而将输入量减少到最低。
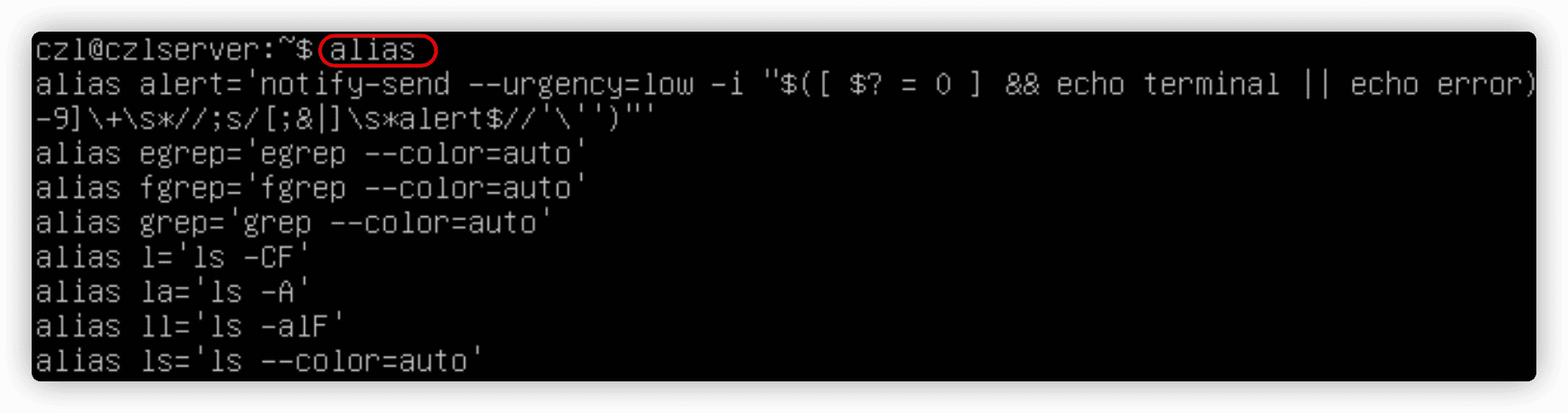
使用alias xx='xxx'创建别名。
因为命令别名属于内部命令,一个别名仅在它所被定义的shell进程中才有效。
第6章 使用Linux环境变量
6.1 什么是环境变量
bash shell用一个叫做环境变量(environment variable)的特性来存储相关shell会话和工作环境的信息,这项特性允许你在内存中存储数据,以便程序或shell中运行的脚本能够轻松访问到它们。
环境变量分为全局变量和局部变量。
全局环境变量
全局环境变量对于shell会话和所有生成的子shell都是可见的。局部变量则只对创建它们的shell可见。系统环境变量基本上使用大写字母,区别于普通用户的环境变量。
env和printenv命令查看全局变量。
printenv 环境变量名显示环境变量的值。也可以使用echo $变量名显示。
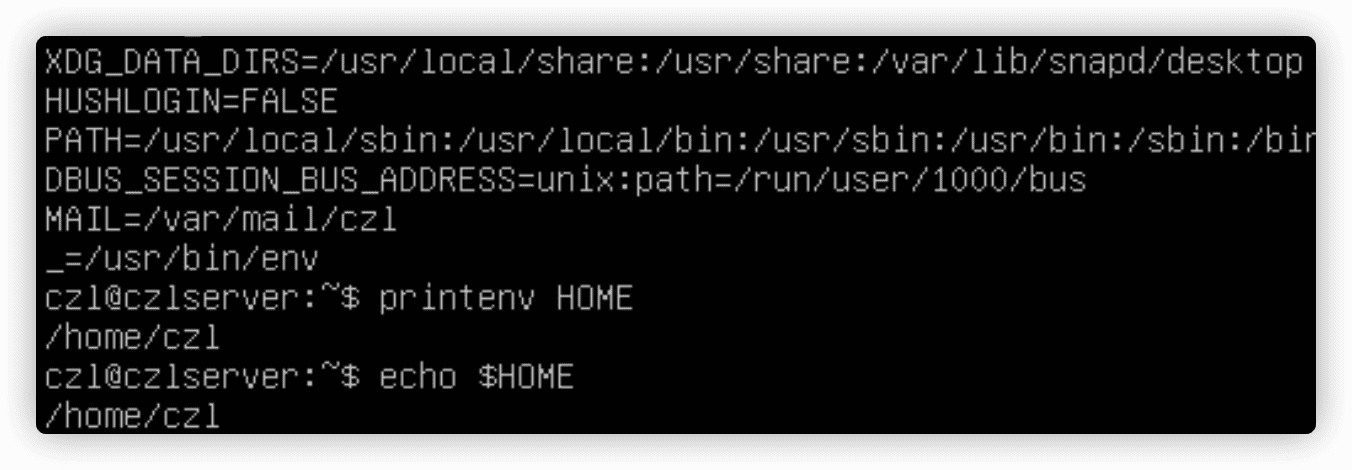
局部变量
局部变量只能在定义它们的进程中可见。
set命令显示全局变量、局部变量和用户定义变量。
6.2 设置用户定义变量
设置局部用户定义变量
通过等号=给环境变量赋值,值可以是数值或字符串。如果值包含空格,必须用双引号包裹住。
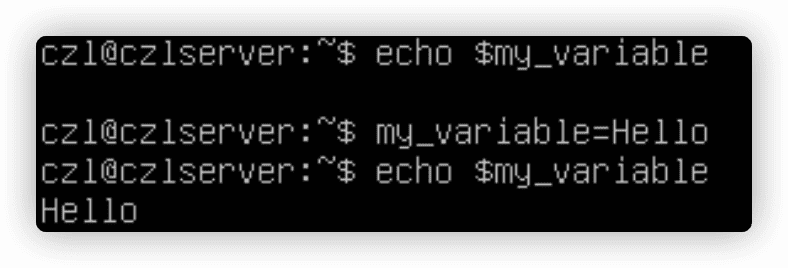
全局环境变量名用大写字母,自己创建的变量或是shell脚本,使用小写字母。变量名区分大小写。
设置全局变量
先创建一个局部环境变量,然后再将它导出到全局环境中。
export命令导出变量,将变量变成全局环境变量。
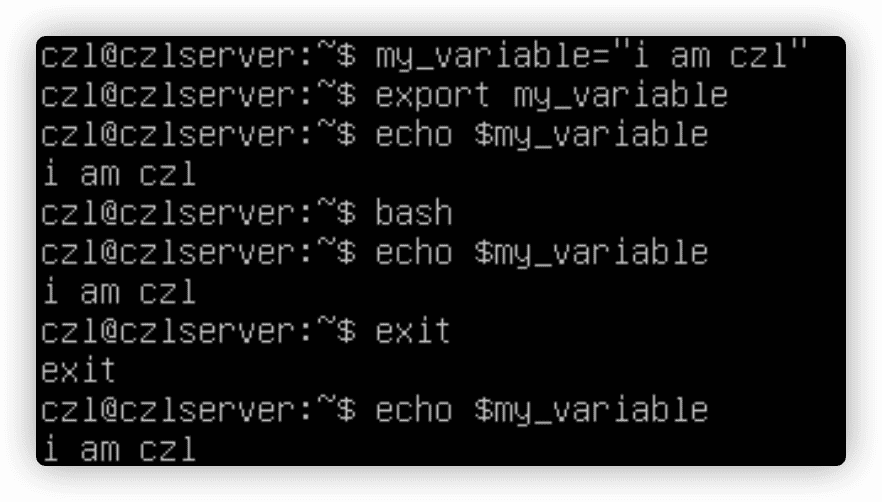
在子shell中修改全局环境变量不会影响到父shell中该变量的值。子shell无法使用export命令改变父shell中全局环境变量的值。
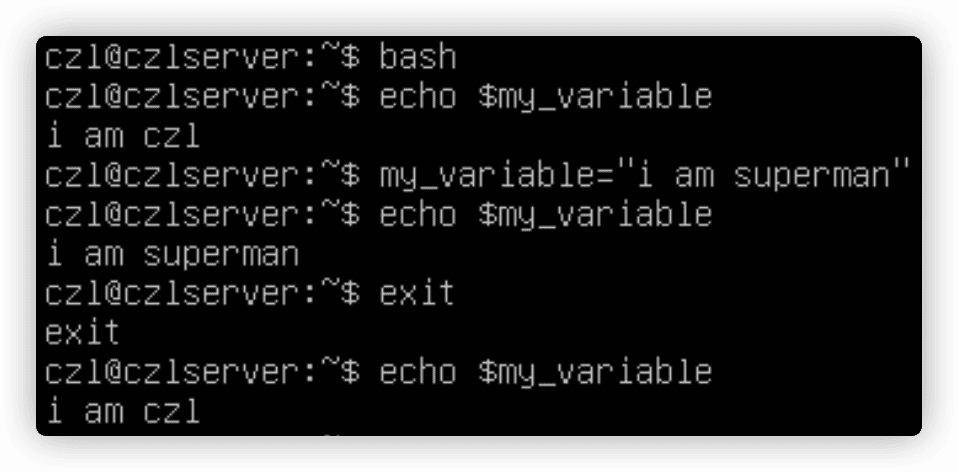
6.3 删除环境变量
unset xxx删除环境变量
如果要用到变量,使用$;如果要操作变量,不使用$;
当在子进程删除一个全局环境变量时,这只对子进程有效。该全局环境变量在父进程中依然可用。
6.4 默认的shell环境变量
bash shell支持的Bourne变量
| 变量 | 描述 |
|---|---|
| CDPATH | 冒号分隔的目录列表,作为cd命令的搜索路径 |
| HOME | 当前用户的主目录 |
| IFS | shell用来分隔文本字符串的一列字符 |
| 当前用户收件箱的文件名;bash shell会检查这个文件以查看是否有新邮件 | |
| MAILPATH | 冒号分隔的当前用户收件箱的文件名列表;bash会检查列表中的每个文件以查看是否有新邮件 |
| OPTARG | getopts命令处理的最后一个选项参数值 |
| OPTIND | getopts命令处理的最后一个选项参数的索引号 |
| PATH | 冒号分隔符的shell查找命令的目录列表 |
| PS1 | shell命令行界面的主提示符 |
| PS2 | shell命令行界面的次提示符 |
6.5 设置PATH环境变量
PATH环境变量定义了用于进行命令和程序查找的目录。

如果命令或者程序的位置没有包括在PATH变量中,那么如果不适用绝对路径的话,shell是没法找到的,解决办法是保证PATH环境变量包含了所有存放应用程序的目录。可以把新的搜索目录添加到现有的PATH环境变量中,无需从头定义。

对PATH变量的修改只能持续到退出或者重启系统。
6.6 定位系统环境变量
在登入Linux系统启动一个bash shell时,默认情况下bash会在几个文件中查找命令。这些文件叫做启动文件或环境文件。bash检查的启动文件取决于你启动bash shell的方式。启动bash shell有3种方式:
- 登录时作为默认登录shell
- 作为非登录的交互式shell
- 作为运行脚本的非交互shell
登录shell
当登录Linux时,bash shell会作为登录shell启动。登录shell会在5个不同的启动文件里读取命令:
/etc/profile$HOME/.bash_profile$HOME/.bashrc$HOME/.bash_login$HOME/.profile
1./etc/profile文件
/etc/profile文件是系统上默认的bash shell的主启动文件,系统上的每个用户登录时都会执行这个启动文件。
不同的Linux发行版在这个文件放了不同的命令,每个发行版的/etc/profile文件都有不同的设置和命令。
2.$HOME目录下的启动文件
剩下的启动文件都起着同一作用:提供一个用户专属的启动文件来定义该用户所用到的环境变量。大多数Linux发行版只用到一两个。
交互式shell进程
如果bash shell不是登录系统时启动的(比如是在命令行提示符下敲下bash时启动),那么启动的shell叫做交互式shell。交互式shell不会访问/etc/profile文件,只会检查用户HOME目录中的.bashrc文件。
.bashrc文件有两个作用:一是查看/etc目录下通用的bashrc文件,二是为用户提供一个定制自己的命令别名和私有脚本函数的地方。
非交互式shell
系统执行shell脚本时用的就是这种shell。
bash shell提供了BASH_ENV环境变量,当shell启动一个非交互式shell程序时,它会检查这个环境变量来查看要执行的启动文件。如果有指定的文件,shell会执行该文件里的命令,这通常包括shell脚本变量设置。
环境变量持久化
对全局环境变量来说(Linux系统中所有用户都需要使用的变量),可能更倾向于将新的或修改过的变量设置放在/etc/profile文件中,不过如果升级了所用的发行版,这个文件也会跟着更新,那么所定制过的变量设置就会不见了。最好是在/etc/profile.d目录中创建一个以.sh结尾的文件,把所有新的或修改过的全局环境变量设置放入这个文件中。
个人用户永久性bash shell变量是放在$HOEM/.bashrc文件。
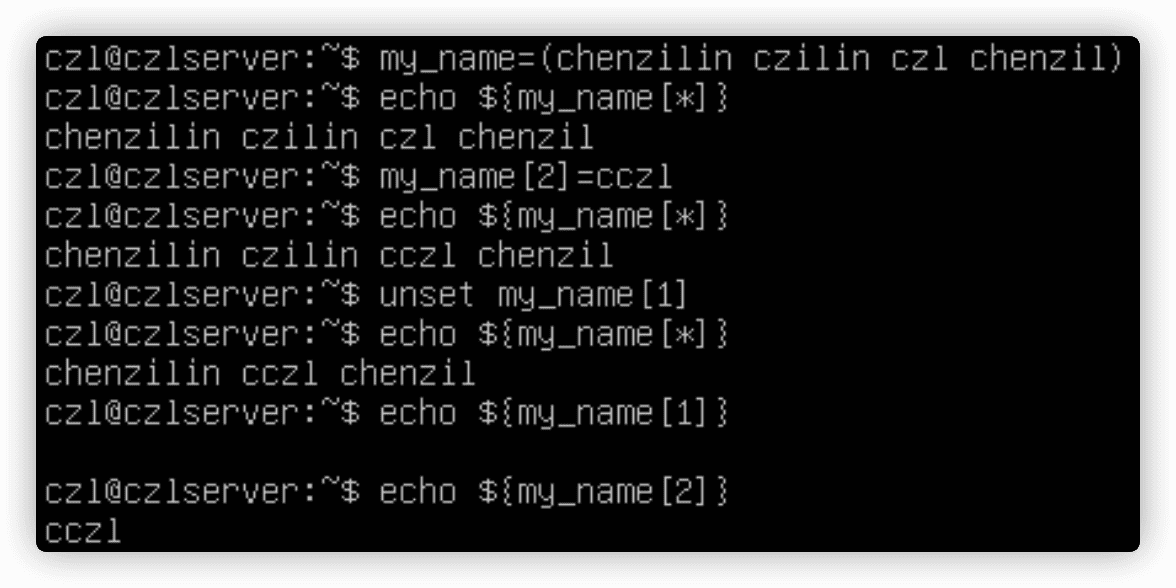
6.7 数组变量
环境变量可作为数组使用,数组能够存储多个值的变量,这些值可以单独引用,也可以作为整个数组来引用。
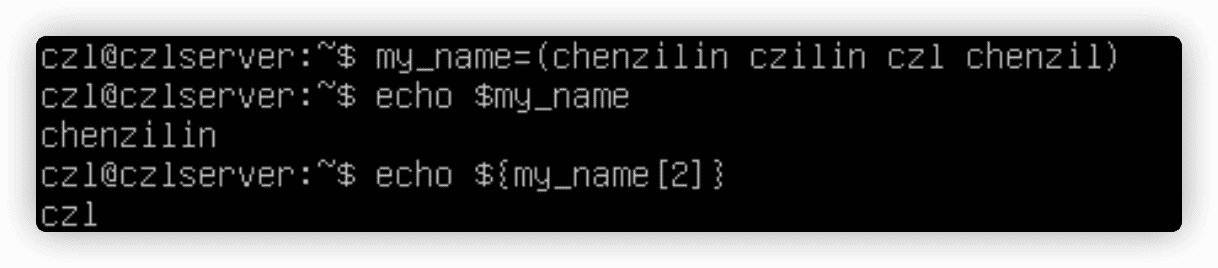
echo ${my_name[*]}显示整个数组变量;
第7章 理解Linux文件权限
Linux沿用了Unix文件权限的办法,允许用户和组根据每个文件和目录的安全性设置来访问文件。
7.1 Linux的安全性
Linux安全系统的核心是用户账户。用户对系统中各种对象的访问权限取决于他们登录系统时用的账户。
用户权限是通过创建用户时分配的用户ID(User ID,缩写为UID)来跟踪的。UID的数值,每个用户都有唯一的UID,但在登录系统时用的不是UID,而是登录名。登录名是用户用来登录系统的最长八字符的字符串,同时会关联一个对应的密码。
/etc/passwd文件
/etc/passwd文件将用户的登录名匹配到对应的UID值,它包含了一些与用户有关的信息。
root用户账户是Linux系统的管理员,固定分配给它的UID是0。
Linux系统会为各种各样的功能创建不同的用户账户,而这些账户并不是真的用户。这些账户叫做系统账户,是系统上运行的各种服务进程访问资源用的特殊账户。所有运行在后台的服务都需要用一个系统用户账户登录到Linux系统上。
在安全成为一个大问题之前,这些服务经常会用root账户登录。但如果有非授权的用户攻陷了这些服务中的一个,他立刻就能作为root用户进入系统。为了防止这种情况发生,现在运行在Linux服务器后台的几乎所有的服务都是用自己的账户登录。
Linux为系统账户预留了500以下的UID值。为普通用户创建账户时,大多数Linux系统会从500开始。
/etc/passwd文件的字段包含了如下信息:
- 用户登录名
- 用户密码
- 用户账户的UID(数字形式)
- 用户账户的组ID(GID)(数字形式)
- 用户账户的文本描述(称为备注字段)
- 用户HOME目录的位置
- 用户的默认shell
etc/passwd文件中的密码字段都被设置成了x,在早期的Linux上,etc/passwd文件里有加密后的用户密码,但鉴于很多程序都需要访问etc/passwd文件获取用户信息,这就成了一个安全隐患。现在,绝大多数Linux系统都将用户密码保存在另一个单独的文件中(/etc/shadow),只有特定的程序(比如登录程序)才能访问这个文件。
/etc/passwd是一个标准的文本文件。你可以用任何文本编辑器在etc/passwd文件里直接手动进行用户管理(比如添加、修改或删除用户)。但这样做极其危险。如果etc/passwd文件出现损坏,系统将无法读取它的内容了,这样会导致用户无法正常登录(即便是root用户)。
/etc/shadow文件
只有root用户才能访问/etc/shadow文件。/etc/shadow文件为系统上的每个用户账户都保存了一条记录。
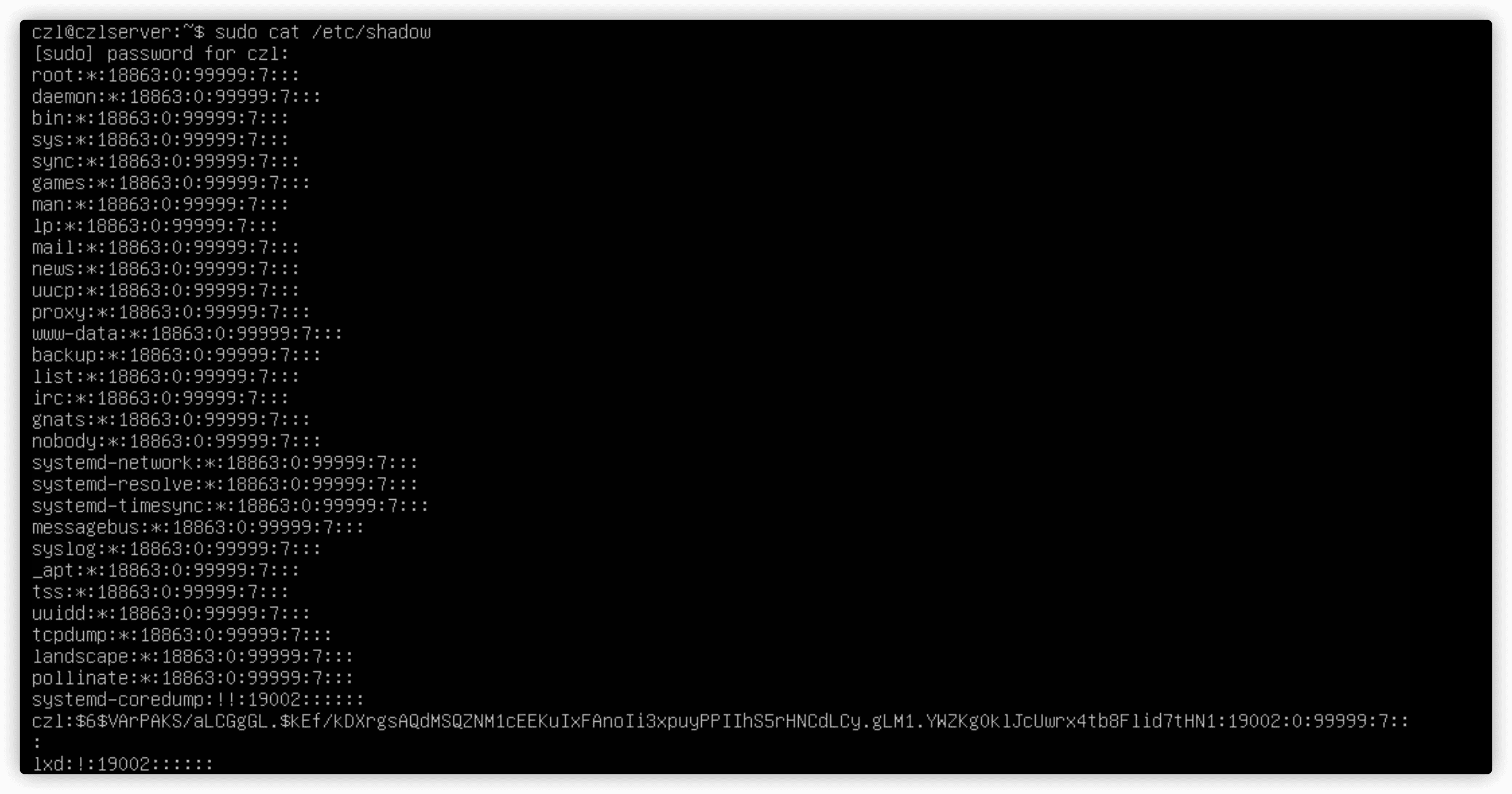
- 与
/etc/passwd文件中的登录名字段对应的登录名 - 加密后的密码
- 自上次修改密码后过去的天数密码(自1970年一月一号开始计算)
- 多少天后才能更改密码
- 多少天后必须更新密码
- 密码过期前提前多少天提醒用户更改密码
- 密码过期后多少天禁用用户账户
- 用户账户被禁用的日期(自1970年一月一号到当天的天数表示)
- 预留字段给将来使用
shadow可以控制用户多久更改一次密码,以及什么时候禁用该用户账户,如果密码未更新的话。
添加新用户
useradd命令创建新用户账户及设置用户HOME目录结构。useradd命令使用系统的默认值以及命令行参数来设置用户账户。系统默认值被设置在/etc/default/useradd文件中。
-D选项查看所用Linux系统中的这些默认值。
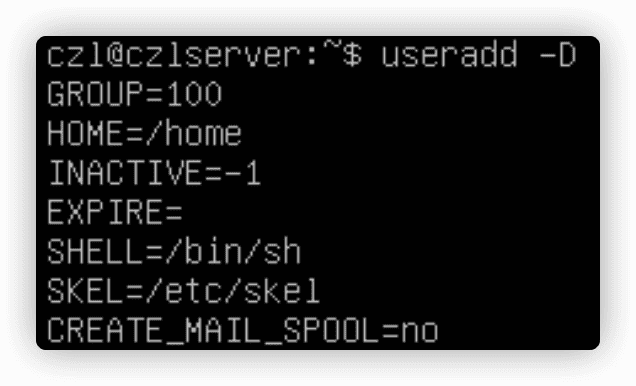
在创建新用户时,如果不指定具体的值,useradd命令会使用-D选项所显示的那些默认值。
- GID
- HOME目录
- 账户密码在过期后不会被禁用
- 账户未被设置过期日期
- 将sh shell作为默认shell
- 将
/etc/skel目录下的内容复制到用户的HOME目录下 - 不会为该用户账户在mail目录下创建一个用户接受邮件的文件
useradd -m 用户名使用默认配置创建用户。-m选项会是其创建HOME目录,默认不会创建。
| 参 数 | 描 述 |
|---|---|
| -c comment | 给新用户添加备注 |
| -d home_dir | 为主目录指定一个名字(如果不想用登录名作为主目录名的话) |
| -e expire_date | 用YYYY-MM-DD格式指定一个账户过期的日期 |
| -f inactive_days | 指定这个账户密码过期后多少天这个账户被禁用;0表示密码一过期就立即禁用,1表示禁用这个功能 |
| -g initial_group | 指定用户登录组的GID或组名 |
| -G group … | 指定用户除登录组之外所属的一个或多个附加组 |
| -k | 必须和-m一起使用,将/etc/skel目录的内容复制到用户的HOME目录 |
| -m | 创建用户的HOME目录 |
| -M | 不创建用户的HOME目录(当默认设置里要求创建时才使用这个选项) |
| -n | 创建一个与用户登录名同名的新组 |
| -r | 创建系统账户 |
| -p passwd | 为用户账户指定默认密码 |
| -s shell | 指定默认的登录shell |
| -u uid | 为账户指定唯一的UID |
| -b default_home | 更改默认的创建用户HOME目录的位置 |
| -e expiration_date | 更改默认的新账户的过期日期 |
| -f inactive | 更改默认的新用户从密码过期到账户被禁用的天数 |
| -g group | 更改默认的组名称或GID |
| -s shell | 更改默认的登录shell |
-D选项后面跟上一个指定的值来修改系统默认的新用户设置。
删除用户
userdel删除用户,不过它只删除/etc/passwd文件中的用户信息,而不会删除系统中属于该账户的任何文件。
-r选项删除用户的HOME目录以及邮件目录。
在删除用户的HOME目录之前一定要检查清除!
修改用户
| 命令 | 描述 |
|---|---|
usermod | 修改用户账户的字段,还可以指定主要组以及附加组的所属关系 |
passwd | 修改已有用户的密码 |
chpasswd | 从文件中读取登录名密码对,并更新密码 |
chage | 修改密码的过期日期 |
chfn | 修改用户账户的备注信息 |
chsh | 修改用户账户的默认登录shell |
1.usermod
能修改/etc/passwd文件中的大部分字段,只需用与想修改的字段对应的命令行参数就可以了。参数大部分跟useradd命令一样,除此之外,还有一些派的上用场的选项:
-l修改用户账户的登录名-L锁定账户,使用户无法登录-p修改账户的密码U解除锁定,使用户能够登录
2.passwd和chpasswd
passwd命令可以简便修改用户密码。
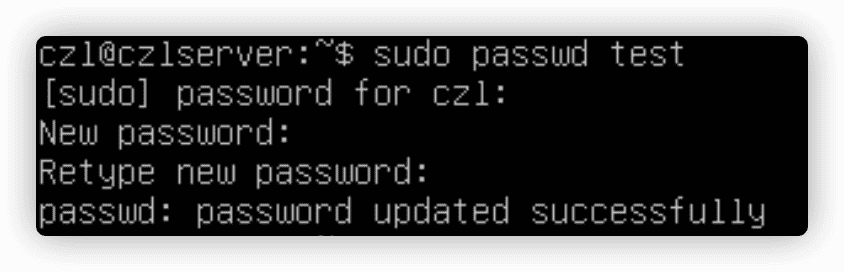
-e选项能强制用户下次登录时修改密码。
chpasswd命令可以为系统系统大量用户修改密码,它能从标准输入自动读取登录名和密码对(由冒号分割)列表,给密码加密,然后为用户账户设置。
例:chpasswd < users.txt。
3.chsh、chfn和chage
chsh、chfn和chage工具专门用来修改特定的账户信息。
chsh命令用来快速修改默认的用户登录shell。chsh -s /bin/csh test。
chfn命令 提供了在/etc/passwd文件的备注字段中存储信息的标准方法。
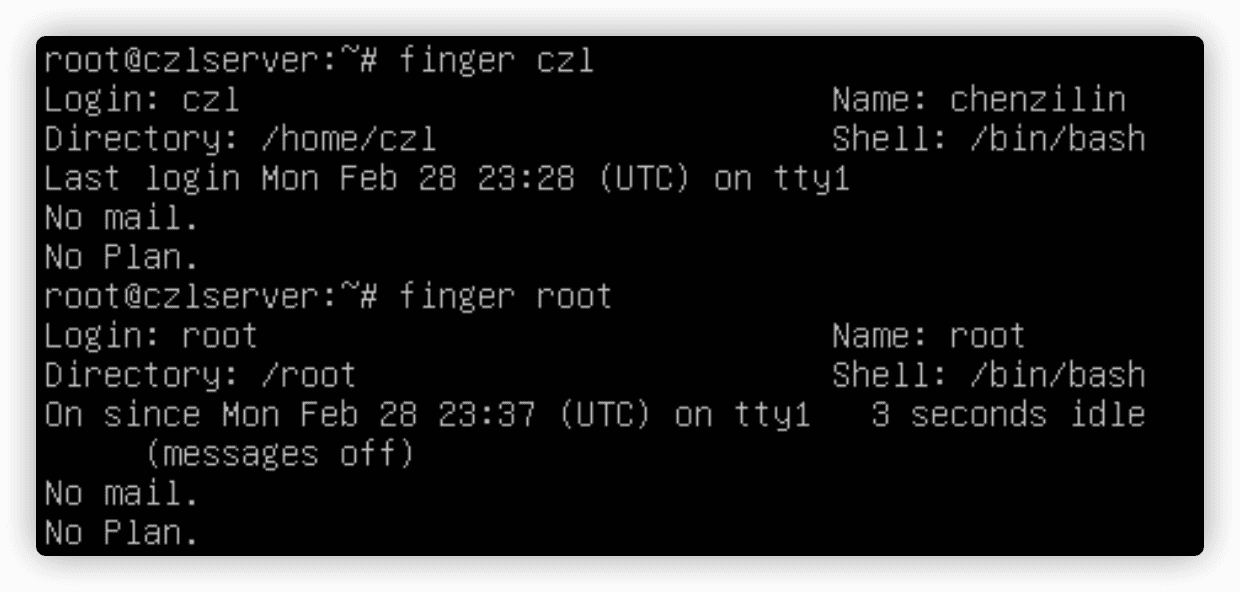
**finger**命令可以方便的查看Linux系统上的用户信息。
7.2 使用Linux组
组权限允许多个用户对系统中的对象(比如文件、目录或设备等)共享一组共用的权限。
/etc/group文件
/etc/group文件包含系统上用到的每个组的信息。
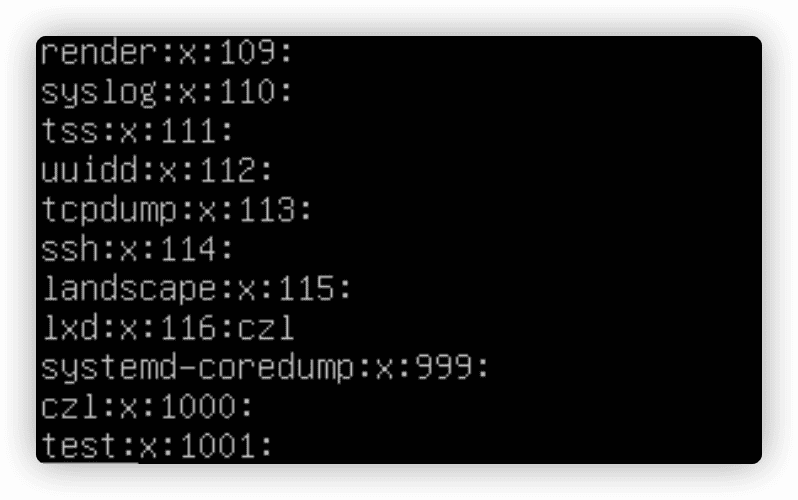
系统账户用的组通常会分配低于500的GID值。/etc/group有以下4个字段:
- 组名
- 组密码
- GID
- 属于该组的用户
组密码允许非组内成员通过它临时成为该组成员。
创建新组
groupadd xxx命令可在系统上创建新组。
可以使用usermod将用户移入某个组。usermod -G 组名 用户名。
为用户账户分配组如果使用
-g则会替换掉该账户的默认组,-G则将该组添加到用户的属组的列表里,不会影响默认组。
修改组
groupmod命令修改已有组的GID(-g)或组名(-n)。
7.3 理解文件权限
使用文件权限符
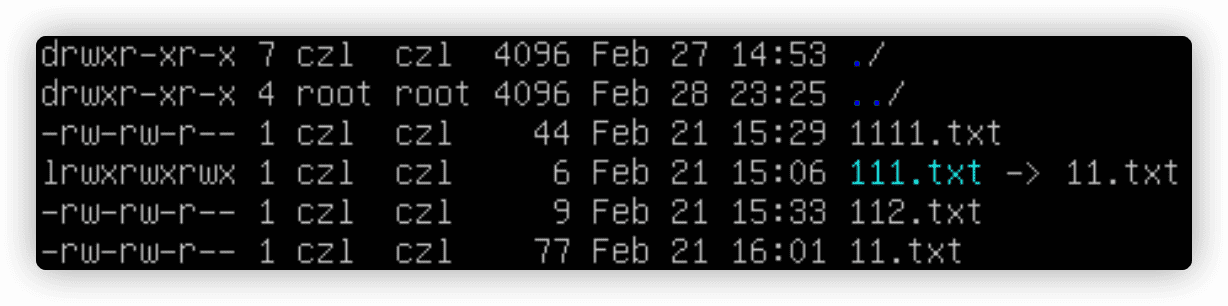
输出结果第一个字段是描述文件和目录权限的编码。第一个字符代表对象的类型:
-代表文件l代表链接d代表目录c代表字符型设备b代表块设备n代表网络设备
之后有3组三字符。每一组定义了3种权限:
r代表可读w代表可写x代表可执行
若没有某种权限,在该权限会出现-。这3组权限分别对应对象的3个安全级别:
- 对象的属主
- 对象的属组
- 系统其他用户
默认文件权限
umask命令用来设置创建文件和目录的默认权限。
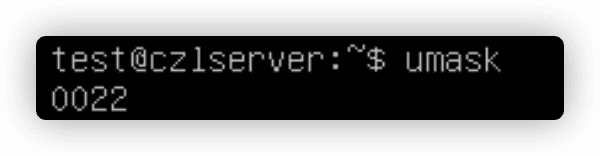
第一位代表一项特别的安全特性,叫做粘着位(sticky bit)。后面3位表示文件或目录对应的umask八进制值。
八进制模式的安全性设置先获取这3个rwx权限的值,然后转换成3位二进制,用一个八进制位来表示。
| 权限 | 二进制值 | 八进制值 | 描述 |
|---|---|---|---|
| --- | 000 | 0 | 没有任何权限 |
| --x | 001 | 1 | 只有执行权限 |
| -w- | 010 | 2 | 只有写入权限 |
| -wx | 011 | 3 | 写入和执行权限 |
| r-- | 100 | 4 | 读权限 |
| r-x | 101 | 5 | 读和执行权限 |
| rw- | 110 | 6 | 读和写入权限 |
| rwx | 111 | 7 | 全部权限 |
八进制模式先取得权限的八进制值,然后再把这三组安全级别(属主、属组和其他用户)的八进制值顺序列出。
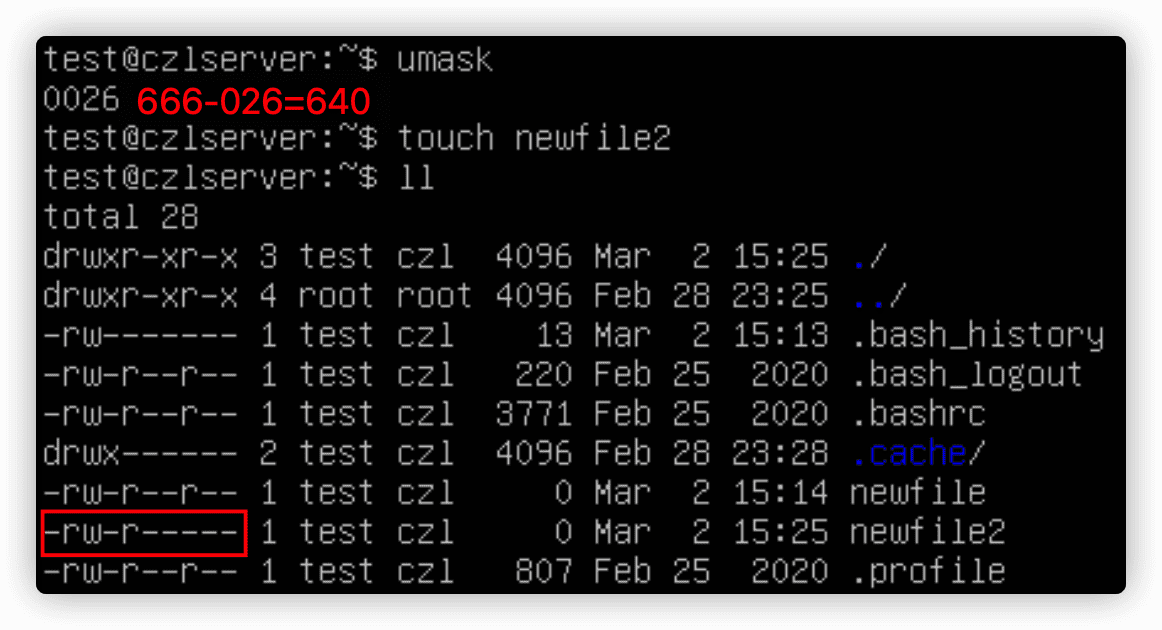
umask值只是一个掩码,它会屏蔽掉不想授予该安全级别的权限,要把umask值从对象的全权值中减掉。对文件来说,全权限的值是666(所有用户都有读和写的权限);而目录的全权限值是777(读写执行)。
7.4 改变安全性设置
改变权限
chmod命令用来改变文件和目录的安全性设置。chmod options mode file。
mode参数使用八进制模式或符号模式进行安全性设置。
符号模式[ugoa...][[+-=][rwxXstugo...]]。
第一组字符定义权限作用的对象:
u代表用户g代表组o代表其他a代表上述所有
后面跟着的符号表示:
+增加权限-移除权限=将权限设置成后面的值
第三个符号代表作用到设置上的权限:
x如果对象是目录或者它已有执行权限,赋予执行能力s运行时重新设置UID或GIDt保留文件或目录u设置属主权限g设置属组权限o设置其他用户权限
-R选项可以让权限的改变递归地作用到文件和子目录。
改变所属关系
chown命令改变文件的属主;chown options owner[.group] file。
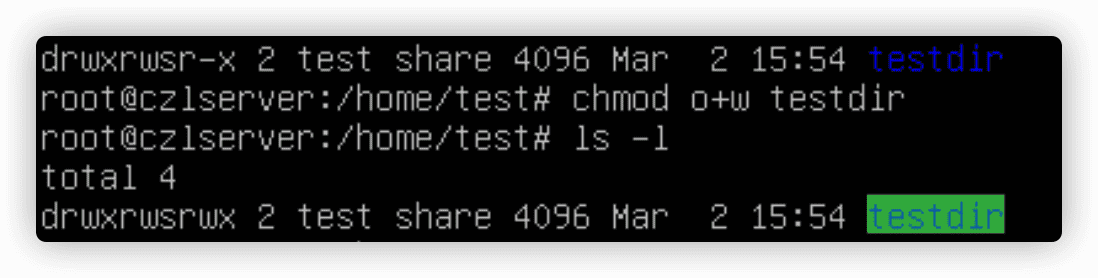
chgrp命令改变文件的默认属组。
只有root用户才能改变文件的属主。任何属主都可以改变文件的属组,但前提是属主必须是原属组和目标属组的成员。
7.5 共享文件
Linux为每个文件和目录存储了3个额外的信息位。
- 设置用户ID(SUID):当文件被用户使用时,程序会以文件属主的权限运行。
- 设置组ID(SGID):对文件来说,程序会以文件属组的权限运行;而目录中创建的新文件会以目录的默认属组作为默认属组。
- 粘着位:进程结束后文件还驻留在内存中。

第8章 管理文件系统
8.1 探索Linux文件系统
Linux支持多种类型的文件系统管理文件和目录。每种文件系统都在存储设备上实现了虚拟目录结构,仅特性略有不同。
基本的Linux文件系统
1.ext文件系统
Linux操作系统中引入最早的文件系统叫做扩展文件系统(extended filesystem,简称ext)。它为Linux提供一个基本的类Unix文件系统:使用虚拟目录来操作硬件设备,在物理设备上按定长的块来存储数据。
ext文件系统采用索引节点的系统存放虚拟目录中所存储文件的信息。索引结点系统在每个物理设备中创建一个单独的表(索引结点表)来存储这些文件的信息。存储在虚拟目录中的每一个文件在索引结点表中都有一个条目。ext文件系统名称中extended部分来自其跟踪的每个文件的额外数据,包括:
- 文件名
- 文件大小
- 文件的属主
- 文件的属组
- 文件的访问权限
- 指向存有文件数据的每个硬盘块的指针
Linux通过唯一的数值来引用索引结点表中的每个索引结点,这个值在创建文件时由文件系统分配。文件系统通过索引结点而不是文件全名及路径来标识文件。
2.ext2文件系统
最早的ext文件系统有不少的限制,比如文件大小不得超过2GB。ext2文件系统是ext文件系统基本功能的一个扩展,但保持了同样的结构。ext2的索引节点表为文件添加了创建时间值、修改时间值和最后访问时间值来帮助系统管理员追踪文件的访问情况。ext2还运行最大文件大小增加到32TB,以容纳数据库服务器中常见的大文件。
保存文件时,ext的问题是存储数据用的块容易分散到整个设备中(碎片化),而ext2通过按组分配磁盘块来减轻碎片化。通过将数据块分组,文件系统在读取文件不需要为了数据块查找整个物理设备,加快查找和存储性能。
问题:ext文件系统的索引结点表虽然支持文件系统保存有关文件的更多信息,但会对系统造成致命的问题。文件系统每次存储或更新文件,它都要用新信息来更新索引节点表。问题在于这种操作并非总是一气呵成的。如果计算机在存储文件和更新索引节点表之间发生点什么,这两者的内容就无法同步了。
日志文件系统
日志文件系统用来解决上述问题,它为Linux系统增加了一层安全性。它不再使用之前先将数据直接写入存储设备而更新索引节点表,而是将文件的更改写入到临时文件(称作日志,journal)中。在数据成功写到存储设备和索引节点表之后,再删除对应的日志条目。
如果系统的数据被写入存储设备之前崩溃或断掉了,日志文件系统下次会读取日志文件并处理上次留下的未写入的数据。
Linux中有3种广泛使用的日志方法:
| 方法 | 描述 |
|---|---|
| 数据模式 | 索引节点和文件都会被写入日志,丢失数据风险低,但性能差。 |
| 有序模式 | 只有索引节点数据会被写入日志,但只有数据成功写入后才删除;在性能和安全性之间取得了良好的折中。 |
| 回写模式 | 只写入索引节点数据到日志,但不控制文件数据何时写入;丢失数据风险高,但仍比不用日志好。 |
1.ext3文件系统
2001年,ext3文件系统被引入Linux内核中。它采用和ext2文件系统相同的索引节点表结构,但给每个存储设备增加一个日志文件,将准备写入存储设备的数据先记入日志。
默认情况下,ext3文件系统用有序模式的日志功能。
问题:ext3文件系统无法恢复误删的文件;没有任何内建的数据压缩功能;不支持加密文件。
2.ext4文件系统
ext4文件系统在2008年受到Linux内核官方支持。除了支持数据压缩和加密,ext4系统还支持一个称作区段(extent)的特性。区段在存储设备上按块分配空间,但在索引节点表中只保存起始块的位置。由于无需列出所有用来存储文件中数据的数据块,它可以在索引节点表中节省一些空间。
ext4还引入了块预分配技术(block preallocation)。可以为即将变大的文件预留空间。
3.Reiser文件系统
ReiserFS文件系统是2001年由Hans Reiser编写的,它支持回写日志模式,因此也称为Linux上最快的日志文件系统之一。
ReiserFS有两个有趣的特性:在线调整已有文件系统的大小;尾部压缩(tailpacking)的技术。
4.JFS文件系统
JFS(Journaled File System,日志化文件系统)是IBM在1990年为其Unix衍生版AIX开发的。JSF文件系统采用有序日志方法。采用基于区段的文件分配。
5.XFS文件系统
XFS日志文件系统是最初用于商业Unix系统,采用回写模式的日志。
写时复制文件系统
采用日志式技术,你就必须在安全性和性能之间做出选择。
日志式的另一种选择是一种叫作写时复制(copy-on-write,COW)的技术。COW利用快照兼顾了安全性和性能。修改数据时,会使用克隆或可写快照。修改过的数据并不会直接覆盖当前数据,而是被放入文件系统的另一个位置上。即便是数据修改已经完成,之前的旧数据也不会被重写。
1.ZFS文件系统
ZFS由Sun公司于2005年研发,用于OpenSolaris操作系统,在2012年投入Linux产品的使用。
ZFS是一个稳定的文件系统,与Resier4、Btrfs和ext4势均力敌。
2.Btrf文件系统
Btrfs被称为B树文件系统。它是由Oracle公司于2007年开始研发的。Btrfs在Reiser4的诸多特性的基础上改进了可靠性。
8.2 操作文件系统
创建分区
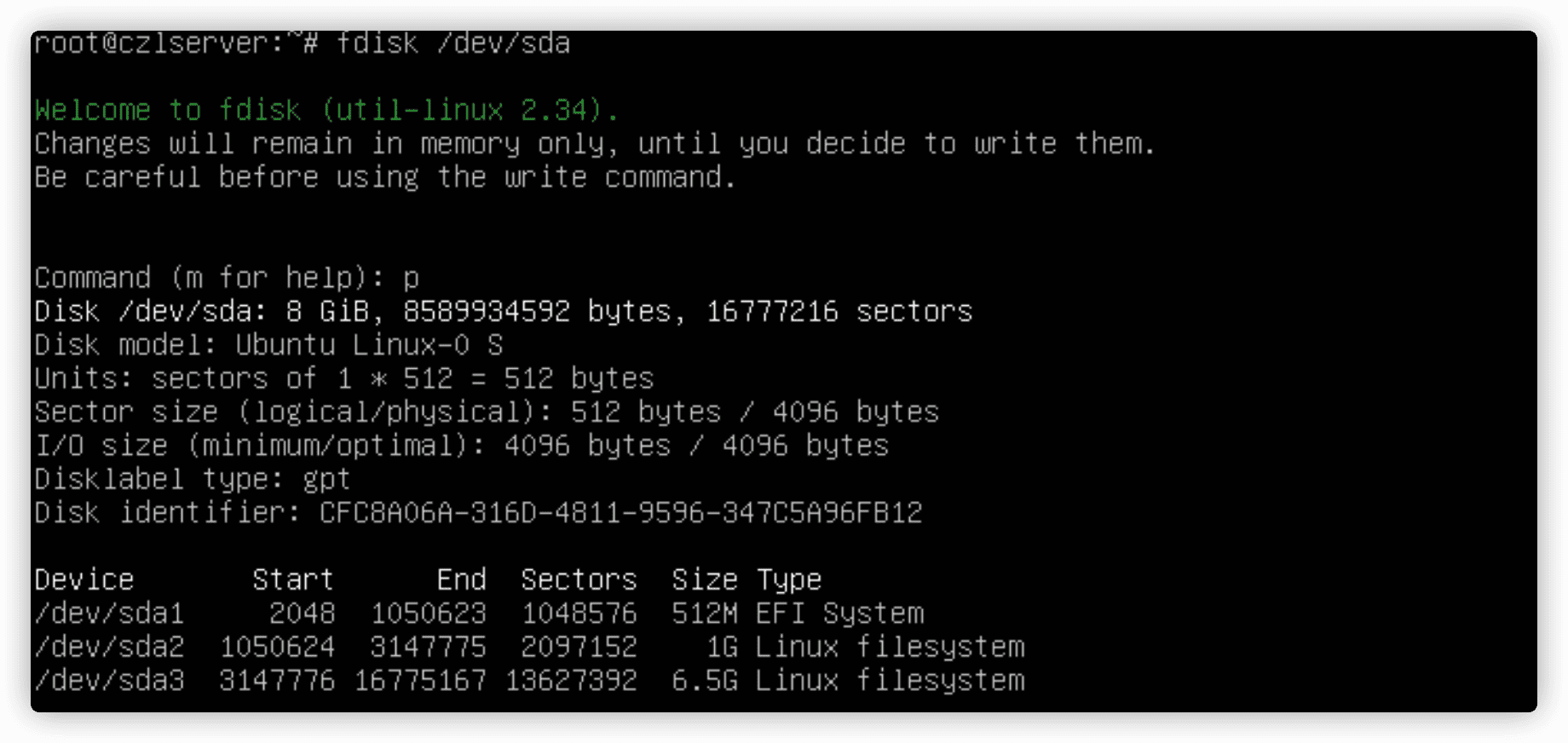
一开始,你必须在存储设备上创建分区来容纳文件系统。分区可以是整个硬盘,也可以是部分硬盘,以容纳虚拟目录的一部分
fdisk工具用来帮助管理安装在系统上的任何存储设备上的分区。fdisk 设备名。
| 命令 | 描述 |
|---|---|
| d | 删除分区 |
| l | 显示可用的分区类型 |
| m | 显示命令选项 |
| n | 创建一个新分区 |
| p | 显示当前分区表 |
| t | 修改分区的系统ID |
| q | 退出,不保存更改 |
| w | 将分区表写入磁盘 |
创建文件系统
在将数据存储到分区之前,必须用某种文件系统对其进行格式化,这样Linux才能使用它。每种文件系统类型都用自己的命令行程序来格式化分区。
| 工具 | 用途 |
|---|---|
| mkefs | 创建一个ext文件系统 |
| mke2fs | 创建一个ext2文件系统 |
| mkfs.ext3 | 创建一个ext3文件系统 |
| mkfs.ext4 | 创建一个ext4文件系统 |
| mkreiserfs | 创建一个ReiserFS文件系统 |
| jfs_mkfs | 创建一个JFS文件系统 |
| mkfs.xfs | 创建一个XFS文件系统 |
| mkfs.zfs | 创建一个ZFS文件系统 |
| mkfs.btrfs | 创建一个Btrfs文件系统 |
为分区创建了文件系统系统之后,下一步是将它挂载到虚拟目录下的某个挂载点,这样就可以将数据存储在新文件系统中了。
文件系统的检查与修复
fask目录能够检查和修复大部分类型的Linux文件系统。fsck options filesystem。
8.3 逻辑卷管理
在存储设备分区上直接创建文件系统的一个限制因素是,如果硬盘空间用完了,你无法轻易地改变文件系统的大小。将另外一个硬盘上的分区加入已有文件系统,动态地添加存储空间,Linux逻辑卷管理器(logical volume manager,LVM)软件包可以用来做这个。
逻辑卷管理布局
在逻辑卷管理的世界里,硬盘分区称作物理卷(physical volume,PV)。每个物理卷都会映射到硬盘上特定的物理分区。多个物理卷集合在一起可以形成一个卷组(volume group,VG)。逻辑卷管理系统将多个卷组视为一个物理硬盘,卷组可能是由分布在多个物理硬盘上的多个物理分区组成的。卷组提供了一个创建逻辑分区的平台,而这些逻辑分区则包含了文件系统。
整个结构中的最后一层是逻辑卷(logical volume,LV)。逻辑卷为Linux提供了创建文件系统的分区环境。Linux将逻辑卷视为物理分区。
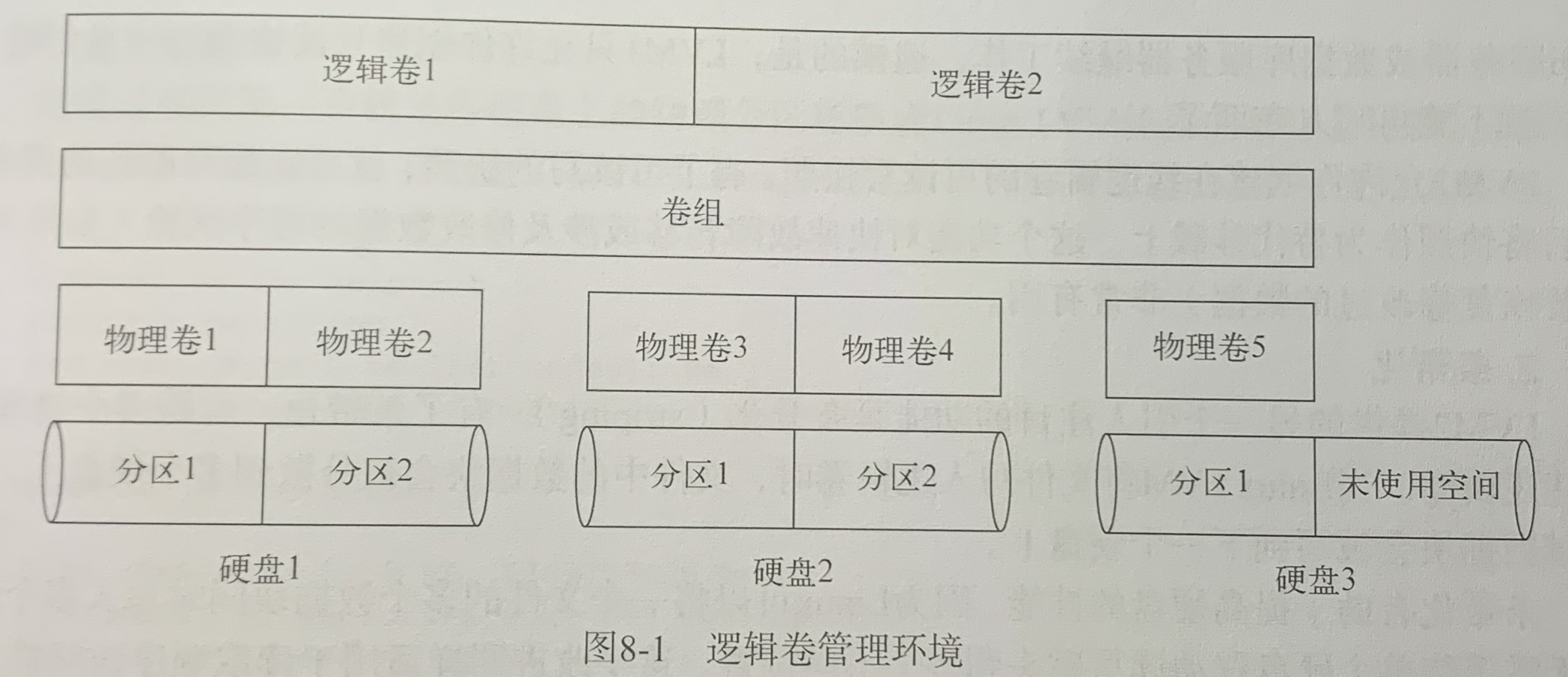
Linux中的LVM
Linux LVM有两个可用的版本:
- LVM1:与1998年发布,只能用于Linux内核2.4。仅提供了基本的逻辑卷管理功能。
- LVM2:可用于Linux内核2.6。在标准的LVM1功能外提供了额外的功能。
1.快照
在逻辑卷在线的状态下将其复制到另一个设备,这个功能叫做快照。
2.条带化
条带化,可跨多个物理设备创建逻辑卷。有助于提高硬盘的性能。
3.镜像
镜像是一个实时更新的逻辑卷的完整副本。
第9章 安装软件程序
9.1 包管理基础
PMS(package management system,包管理器)利用一个数据库来记录各种相关内容:Linux系统上已经安装了什么软件包;每个包安装了什么文件;每个已安装软件包的版本。
软件包存储在服务器(仓库(respository))上,可以用PMS来搜索并安装或更新新的软件包。软件包通常会依赖其他的包,PMS会检测这些依赖关系,并自动安装所有额外的软件包。
Linux主要使用PMS基础工具是dpkg(基于Debian)和rpm(基于Red Hat)。
9.2 基于Debian的系统
dpkg命令是基于Debian系PMS工具的核心。包含在这个PMS中的其他工具有:
apt-getapt-cacheaptitude
最常用的命令行工具是aptitude,aptitude工具本质上是apt工具和dpkg的前端。dpkg是软件包管理系统工具,而aptitude则是完整的软件包管理系统。
用aptitude管理软件包
aptitude命令进入全屏模式。aptitude show 包名可以显示某个包的详细信息。
dpkg -L package_name可以显示所有跟某个特定软件包相关的所有文件的列表。
用aptitude安装软件包
aptitude search package_name查找某个包名。
aptitude install package_name安装包。
用aptitude更新软件
aptitude safe-upgrade将所有已安装的包更新到最新版本。
用aptitude卸载软件
要想只删除软件包而不删除数据和配置文件,可以使用aptitude remove。要删除软件包和相关的数据和配置文件,使用purge选项。
aptitude仓库
aptitude默认的软件仓库位置是存储在/etc/apt/sources.list中。如果你需要为你的PMS添加一些额外的软件仓库,就在这个文件中设置。
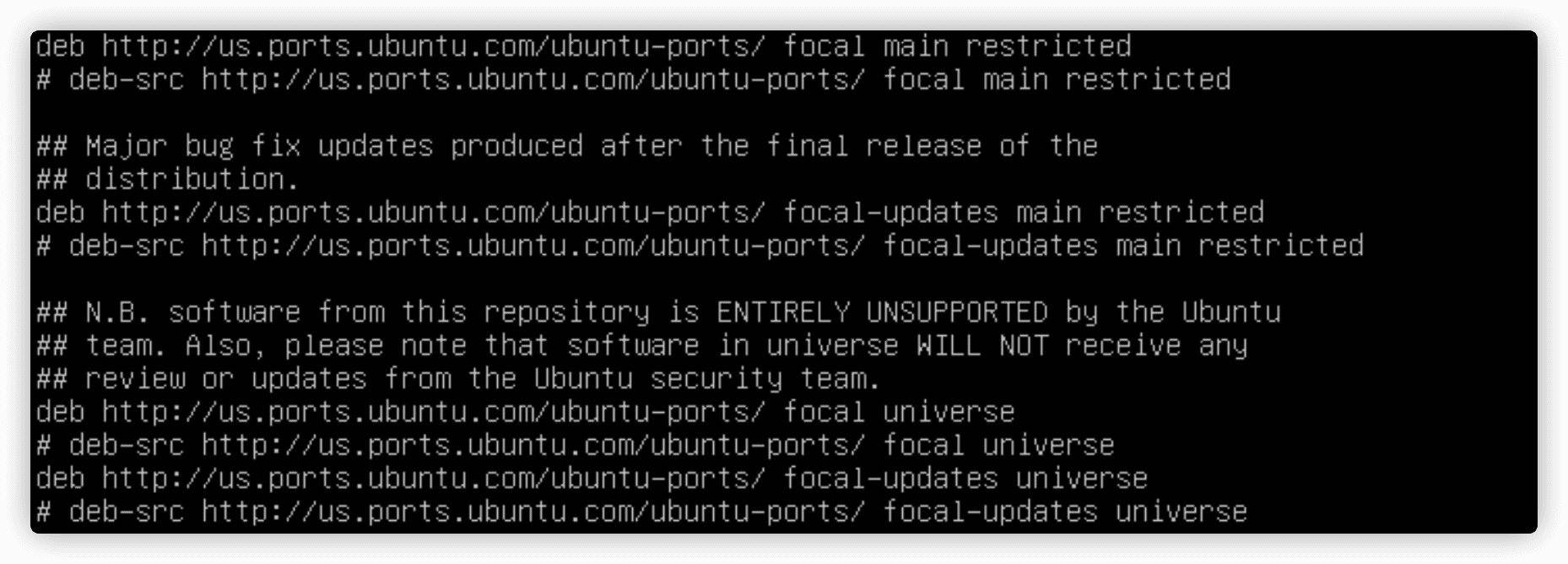
使用下面的结构来指定仓库源。deb or (deb-src) address distribution_name package_type_list。
- deb或deb-srd表明软件包的类型。deb表示这是一个已编译程序源,deb-src表示这是一个源代码的源。
- address表示软件仓库的Web地址。
- distribution_name是这个特定软件仓库的发行版版本的名称。
- package_type_list表明仓库里面有什么类型的包。
9.3 基于Red Hat 的系统
yumurpmzypper
删除软件包可以选择
- 只删除软件包而保留配置文件和数据文件
- 全部删除
处理损坏的包依赖关系
有时候在安装多个软件包时,某个包的软件依赖关系会被另一个包的安装覆盖掉。
yum repolist显示当前使用的仓库。
9.4 从源码安装
去包的官方站点下载包,文件名是xxx.tar.gz,之后进行解包,使用tar命令进行解压,之后进入目录,阅读README文件,make命令用来构建各种二进制文件,编译源码,make步骤结束后,可运行程序就生成了,但从那个目录下运行程序不是很方便,如果想安装到系统,那就必须以root身份运行make install。
第10章 使用编辑器
10.1 vim编辑器
vi实际上引用的是vim。
vim编辑器有两种操作模式:
- 普通模式(也称命令行模式)(默认)
- 插入模式
命令行模式
移动光标
h:左移l:右移j:下移k:上移
快速移动
PageDown(Ctrl+F):下翻一页PageUp(Ctrl+B):上翻一页G:移动到缓冲区的最后一行num G:移动到缓冲区的第num行gg:移动到第一行
退出
q:如果未修改缓冲区数据,退出q!:取消所有对缓冲区数据的修改并退出w filename:将文件保存到另一个文件中wq:将缓冲区数据保存到文件中并退出
编辑数据
x:删除当前光标所在位置的字符dd:删除当前光标所在行dw:删除当前光标所在位置的单词d$:删除当前光标所在位置至行尾的内容J:删除当前光标所在行行尾的换行符u:撤销前一编辑命令a:在当前光标后追加数据A:在当前光标所在行行尾追加数据r char:用char替换当前光标所在位置的单个字符R text:用text覆盖当前光标所在位置的数据,直到按下ESC
复制和粘贴
y:复制文本,yw复制一个单词,y$复制到行尾p:粘贴
可视模式
v:进入可视模式
查找和替换
/:查找n:查找下一个:s/old/new/g::一行命令替换所有old:n,ms/old/new/g::替换行号n和m之间的所有old:%s/old/new/g::替换整个文件中的所有old:%s/old/new/gc::替换整个文件中的所有old,但在每次出现时提示
10.2 nano编辑器
nano是一款简单易用的控制台模式文本编辑器。
脱字符^表示Ctrl键。
10.3 emacs编辑器
emacs默认选装,一般需要自行安装。
10.4 KDE系编辑器
KDE桌面官方支持的两款文本编辑器:
- KWrite
- Kate
10.5 GNOME编辑器
GNOME或Unity桌面环境自带的图形化文本编辑器
- gedit
第二部分 shell脚本编程基础
第11章 构建基本脚本
11.1 使用多个命令
使用;对命令进行分隔 date;who。
11.2 创建shell脚本文件
创建shell脚本文件,必须在文件的第一行指定要使用的shell。格式为:#!/bin/bash。
bash shell通过$PATH环境变量来查找命令,如果不再该环境变量下,有两种做法:
- 将shell脚本文件所处的目录添加到PATH环境变量中。
- 在提示符中用绝对或相对文件路径来引用shell脚本文件
shell脚本文件必须具备有可运行的权限。
11.3 显示消息
echo命令打印文本。
11.4 使用变量
环境变量
$xx或${xx}访问环境变量。
用户变量
用户变量由字母、数字或下划线组成的文本字符串,长度不超过20个,区分大小写,赋值时,在变量、等号和值之间不能出现空格。
命令替换
将命令输出赋给变量
- 反引号字符(`)
- **
$()**格式
例:testing=`date`
11.5 重定向输入和输出
输出重定向
command > outputfile
例:date > test5将date命令输出的值输出到test5文件
如果之前输出的文件存在,重定向操作符会用新的文件覆盖旧的文件。
使用>>来追加数据,例:who >> test5。
输入重定向
输入重定向将文件的内容重定向到命令。
command < inputfile
一个简单的记忆方法:命令总是在左侧,而重定向符号“指向”数据流动的方向。
例:wc < test5。
wc命令对数据中的文本进行计数,默认会输出3个值:
- 文本的行数
- 文本的词数
- 文本的字节数
内联输入重定向:command << marker。
例:wc << EOF test string 1 test string 2 test string 3 EOF
11.6 管道
将一个命令的输出作为另一个命令的输入。
command1 | command2,
Linux系统实际上会同时运行这两个命令,在系统内部将它们连接起来,在第一个命令产生输出的同时,输出会立即送给第二个命令。
11.7 执行数学运算
expr命令
expr能识别少数的数字和字符串操作,例:expr 1 + 5、expr 2 \* 10。
使用方括号
**$[]**将数学运算结果赋值给变量。
var1=$[1 + 5]
echo $var1 # 6
var2=$[$var1 * 2]
echo $var2 # 12
bash shell数学运算符只支持整数运算
浮点解决方案
使用bash的内建计算器,bc。
parallels:~/Desktop/demo$ bc
bc 1.07.1
Copyright 1991-1994, 1997, 1998, 2000, 2004, 2006, 2008, 2012-2017 Free Software Foundation, Inc.
This is free software with ABSOLUTELY NO WARRANTY.
For details type `warranty'.
scale=2 # 使用scale进行浮点运算,默认=0
1 / 0.3
3.33
quit
在脚本中使用bc
#!/bin/bash
var1=20
var2=$(echo "scale=2; $var1 / 3" | bc)
echo $var2 # 6.66
使用输入重定向
parallels:~/Desktop/demo$ variable=$(bc << EOF
scale=2
1 / 0.3
EOF
)
# variable=3.33
11.8 退出脚本
shell中运行的每个命令都使用退出状态码(exit status)告诉shell它已经运行完毕。退出状态码是一个0~255的整数值,在命令结束运行时由命令传给shell。
查看退出状态码
$?变量保存上个已执行命令的退出状态码。
成功结束的命令的状态码是0,结束时有错误的命令状态码是127。
Linux退出状态码
| 状态码 | 描述 |
|---|---|
| 0 | 命令成功结束 |
| 1 | 一般性未知错误 |
| 2 | 不适合的shell命令 |
| 126 | 命令不可执行 |
| 127 | 没找到命令 |
| 128 | 无效的退出参数 |
| 128+x | 与Linux信号x相关的严重错误 |
| 130 | 通过Ctrl+C终止的命令 |
| 255 | 正常范围之外的退出状态码 |
exit命令
exit可以定义自己的退出状态码。
第12章 使用结构化命令
12.1 if-then语句
格式:
if command then commands fi
bash shell的if语句会执行if后面的命令,如果该命令的退出状态码是0,则位于then部分的命令就会执行,如果该命令的退出状态码是其他值,then部分的命令就不会被执行。
12.2 if-then-else语句
if command then commands else commands fi
12.3 嵌套if
if command1 then commands elif command2 then commands else commands fi
在
elif语句中,紧跟其后的else语句属于elif代码块,它们不属于之前if-then代码块。
12.4 test命令
test命令如果列出的条件成立,就会返回退出状态码0。
test condition
bash shell提供了另一种条件测试方法,无须在if-then语句中声明test命令
方括号之间必须加空格,否则会报错。test命令可以判断三类条件:
- 数值比较
- 字符串比较
- 文件比较
if [ condition ]
then
commands
fi
数值比较
| 比较 | 描述 |
|---|---|
| n1 -eq n2 | 相等== |
| n1 -ge n2 | 大于或等于>= |
| n1 -gt n2 | 大于> |
| n1 -le n2 | 小于或等于<= |
| n1 -lt n2 | 小于< |
| n1 -ne n2 | 不相等!= |
在bash shell中不能比较浮点数
字符串比较
| 比较 | 描述 |
|---|---|
| str1 = str2 | 相同 |
| str1 != str2 | 不相同 |
| str1 < str2 | 小于 |
| str1 > str2 | 大于 |
| -n str1 | 检查st1的长度是否非0 |
| -z str1 | str1的长度是否为0 |
文件比较
| 比较 | 描述 |
|---|---|
| -d file | 检查file是否存在并是一个目录 |
| -e file | 检查file是否存在 |
| -f file | 检查file是否存在并是一个文件 |
| -r file | 检查file是否存在并可读 |
| -s file | 检查file是否存在并非空 |
| -w file | 检查file是否存在并可写 |
| -x file | 检查file是否存在并执行 |
| -O file | 检查file是否存在并属当前用户所有 |
| -G file | 检查file是否存在并且默认组与当前用户相同 |
| file1 -nt file2 | 检查file1是否比file2新 |
| file2 -ot file2 | 检查file1是否比file2旧 |
12.5 复合条件测试
[ condition1 ] && [ condition2 ][ condition1 ] || [ condition2 ]
12.6 if-then的高级特性
使用双括号
双括号用于数学表达式,(( expression ))
expression可以是任意的数学赋值或比较表达式
| 符号 | 描述 |
|---|---|
| val++ | 后增 |
| val-- | 后减 |
| ++val | 先增 |
| --val | 先减 |
| ! | 逻辑求反 |
| ~ | 位求反 |
| ** | 幂运算 |
| << | 左位移 |
| >> | 右位移 |
| & | 位布尔和 |
| | | 位布尔或 |
| && | 逻辑和 |
| || | 逻辑或 |
12.7 case命令
case variable in pattern1 | pattern2) commands1;; pattern3) commands2;; *) default commands;; esac
# demo
#!/bin/bash
case $USER in
par | ppp)
echo 'pppp';;
parallels)
echo weclome $USER;;
*)
echo 'hhh';;
esac
第13章 更多的结构化命令
13.1 for命令
for var in list do commands done
#!/bin/bash
# basic for command
for test in Alabama Alaska Arizona Arkansas California Colorado
do
echo The next state is $test
done
读取复杂值
#!/bin/bash
# an example of how to properly define values
for test in Nevada "New Hampshire" "New Mexico" "New York"
do
echo "Now going to $test"
done
从命令读取值
#!/bin/bash
# reading values from a file
file="states"
for state in $(cat $file)
do
echo "Visit beautiful $state"
done
更改字段分隔符
环境变量IFS,叫做内部字段分隔符,IFS定义bash shell用作字段分隔符的一系列字符
默认情况下,bash shell会将下列字符当作字段分隔符:
- 空格
- 制表符
- 换行符
IFS=$\n:;这个赋值会将换行符、分号、冒号作为字段分隔符。
通配符读取目录
#!/bin/bash
# iterate through all the files in a directory
for file in /home/rich/test/*
do
if [ -d "$file" ]
then
echo "$file is a directory"
elif [ -f "$file" ]
then
echo "$file is a file"
fi
done
13.2 C语言风格的for命令
for (( variable assignment ; condition ; iteration process ))
#!/bin/bash
for (( i = 1; i <= 10; i++ ))
do
echo "The next number is $i"
done
#!/bin/bash
# multiple variables
for (( a=1, b=10; a <= 10; a++, b-- ))
do
echo "$a - $b"
done
13.3 while命令
while test command do other commands done
#!/bin/bash
var1=10
while [ $var1 -gt 0 ]
do
echo $var1
var1=$[ $var1 - 1 ]
done
13.4 until命令
until命令和while命令的工作方式完全相反,它要求返回非零退出状态码。
until test commands do other commands done
#!/bin/bash
# using the until command
var1=100
until [ $var1 -eq 0 ]
do
echo $var1
var1=$[ $var1 - 25 ]
done
13.5 嵌套循环
#!/bin/bash
# nesting for loops
for (( a = 1; a <= 3; a++ ))
do
echo "Starting loop $a:"
for (( b = 1; b <= 3; b++ ))
do
echo " Inside loop: $b"
done
done
13.6 循环处理文件数据
#!/bin/bash
# 保存原先的IFS,如果恢复可以使用IFS=$IFS.OLD
IFS.OLD=$IFS
IFS=$'\n'
for entry in $(cat /etc/passwd)
do
echo "Valus in $entry -"
IFS=:
for value in $entry
do
echo " $value"
done
done
13.7 控制循环
控制循环内部的两个命令
break退出循环continue中止某次循环
break命令
break n要跳出的循环层级,默认n=1
#!/bin/bash
# breaking out of a for loop
for var1 in 1 2 3 4 5 6 7 8 9 10
do
if [ $var1 -eq 5 ]
then
break
fi
echo "Iteration number: $var1"
done
echo "The for loop is completed"
#!/bin/bash
# breaking out of an outer loop
for (( a = 1; a < 4; a++ ))
do
echo "Outer loop: $a"
for (( b = 1; b < 100; b++ ))
do
if [ $b -gt 4 ]
then
break 2 # 跳出2层循环
fi
echo " Inner loop: $b"
done
done
continue命令
continue n中止某次循环的层级
#!/bin/bash
# using the continue command
for (( var1 = 1; var1 < 15; var1++ ))
do
if [ $var1 -gt 5 ] && [ $var1 -lt 10 ]
then
continue
fi
echo "Iteration number: $var1"
done
13.8 处理循环的输出
可以对循环的输出使用管道或重定向,在done命令之后添加一个处理命令来实现。
#!/bin/bash
# redirecting the for output to a file
for (( a = 1; a < 10; a++ ))
do
echo "The number is $a"
done > test23.txt
echo "The command is finished."
13.9 实例
查找可执行文件
#!/bin/bash
IFS=:
for folder in $PATH
do
echo "$folder"
for file in $folder/*
do
if [ -x $file ]
then
echo " $file"
fi
done
done
创建多个用户账户
#!/bin/bash
# process new user accounts
input="users.csv"
while IFS=',' read -r userid name
do
echo "adding $userid"
useradd -c "$name" -m $userid
done < "$input" # 重定向输入
第14章 处理用户输入
14.1 命令行参数
命令行参数允许在运行脚本时向命令行添加数据。
读取参数
bash shell会将一些称为位置参数(positional parameter)的特殊变量分配给输入到命令行中的所有参数。位置参数变量是标准的数字:$0是程序名,$1是第一个参数,$2是第二个参数,以此类推。
#!/bin/bash
factorial=1
for (( number = 1; number <= $1; number++ )) # $1表示第一个参数
do
factorial=$[ $factorial * $number ]
done
echo The factorial of $1 is $factorial
每个参数都是用空格分隔,如果要在参数值中包含空格,必须要用引号(单引号或双引号均可)。
basename命令会返回不包含路径的脚本名。
测试参数
在使用参数前一定要检查其中是否存在数据
#!/bin/bash
if [ -n "$1" ]
then
echo Hello $1, glad to meet you.
else
echo "Sorry, you did not identify yourself."
fi
14.2 特殊参数变量
参数统计
$#变量含有脚本运行时携带的参数的个数统计。
抓取所有的数据
$*和$@变量可以用来轻松访问所有的参数。
$*将所有参数当做一个单词保存$@将这些参数视为一个整体,可以使用for循环
14.3 移动变量
shift命令能够用来操作命令行参数。
在使用shift命令时,默认情况下它会将每个参数变量向左移动一个位置,变量$3的值会移到$2中,变量$2的值会移到$1中。
#!/bin/bash
echo
count=1
while [ -n "$1" ]
do
echo "Parameter #$count = $1"
coun=$[ $count + 1 ]
shift
done
14.4 处理选项
查找选项
1.处理简单选项
用case语句来判断某个参数是否为选项,比如-a、-b等。
2.分离参数和选项
双破折号(--)用来表明选项列表结束。
#!/bin/bash
while [ -n "$1" ]
do
case "$1" in
-a) echo "Found the -a option" ;;
-b) echo "Found the -b option" ;;
-c) echo "Found the -c option" ;;
--) shift # 匹配到--就break退出循环
break;;
*) echo "$1 is not an option" ;;
esac
shift
done
#
count=1
for param in $@
do
echo "Paramter #$count: $param"
count=$[ $count + 1 ]
done
3.处理带值的参数
#!/bin/bash
echo
while [ -n "$1" ]
do
case "$1" in
-a) echo "Found the -a option";;
-b) param=$2
echo "Found the -b option, with parameter value $param" # 获取指定选项后获取参数
shift;;
--) shift
break;;
*) echo "$1 is not an option";;
esac
shift
done
#
count=1
for param in "$@"
do
echo "Parameter #$count: $param"
count=$[ $count + 1 ]
done
使用getopt命令
getopt命令是一个在处理命令行选项和参数时非常方便的工具,它能够识别命令行参数。
getopt optstring parameters
在optstring中列出脚本中要用到的命令行选项字符,在需要用到参数的选项字符后面加一个冒号:。
例:getopt ab:cd -a -b test1 -cd1 test2 test3打印-a -b test1 -c -d -- test2 test3。
在脚本中使用getopt
#!/bin/bash
set -- $(getopt -q ab:cd "$@") # 将getopt输出到set
echo
while [ -n "$1" ]
...
更高级的getopts
getopts optstring variable
每次调用,只处理命令行上检测到的一个参数,处理完所有的参数之后退出并返回一个大于0的退出状态码。
#!/bin/bash
echo
while getopts :ab:c opt
do
case "$opt" in
a) echo "Found the -a option" ;;
b) echo "Found the -b option, width value $OPTARG";;
c) echo "Found the -c option" ;;
*) echo "Unknown option: $opt";;
esac
done
#
shift $[ $OPTING - 1 ]
#
echo
count=1
for param in "$@"
do
echo "Parameter $count: $param"
count=$[ $count + 1 ]
done
# 这是一个能在所有shell脚本中使用的全功能命令行选项和参数处理工具
getopts命令支持参数值包含空格,支持选项字母和参数值放在一起使用,将未定义的选项统一输出成问号。
14.5 将选项标准化
Linux中常用的标准化命令行选项的含义
| 选项 | 描述 |
|---|---|
| -a | 显示所有对象 |
| -c | 生成一个计数 |
| -d | 指定一个目录 |
| -e | 扩展一个对象 |
| -f | 指定读入数据的文件 |
| -h | 显示命令的帮助信息 |
| -i | 忽略文本大小写 |
| -l | 产生输出的长格式版本 |
| -n | 使用非交互模式(批处理) |
| -o | 将所有输出重定向到的指定的输出文件 |
| -q | 以安静模式运行 |
| -r | 递归地处理目录和文件 |
| -s | 以安静模式运行 |
| -v | 生成详细输出 |
| -x | 排除某个对象 |
| -y | 对所有问题回答yes |
14.6 获取用户的输入
read命令从标准输入(键盘)或另一个文件描述符中接受输入。
基本的读取
#!/bin/bash
echo -n "Enter your name:"
read name
echo "Hello $name"
如果不指定变量,read命令接受到的任何数据都会放进特殊环境变量REPLY中。
| 选项 | 说明 |
|---|---|
| -p | 指定提示符 |
| -t | 指定超时器 |
| -n | 指定字符数 |
| -s | 隐藏数据 |
超时
当计时器超时,read命令会返回一个非零退出状态码。
#!/bin/bash
if read -t 5 -p "Please enter your name: " name
then
echo "Hello $name"
else
echo
echo "Sorry, too slow!"
fi
从文件中读取
read命令可以读取文件,每次读取一行,当文件没有内容时会退出并返回非零状态码。
#!/bin/bash
count=1
cat test.txt | while read line
do
echo "Line $count: $line"
count=$[ $count + 1 ]
done
第15章 呈现数据
15.1 理解输入和输出
标准文件描述符
Linux系统将每个对象当作文件处理,包括输入和输出进程。Linux用文件描述符(file descriptor)来标识每个文件对象。文件描述符是一个非负整数,可以唯一标识会话中打开的文件。每个进程一次最多可以有9个文件描述符。出于特殊目的,bash shell保留了前三个文件描述符(0、1和2)。
| 文件描述符 | 缩写 | 描述 |
|---|---|---|
| 0 | STDIN | 标准输入 |
| 1 | STDOUT | 标准输出 |
| 2 | STDERR | 标准错误 |
1.STDIN
STDIN文件描述符代表shell的标准输入。对终端界面来说,标准输入是键盘。shell从STDIN文件描述符对应的键盘获得输入,在用户输入时处理每个字符。
许多bash命令能接受STDIN的输入,尤其是没有在命令行上指定文件的话,比如cat命令。
2.STDOUT
STDOUT文件描述符代表shell的标准输出。在终端界面上,标准输出就是终端显示器。shell的所有输出(包括shell中运行的程序和脚本)会被定向到标准输出中,也就是显示器。
默认情况下,大多数bash命令会将输出导向STDOUT文件描述符。
shell对错误消息的处理和普通输出是分开的。
3.STDERR
shell通过特殊的STDERR文件描述符来处理错误消息。STDERR文件描述符代表shell的标准错误输出。shell或shell中运行的程序和脚本出错时生成的错误消息都会发送到这个位置。
默认情况下,STDERR和STDOUT都会输出到显示器输出中。
重定向错误
1.只重定向错误
将文件描述符值放在重定向符号前,可以设置重定向的文件描述符。
ls -al badfile 2> test;将错误消息重定向到test文件。
2.重定向错误和数据
如果想重定向错误和正常输出,必须用两个重定向符号。
ls -al test test2 test3 badtest 2> test3 1> test4
&>符号支持将STDERR和STDOUT的输出重定向到同一个输出文件。ls -al test test2 test3 badtest &> test5。
15.2 在脚本重定向输出
临时重定向
将单独的一行输出到STDERR,使用输出重定向将输出信息重定向到STDERR文件描述符,记得在文件描述符数字之前加一个&符号。
#!/bin/bash
echo "This is an error" >&2 # 这一行会被当做STDERR处理
echo "this is normal output"
永久重定向
exec命令告诉shell在脚本执行期间重定向某个特定文件描述符。
#!/bin/bash
exec 1> testout # 脚本中发给STDOUT的所有输出会被重定向到testout文件
echo "This is a test of redirecting all out"
echo "from a script to another file."
echo "without having to redirect every individual line"
15.3 在脚本中重定向输入
#!/bin/bash
exec 0< testfile # 告诉shell应该从文件tesfile中获得输入,而不是STDIN。
count=1
while read line
do
echo "Line #$count: $line"
count=$[ $count + 1 ]
done
这是在脚本中从待处理的文件中读取数据的绝妙方法。
15.4 创建自己的重定向
在shell中最多有9个打开的文件描述符,其他6个均可用作输入或输出重定向。可以将这些文件描述符中的任意一个分配给文件,然后在脚本中使用它们。
创建输出文件描述符
使用exec命令给输出分配文件描述符。
#!/bin/bash
exec 3>test13out
echo "this should display on the monitor"
echo "and this should be stored in the file" >&3 # 这句会输出到test13out
echo "Then this should be back on the monitor"
重定向文件描述符
通过分配另外一个文件描述符给标准文件描述符,可以恢复已重定向的文件描述符。
#!/bin/bash-
exec 3>&1 # 将3文件描述符重定向到1标准输出文件描述符
exec 1>test12out
echo "This should store in the output file"
echo "alone with this line"
exec 1>&3
echo "Now things should be back to normal"
创建输入文件描述符
在重定向到文件之前,先将STDIN文件描述符保存到另外一个文件描述符,然后在读取完文件之后再将STDIN恢复到它原来的位置。
#!/bin/bash
exec 6<&0 # 将0重定向到6
exec 0< testfile # 将testfile的输出重定向到0文件描述符
count=1
while read line
do
echo "Line #$count: $line"
count=$[ $count + 1 ]
done
exec 0<&6
read -p "Are you done now?" answer
case $answer in
Y|y) echo "Goodbye";;
N|n) echo "Sorry, this is then end.";;
esac
关闭文件描述符
要关闭文件描述符,将它重定向到特殊符号&-。
一旦关闭了文件描述符,就不能在脚本中向它写入任何数据,否则会生成错误信息。
#!/bin/bash
exec 3> test17file
echo "This is a test line of data" >&3
exec 3>&-
cat test17file
exec 3> test17file # 关闭文件描述符之后再重新打开会覆盖原来的输出文件
echo "This'll be bad" >&3
15.5 列出打开的文件描述符
**lsof**命令会列出整个Linux系统打开的所有文件描述符。
-p选项指定进程ID,-d选项指定要显示的文件描述符编号,-a选项对其他两个选项的结果执行布尔AND运算,-i:port显示端口号对应的程序。
环境变量
$$可以知道当前的进程PID。

- COMMAND:进程的名称。
- PID:进程的 ID。
- USER:进程所属的用户。
- FD:文件描述符,表示进程打开文件时使用的文件描述符。
- TYPE:文件类型,如 REG(常规文件)、DIR(目录)、CHR(字符设备)、FIFO(命名管道)、IPv4(IPv4 套接字)等。
- DEVICE:设备名称。
- SIZE/OFF:文件的大小或文件读/写指针的偏移量。
- NODE:文件的节点号。
- NAME:文件的名称。
15.6 阻止命令输出
不想显示脚本的输出,可以将STDERR重定向到一个叫做null文件的特殊文件,shell输出到null文件的任何数据都不会保存,全部都被丢弃。null放在/dev/null下。
$ ls -al > /dev/null
$ cat /dev/null # 没有任何输出
使用cat /dev/null > testfile清除文件内容。
15.7 创建临时文件
Linux提供了/tmp目录用于专门存放临时文件,一般在Linux启动时会自动删除/tmp目录下的所有文件。
**mktemp**命令可以在/tmp目录下创建一个唯一的临时文件,它会将文件的读写分配给文件的属主。
创建本地临时文件
使用mktemp命令加上指定文件名模板,就可以在本地目录中创建一个文件。
$ mktemp testing.XXXXXX # 创建的每个文件都是唯一的
$ ls -al testing*
-rw------- 1 parallels parallels 0 Apr 25 07:47 testing.z6tpko
在/tmp目录创建临时文件
-t选项在/tmp目录下创建文件。
$ mktemp -t test.XXXXXX
/tmp/test.HMuGj7
创建临时目录
-d选项创建一个临时目录。
$ mktemp -d dir.XXXXXX
dir.9Wdgh8
#!/bin/bash
# using a temporary directory
tempdir=$(mktemp -d dir.XXXXXX)
cd $tempdir
tempfile1=$(mktemp temp.XXXXXX)
tempfile2=$(mktemp temp.XXXXXX)
exec 7> $tempfile1
exec 8> $tempfile2
echo "Sending data to directory $tempdir"
echo "This is a test line of data for $tempfile1" >&7
echo "This is a test line of data for $tempfile2" >&8
15.8 记录消息
使用**tee**命令将输出同时发送到显示器和日志文件。tee相当于管道的一个T型接口,将STDIN输入的数据同时发往STDOUT和tee命令所指定的文件名。
tee filename
默认情况下,tee命令会覆盖输出的文件内容。
-a选项将数据追加到文件中。
#!/bin/bash
# using the tee command for logging
tempfile=test22file
echo "This is the start of the test" | tee $tempfile
echo "This is the second line of the test" | tee -a $tempfile
echo "This is the end of the test" | tee -a $tempfile
15.9 实例
文件重定向常见于脚本需要读入文件和输出文件时。
#!/bin/bash
# read file and create INSERT statements for MySQL
# 这个脚本使用重定向读取csv并将内容写入数据库
outfile="members.sql"
IFS=","
while read lname fname address city state zip
do
cat >> $outfile << EOF
INSERT INTO members (lname,fname,address,city,state,zip) VALUES ("$lname", "$fname", "$address", "$city", "$state", "$zip");
EOF
done < ${1}
第16章 控制脚本
16.1 处理信号
Linux利用信号与运行在系统中的进程进行通信。
当shell接受到信号时,会将信号传给所有由它启动的进程,以此告知出现的状况。
shell脚本默认情况下会忽略这些信号,这可能会导致不利于脚本的运行,可以通过在脚本中加入识别信号的代码解决这个问题。
生成信号
- SIGHUP (1):当终端连接断开时发送该信号。
- SIGINT (2):当用户在终端上按下CTRL-C时发送该信号。
- SIGQUIT (3):当用户在终端上按下CTRL-\时发送该信号。
- SIGILL (4):当进程执行了非法指令时发送该信号。
- SIGABRT (6):当进程调用abort函数时发送该信号。
- SIGFPE (8):当进程执行了非法算术操作时发送该信号。
- SIGKILL (9):强制终止进程。
- SIGSEGV (11):当进程试图访问不属于自己的内存时发送该信号。
- SIGPIPE (13):当进程向一个没有读端的管道写数据时发送该信号。
- SIGALRM (14):当alarm函数设置的时间到达时发送该信号。
- SIGTERM (15):请求终止进程。
1.中断进程
Ctrl+C组合键会生成SIGINT信号,停止shell中当前运行的进程。
2.暂停进程
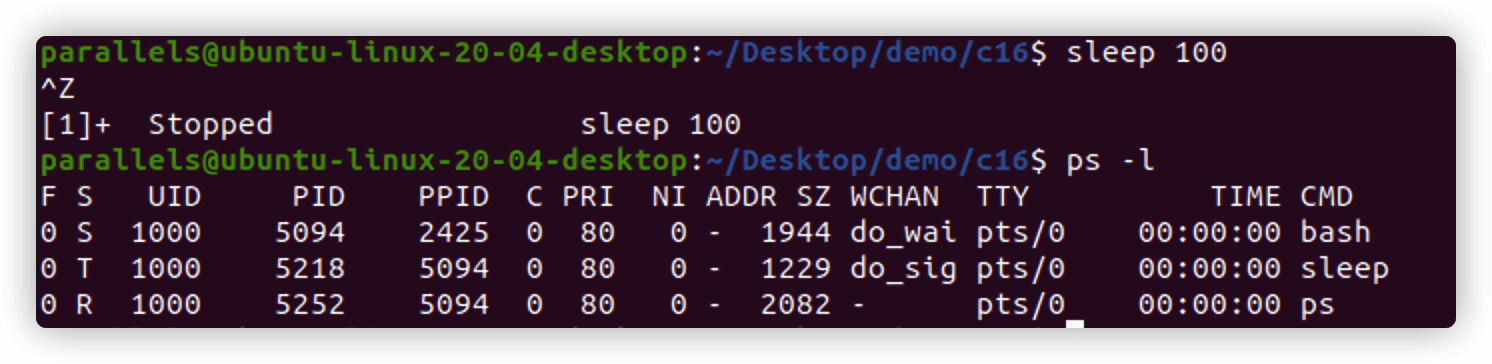
Ctrl+Z组合键会生成SIGTSTP信号,停止shell中运行的任何进程。停止进程会让程序继续保留在内存中,并能从上次停止的位置继续运行。
shell中运行的每个进程被称为作业,shell会为每个作业分配唯一的作业号。
当终止作业(使用kill命令终止进程)时,最开始不会得到任何回应,当你做了能产生shell提示符的操作(比如按回车键),就会看到一条显示作业被终止的消息。
捕获信号
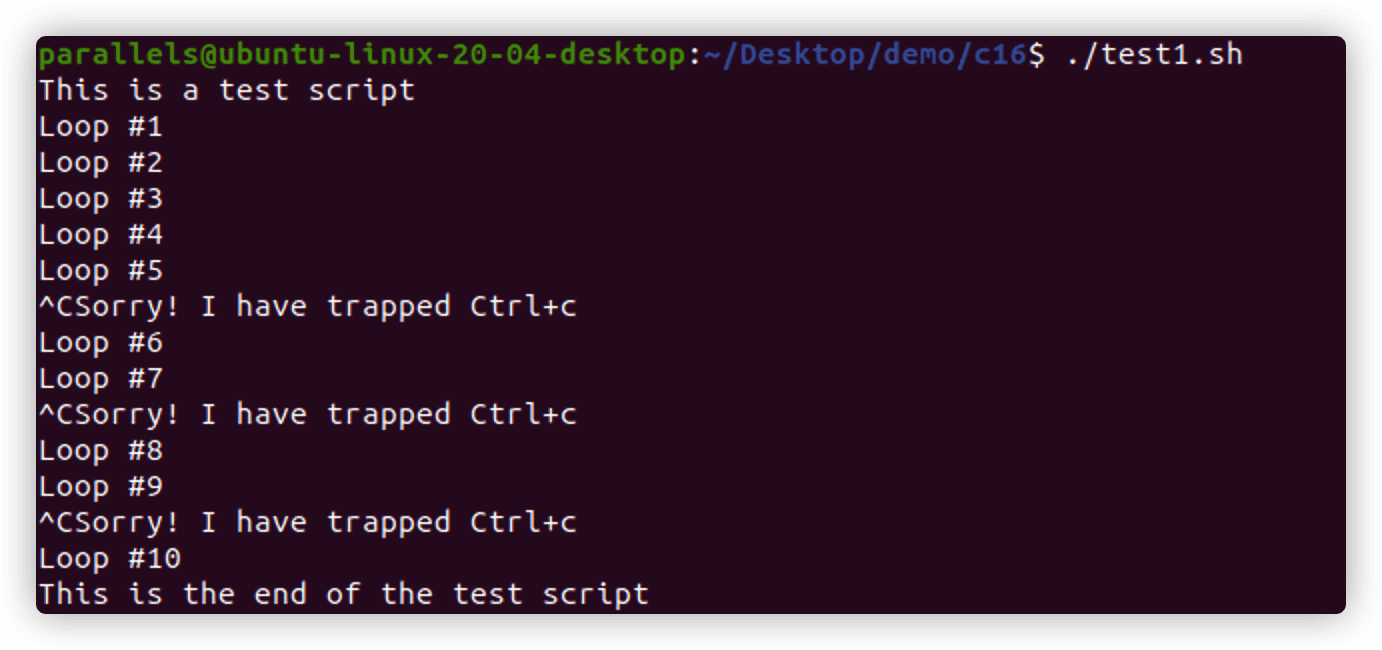
**trap**命令指定shell脚本要监看并从shell中拦截的Linux信号。
trap commands signalscommands代表shell要执行的命令,signals代表要捕获的信号。
#!/bin/bash
trap "echo 'Sorry! I have trapped Ctrl+c'" SIGINT # 捕获SIGNIT信号
echo This is a test script
count=1
while [ $count -le 10 ]
do
echo "Loop #$count"
sleep 1
count=$[ $count + 1 ]
done
echo "This is the end of the test script"
捕获脚本退出
要捕获脚本退出,只需在trap命令后面加上EXIT信号。
#!/bin/bash
trap "echo Goodbye..." EXIT
sleep 2
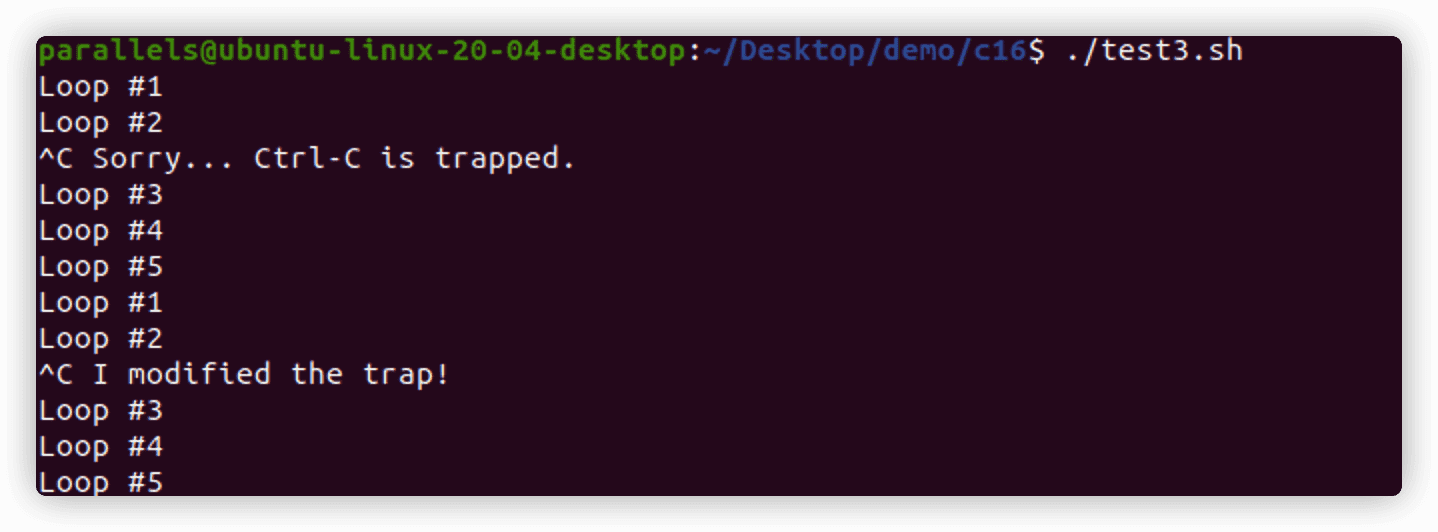
修改或移除捕获
要想在脚本中的不同位置进行不同的捕获处理,只需重新使用带有新选项的trap命令。
#!/bin/bash
trap "echo ' Sorry... Ctrl-C is trapped.'" SIGINT
count=1
while [ $count -le 5 ]
do
echo "Loop #$count"
sleep 1
count=$[ $count + 1 ]
done
trap "echo ' I modified the trap!'" SIGINT
count=1
while [ $count -le 5 ]
do
echo "Loop #$count"
sleep 1
count=$[ $count + 1 ]
done
也可以删除已设置好的捕获,只需在trap命令加上两个破折号即可,trap -- SIGINT。
16.2 以后台模式运行脚本
所有的进程不会都显示在终端显示器上,这种进程被称为后台(background)运行进程。在后台模式中,进程运行时不会和终端会话上的STDIN、STDOUT以及STDERR关联。
后台运行脚本
在运行脚本后面加个&符号,就可以以后台模式运行脚本。

方括号中的数字是指后台进程的作业号,下一个数是PID。
当进程以后台模式运行时,它仍会使用终端显示器来显示STDOUT和STDERR消息,这会导致显示信息错乱,最后使用重定向处理STDOUT和STDERR。
运行多个后台作业
在终端运行多个作业,如果终端退出,那么后台进程随之也会跟着退出。
16.3 在非控制台下运行脚本
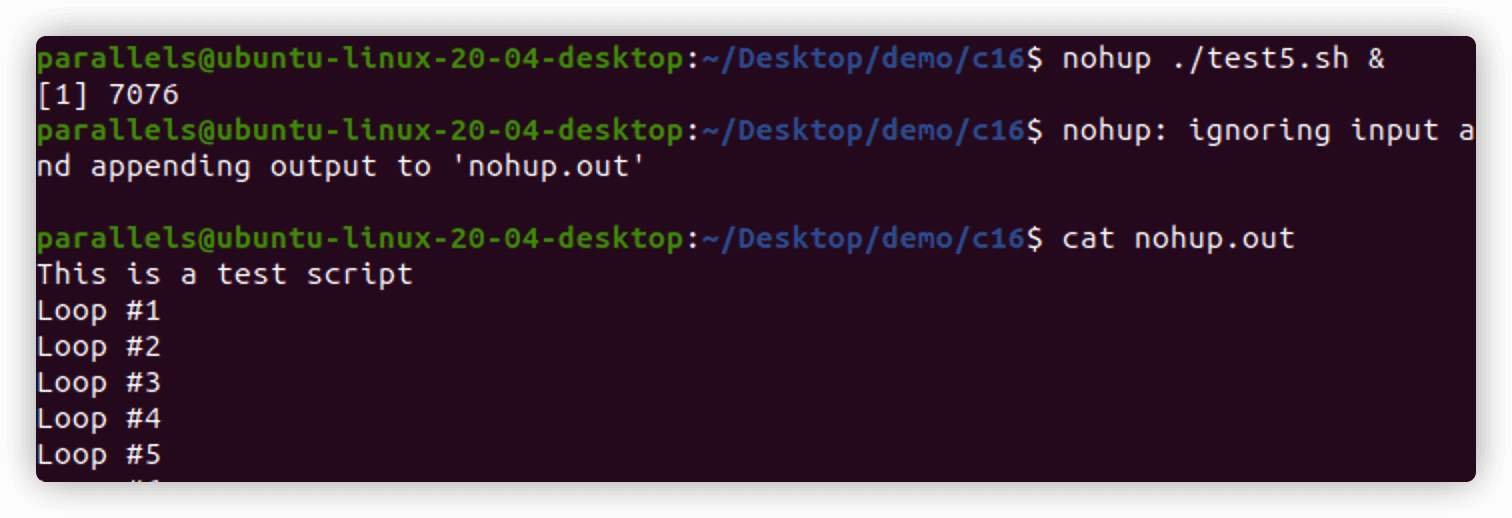
**nohup**命令运行另外一个命令来阻断所有发送给该进程的SIGHUP信号,从而达到阻止进程退出。
由于nohup命令解除终端与进程的关联,进程不会与STDOUT和STDERR联系在一起,它会将STDOUT和STDERR消息重定向到一个名为nohup.out的文件中。
16.4 作业控制
可以向停止的进程发送一个SIGCONT信号让其重启。
启动、停止、终止以及恢复作业的这些功能统称为作业控制。
查看作业
**jobs**命令查看正在处理的作业。

| 参数 | 描述 |
|---|---|
| -l | 列出进程的PID以及作业号 |
| -n | 只列出上次shell发出的通知后改变了状态的作业 |
| -p | 只列出作业的PID |
| -r | 只列出运行中的作业 |
| -s | 只列出已停止的作业 |
上面显示的+加号会被当做默认作业。在使用作业控制命令时,如果未在命令行指定任何作业号,该作业会被当成作业控制命令的操作对象。
当前的默认作业完成处理后,带减号-的作业称为下一个默认作业。任何时候都只有一个带加号的作业和一个带减号的作业,不管shell中有多少个正在运行的作业。
重启停止的作业
可以将已停止的作业作为前台进程或后台进程重启。
**bg**命令以后台模式重启作业。
如果有多个作业,在bg命令后加上作业号。
**fg**命令以前台模式重启作业。
16.5 调整谦让度
在多任务操作系统(如Linux)中,内核负责将CPU时间分配给系统上运行的每个进程。调度优先级(scheduling priority)是内核分配给进程的CPU时间。在Linux中,由shell启动的所有进程的调度优先级默认相同。
调度优先级是个整数,从-20(最高优先级)到+19(最低优先级)。默认情况下,bash shell以优先级0来启动所有进程。
nice命令
**nice**命令设置启动时的调度优先级。
-n选项指定优先级级别运行。
nice命令阻止普通系统用户来提高命令的优先级。提高优先优先级时,-n选项不是必须的。
renice命令
**renice**命令可以改变已运行进程的优先级。
例:renice -n 10 -p 15961将PID为15961的进程的优先级调整为-10。
限制:
- 只能对属于你的进程执行renice;
- 只能通过renice降低进程的优先级;
- root用户可以通过renice来任意调整进程的优先级。
16.6 定时运行作业
用at命令来计划执行作业
**at**命令允许指定何时运行脚本。at命令会将作业提交到队列中,指定shell何时运行该作业。at的守护进程atd会以后台模式运行,检查作业队列来运行作业。
atd守护进程会检查系统上的一个特殊目录(通常位于/var/spool/at)来获取用at命令提交的作业。默认情况下,atd守护进程会每60秒检查一下这个目录。
1.at命令的格式
at [-f filename] time
默认情况下,at命令会将STDIN的输入放到队列中。
time参数的时间格式:
- 标准的小时和分钟格式,比如10:15。
- AM/PM指示符,比如10:15 PM。
- 特定可命名时间,比如now、noon、midnight或者teatime(4PM)。
- 标准日期格式,比如MMDDYY、MM/DD/YY或DD.MM.YY。
- 文本日期,比如Jul 4或Dec 25。
- 时间增量
- 当前时间+25min
- 明天10:15 PM
- 10:15+7天
当使用at命令时,该作业会被提交到作业队列(job queue)。针对不同优先级,存在26中不同的作业队列,作业队列通常用小写字母a~z和大写字母A~Z来指代。作业队列的字母排序越高,作业运行的优先级越低。默认情况下作业会被提交到a作业队列中。
-q选择指定不同的队列字母。
-f选项指定使用哪个脚本文件。
2.获取作业的输出
at命令默认使用sendmail应用程序来将STDOUT和STDERR的输出发送到邮件。
使用at命令建议将STDOUT和STDERR进行重定向处理。
-M选项屏蔽作业产生的输出信息。
3.列出等待的作业
**atq**命令查看系统中有哪些作业在等待。
4.删除作业
**atrm**命令删除等待中的作业。
安排需要定期执行的脚本
Linux系统使用cron程序来安排要定期执行的作业。cron程序会在后台运行并检查一个特殊的表(cron时间表),以获知已安排执行的作业。
1.cron时间表
cron时间表采用一种特别的格式来指定作业何时运行:
min hour dayofmonth month dayofweek command
cron时间表允许你用特定值、取值范围(比如1~5)或者是通配符来指定条目。
例:15 10 * * * command 每天的10:15运行一个命令。
2.构建cron时间表
每个系统用户(包括root用户)都可以用自己的cron时间表来运行安排好的任务。
**crontab**命令处理cron时间表。
-l选项列出已有的时间表。
用户的cron时间表文件默认不存在,可以通过-e选项为cron时间表添加条目,crontab命令会启动一个文本编辑器,输入相应的格式。
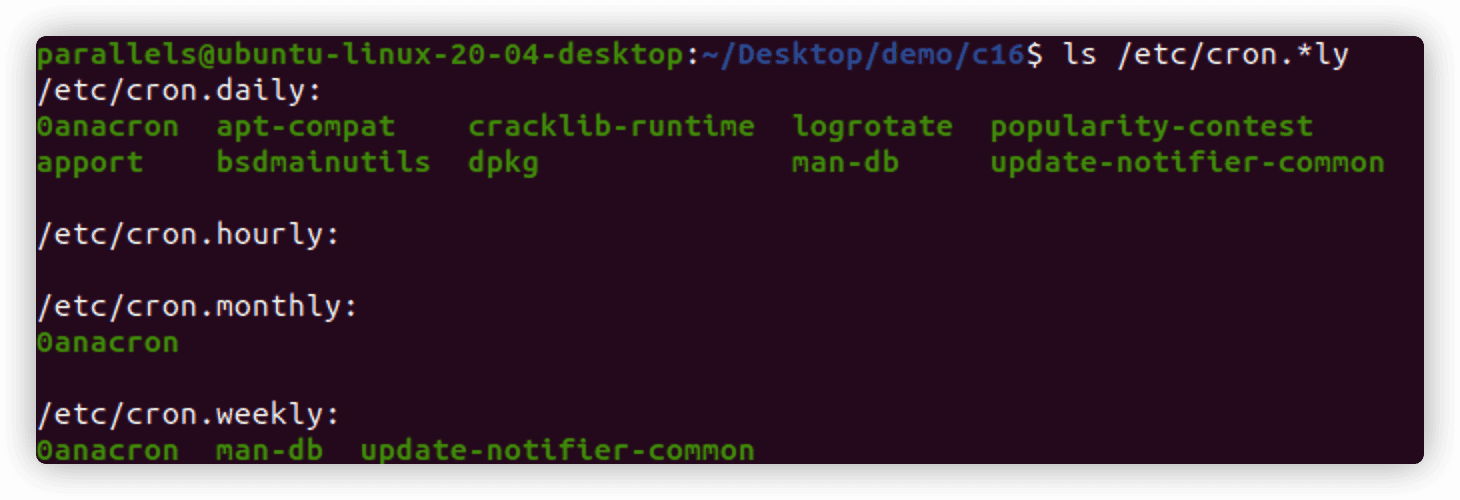
3.浏览cron目录
如果创建的脚本对精确的执行时间要求不高,用预配置的cron脚本目录会更方便。有4个基本目录:hourly、daily、monthly和weekly。
如果脚本需要每天运行一次,只要将脚本复制到daily目录,cron就会每天执行它。
4.anacron程序
cron程序的唯一问题是它假定Linux系统是7×24小时运行的。
如果某个作业在cron时间表中安排运行的时间已到,但这时候Linux系统处于关机状态,那么这个作业不会被执行,当系统开机时,cron程序不会再去执行那些错过的作业。anacron程序可以解决这个问题。
如果anacron知道某个作业错过了执行时间,它会尽快运行该作业。这个功能常用于进行常规日志维护的脚本。
anacron只会处理位于cron目录的程序,比如/etc/cron.monthly。它用时间戳来决定作业是否在正确的计划间隔内运行。每个cron目录都有个时间戳文件,该文件位于/var/spool/anacron。
anacron程序使用自己的时间表(/etc/anacrontab)来检查作业目录。格式:period delay identifier command。anacron不会运行小于一天的脚本。
使用新shell启动脚本
每次启动一个新shell时,bash shell都会运行.bashrc文件。
如果你需要一个脚本在两个时刻都得以运行,可以把这个脚本放进该文件中。
第三部分 高级shell脚本编程
第17章 创建函数
17.1 基本的脚本函数
创建函数
# 第一种定义方式
function name {
commands
}
# 第二种定义方式
name() {
commands
}
使用函数
#!/bin/bash
function func1 {
echo "This is an example of a funtion"
}
count=1
while [ $count -le 5 ]
do
func1 # 函数调用
count=$[ $count + 1 ]
done
echo "This is the end of the loop"
func1
echo "Now this is the end of the script"
17.2 返回值
bash shell会把函数当作一个小型脚本,运行结束时会返回一个退出状态码,有3种不同的方法来为函数生成退出状态码。
默认退出状态码
默认情况下,函数的退出状态码是函数中最后一条命令返回的退出状态码。在函数执行结束后,可以用标准变量$?来确定函数的退出状态码。
#!/bin/bash
func1() {
echo "trying to display a none-existent file"
ls -l directory
}
echo "testing the function:"
func1
echo "The exit status is: $?"
# testing the function:
# trying to display a none-existent file
# ls: cannot access 'badfile': No such file or directory
# The exit status is: 2
使用return命令
**return**命令指定一个整数值来定义函数的退出状态码。
#!/bin/bash
function db1 {
read -p "Enter a value: " value
echo "doubling the value"
return $[ $value * 2 ]
}
db1
echo "The new value is $?"
- 函数一结束就取返回值;
- 退出状态码必须是0~255。
$?变量会返回执行的最后一条命令的退出状态码。
使用函数输出
#!/bin/bash
function db1 {
read -p "Enter a value: " value
echo $[ $value * 2 ]
}
result=$(db1) # 将函数输出赋值给$result
echo "The new value is $result"
通过这种方式,你还可以返回浮点值和字符串值,这是一种获取函数返回值的强大方法。
17.3 在函数中使用变量
向函数传递参数
函数使用标准的参数环境变量来表示命令行上传给函数的参数($1、$2...)。
func1 $value1 10通过将参数和函数放在同一行进行函数传参。
在函数中处理变量
函数分为全局变量和局部变量。
#!/bin/bash
function dbl {
value=$[ $value * 2 ] # 全局变量值会被改变
}
read -p "Enter a value: " value
dbl
echo "The new value is: $value"
局部变量
在变量声明前面加上local关键字可实现局部变量。local temp。
#!/bin/bash
function func1 {
local temp=$[ $value + 5 ] # 局部变量
result=$[ $temp * 2 ]
}
temp=4
value=6
func1
echo "The result is $result"
if [ $temp -gt $value ]
then
echo "temp is larger"
else
echo "temp is smaller" # 打印这句
fi
17.4 数组变量和函数
向函数传数组参数
#!/bin/bash
function addarray {
local sum=0
local newarray
newarray=($(echo "$@")) # 通过特殊变量还原数组值
for value in ${newarray[*]}
do
sum=$[ $sum + $value ]
done
echo $sum
}
myarray=(1 2 3 4 5)
echo "The original array is: ${myarray[*]}"
arg1=$(echo ${myarray[*]})
result=$(addarray $arg1) # arg1保存数组值 1 2 3 4 5
echo "The result is $result"
从函数返回数组
#!/bin/bash
# returning an array value
function arraydblr {
local origarray
local newarray
local elements
local i
origarray=($(echo "$@"))
newarray=($(echo "$@"))
elements=$[ $# - 1 ]
for (( i = 0; i <= $elements; i++ ))
{
newarray[$i]=$[ ${origarray[$i]} * 2 ]
}
echo ${newarray[*]} # 生成数组输出
}
myarray=(1 2 3 4 5)
echo "The original array is: ${myarray[*]}"
arg1=$(echo ${myarray[*]})
result=($(arraydblr $arg1))
echo "The new array is: ${result[*]}"
17.5 函数递归
#!/bin/bash
# using recursion
function factorial {
if [ $1 -eq 1 ]
then
echo 1
else
local temp=$[ $1 - 1 ]
local result=$(factorial $temp)
echo $[ $result * $1 ]
fi
}
read -p "Enter value: " value
result=$(factorial $value)
echo "The factorial of $value is: $result"
17.6 创建库
bash shell允许创建函数库文件,在多个脚本中引用该库文件。默认情况下,脚本运行会创建新的shell,会造成当前shell无法使用脚本的变量。
**source**命令使脚本在当前shell上下文中执行,从而达到可以使用脚本变量的效果。它有个快捷的别名,点操作符(dot operator),比如:. ./myfuncs。
#!/bin/bash
source ./myfuncs.sh # 该脚本的函数都可以在当前上下文下使用
value1=10
value2=5
result1=$(addem $value1 $value2)
result2=$(multem $value1 $value2)
result3=$(divem $value1 $value2)
echo "The result of adding them is: $result1"
echo "The result of multiplying them is: $result2"
echo "The result of dividing them is: $result3"
17.7 在命令行上使用函数
在命令行上创建函数
shell会解释用户输入的命令,因此可以直接在命令行上定义一个函数。
在.bashrc文件中定义函数
在命令行上直接定义shell函数的缺点是一旦退出shell函数就消失了。
.bashrc在每次bash shell启动时都会运行它,直接在.bashrc文件中定义好函数,下次启动shell或者使用source命令就可以直接使用了。
17.8 实例
shtool库提供了一些简单的shell脚本函数,可以用来完成日常的shell功能,例如处理临时文件和目录或者格式化输出显示。
下载及安装
下载.tar.gz文件并在主目录使用tar命令提取。
构建库
shtool文件必须针对特定的Linux环境进行配置。配置工作使用标准的configure和make命令。
$ ./configure
$ make
configure命令去检查构建shtool库文件所必须的软件,一旦发现所需的工具,会使用工具路径修改配置文件。
make命令负责构建shtool库文件。直接输入make会测试这个库文件中所有的函数,测试通过之后,使用sudo make install将库安装到全局下。
shtool库函数
具体函数可去官网查。
使用格式:shtool [options] [function [options] [args]]
第四部分 创建实用的脚本
第24章 编写简单的脚本实用工具
24.1 归档
为了防止数据丢失,最好定时进行备份(归档)。
归档数据文件
使用tar命令创建工作目录归档文件。tar -zcf xxx.tar.gz xx/xxx/*.*将xx/xxx目录下的所有文件归档到一个文件中并只用gzip压缩。
按小时归档数据:
#!/bin/bash
#
# Hourly_Archive - Every hour create an archive
#########################################################
#
# Set Configuration File
#
config_file=/archive/hourly/Files_To_Backup.txt
#
# Set Base Archive Destination Location
#
basedest=/archive/hourly
#
# Gather Current Day, Month & Time
#
day=$(date +%d)
month=$(date +%m)
time=$(date +%H%M)
#
# Create Archive Destination Directory
#
mkdir -p $basedest/$month/$day
#
# Build Archive Destination File Name
#
destination=$basedest/$month/$day/archive$time.tar.gz
#
######### Main Script #########################
#
# Check Backup Config file exists
#
if [ -f $config_file ] # Make sure the config file still exists.
then # If it exists, do nothing but continue on.
echo
else # If it doesn't exist, issue error & exit script.
echo
echo "$config_file does not exist."
echo "Backup not completed due to missing Configuration File"
echo
exit
fi
#
# Build the names of all the files to backup
#
file_no=1 # Start on Line 1 of Config File.
exec < $config_file # Redirect Std Input to name of Config File
#
read file_name # Read 1st record
#
while [ $? -eq 0 ] # Create list of files to backup.
do
# Make sure the file or directory exists.
if [ -f $file_name -o -d $file_name ]
then
# If file exists, add its name to the list.
file_list="$file_list $file_name"
else
# If file doesn't exist, issue warning
echo
echo "$file_name, does not exist."
echo "Obviously, I will not include it in this archive."
echo "It is listed on line $file_no of the config file."
echo "Continuing to build archive list..."
echo
fi
#
file_no=$[$file_no + 1] # Increase Line/File number by one.
read file_name # Read next record.
done
#
#######################################
#
# Backup the files and Compress Archive
#
echo "Starting archive..."
echo
#
tar -czf $destination $file_list 2> /dev/null
#
echo "Archive completed"
echo "Resulting archive file is: $destination"
echo
#
exit
24.2 管理用户账户
需要的功能
删除账户的所需的4个步骤:
- 获取正确的待删除用户账户名;
- 杀死正在系统上运行的属于该账户的进程;
- 确认系统中属于该账户的所有文件;
- 删除该用户账户
**xargs**命令可以构建并执行来自标准输入STDIN的命令,它非常适合用在管道的末尾处。
**find**命令查找文件系统的文件。
脚本实现
#!/bin/bash
#
#Delete_User - Automates the 4 steps to remove an account
#
###############################################################
# Define Functions
#
#####################################################
function get_answer {
#
unset answer
ask_count=0
#
while [ -z "$answer" ] #While no answer is given, keep asking.
do
ask_count=$[ $ask_count + 1 ]
#
case $ask_count in #If user gives no answer in time allotted
2)
echo
echo "Please answer the question."
echo
;;
3)
echo
echo "One last try...please answer the question."
echo
;;
4)
echo
echo "Since you refuse to answer the question..."
echo "exiting program."
echo
#
exit
;;
esac
#
if [ -n "$line2" ]
then #Print 2 lines
echo $line1
echo -e $line2" \c"
else #Print 1 line
echo -e $line1" \c"
fi
#
# Allow 60 seconds to answer before time-out
read -t 60 answer
done
# Do a little variable clean-up
unset line1
unset line2
#
} #End of get_answer function
#
#####################################################
function process_answer {
#
answer=$(echo $answer | cut -c1)
#
case $answer in
y|Y)
# If user answers "yes", do nothing.
;;
*)
# If user answers anything but "yes", exit script
echo
echo $exit_line1
echo $exit_line2
echo
exit
;;
esac
#
# Do a little variable clean-up
#
unset exit_line1
unset exit_line2
#
} #End of process_answer function
#
##############################################
# End of Function Definitions
#
############# Main Script ####################
# Get name of User Account to check
#
echo "Step #1 - Determine User Account name to Delete "
echo
line1="Please enter the username of the user "
line2="account you wish to delete from system:"
get_answer
user_account=$answer
#
# Double check with script user that this is the correct User Account
#
line1="Is $user_account the user account "
line2="you wish to delete from the system? [y/n]"
get_answer
#
# Call process_answer funtion:
# if user answers anything but "yes", exit script
#
exit_line1="Because the account, $user_account, is not "
exit_line1="the one you wish to delete, we are leaving the script..."
process_answer
#
################################################################
# Check that user_account is really an account on the system
#
user_account_record=$(cat /etc/passwd | grep -w $user_account)
#
if [ $? -eq 1 ] # If the account is not found, exit script
then
echo
echo "Account, $user_account, not found. "
echo "Leaving the script..."
echo
exit
fi
#
echo
echo "I found this record:"
echo $user_account_record
echo
#
line1="Is this the correct User Account? [y/n]"
get_answer
#
#
# Call process_answer function:
# if user answers anything but "yes", exit script
#
exit_line1="Because the account, $user_account, is not "
exit_line2="the one you wish to delete, we are leaving the script..."
process_answer
#
##################################################################
# Search for any running processes that belong to the User Account
#
echo
echo "Step #2 - Find process on system belonging to user account"
echo
#
ps -u $user_account > /dev/null #List user processes running.
case $? in
1) # No processes running for this User Account
#
echo "There are no processes for this account currently running."
echo
;;
0) # Processes running for this User Account.
# Ask Script User if wants us to kill the processes.
#
echo "$user_account has the following process(es) running:"
ps -u $user_account
#
line1="Would you like me to kill the process(es)? [y/n]"
get_answer
#
answer=$(echo $answer | cut -c1)
#
case $answer in
y|Y) # If user answers "yes",
# kill User Account processes.
#
echo
echo "Killing off process(es)..."
#
# List user process running code in command_1
command_1="ps -u $user_account --no-heading"
#
# Create command_3 to kill processes in variable
command_3="xargs -d \\n /usr/bin/sudo /bin/kill -9"
#
# Kill processes via piping commands together
$command_1 | gawk '{print $1}' | $command_3
#
echo
echo "Process(es) killed."
;;
*) #If user answers anything but "yes", do not kill.
echo
echo "Will not kill process(es)."
;;
esac
;;
esac
#################################################################
# Create a report of all files owned by User Account
#
echo
echo "Step #3 - Find files on system belonging to user account"
echo
echo "Creating a report of all files owned by $user_account."
echo
echo "It is recommended that you backup/archive these files,"
echo "and then do one of two things:"
echo " 1) Delete the files"
echo " 2) Change the files' ownership to a current user account."
echo
echo "Please wait. This may take a while..."
#
report_date=$(date +%y%m%d)
report_file="$user_account"_Files_"$report_date".rpt
#
find / -user $user_account > $report_file 2>/dev/null
#
echo
echo "Report is complete."
echo "Name of report: $report_file"
echo -n "Location of report: "; pwd
echo
####################################
# Remove User Account
echo
echo "Step #4 - Remove user account"
echo
#
line1="Do you wish to remove $user_account's account from system? [y/n]"
get_answer
#
# Call process_answer function:
# if user answers anything but "yes", exit script
#
exit_line1="Since you do not wish to remove the user account,"
exit_line2="$user_account at this time, exiting the script..."
process_answer
#
userdel $user_account #delete user account
echo
echo "User account, $user_account, has been removed"
echo
#
exit